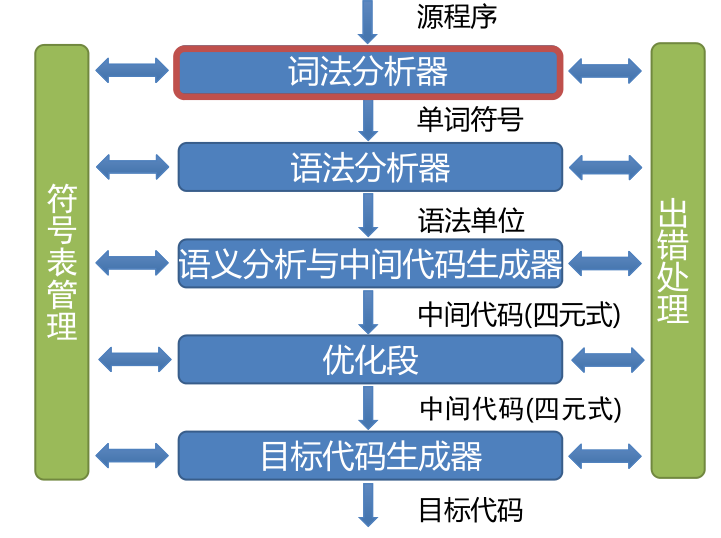
编译程序总框
词法分析器的设计
词法分析的任务:
从左至右逐个字符地对源程序进行扫描,产生一个个单词符号,
词法分析器(Lexical Analyzer):扫描器(Scanner),执行词法分析的程序
功能:输入源程序、输出单词符号
单词符号的种类:
-
基本字:如 begin,repeat,for,…
-
标识符:用来表示各种名字,如变量名、数组名和过程名
-
常数:各种类型的常数
-
运算符:+,-,*,/,…
-
界符:逗号、分号、括号和空白
-
输出的单词符号的表示形式
- (单词种别,单词自身的值)
-
单词种别通常用整数编码表示
- 若一个种别只有一个单词符号,则种别编码就代表该单词符号。假定基本字、运算符和界符都是一符一种。
- 若一个种别有多个单词符号,则对于每个单词符号,给出种别编码和自身的值。
- 标识符单列一种;标识符自身的值表示成按机器字节划分的内部码
- 常数按类型分种;常数的值则表示成标准的二进制形式
词法分析作为一个独立的阶段: 结构简洁、清晰和条理化,有利于集中考虑词法分析一些枝节问题,但不一定不作为单独的一遍,将其处理为一个子程序
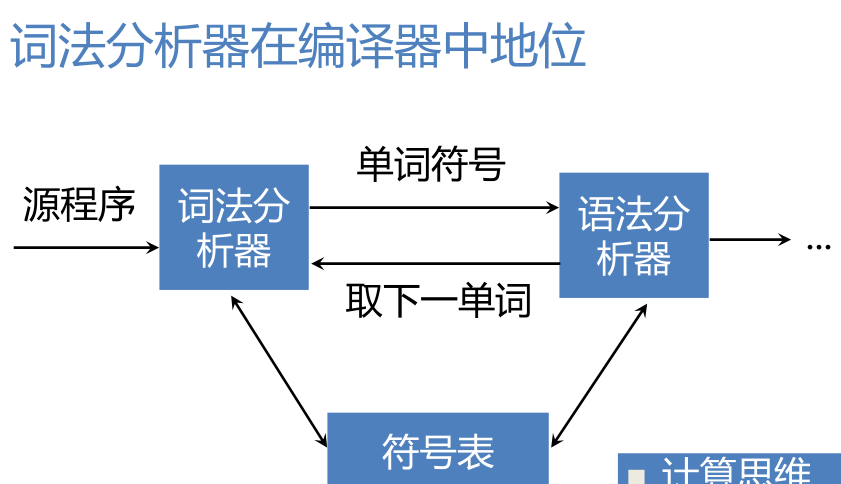
词法分析器的结构


单词符号的识别:超前搜索
标识符识别:字母开头的字母数字串,后跟界符或算符
常数识别:识别出算术常数并将其转变为二进制内码表示
算符和界符的识别:把多字符组成的算符和界符拼合成一个单词符号
几点限制——不必使用超前搜索
- 所有基本字都是保留字;用户不能用它们作自己的标识符
- 基本字作为特殊的标识符来处理,使用保留字表
- 如果基本字、标识符和常数(或标号)之间没有确定的运算符或界符作间隔,则必须使用一个空白符作间隔
状态转换图
状态转换图是一张有限方向图,结点代表状态,用圆圈表示,状态之间用箭弧连结,箭弧上的标记(字符)代表射出结状态下可能出现的输入字符或字符类,一张转换图只包含有限个状态,其中有一个为初态,至少要有一个终态,状态转换图可用于识别(或接受)一定的字符串若存在一条从初态到某一终态的道路,且这条路上所有弧上的标记符连接成的字等于α,则称α被该状态转换图所识别(接受)

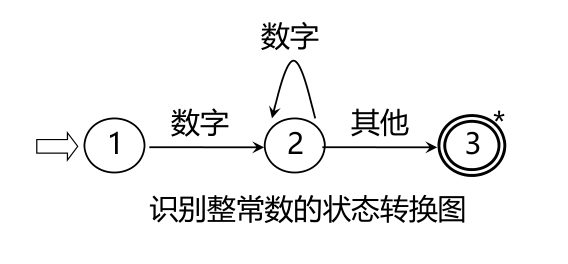
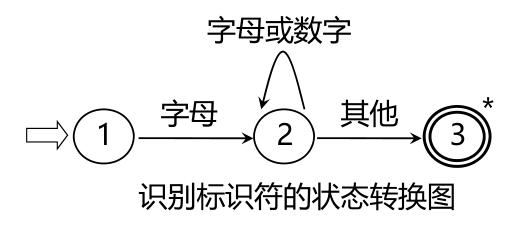
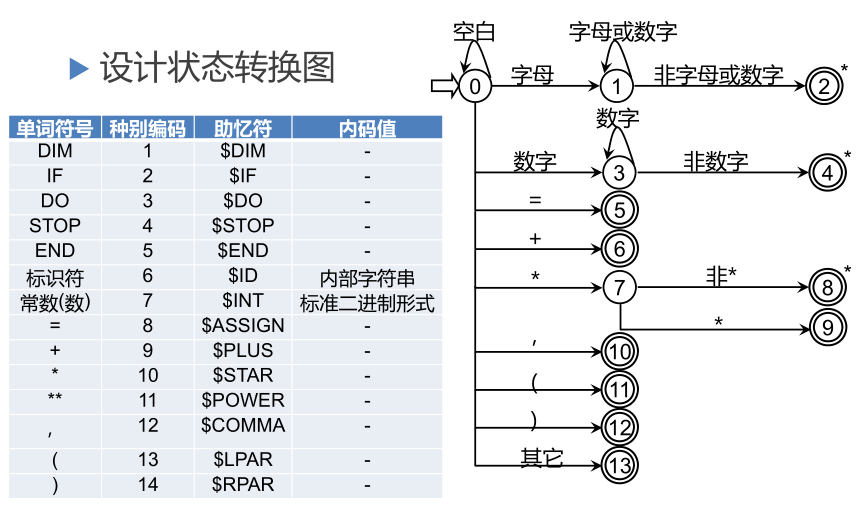
状态转换图的实现
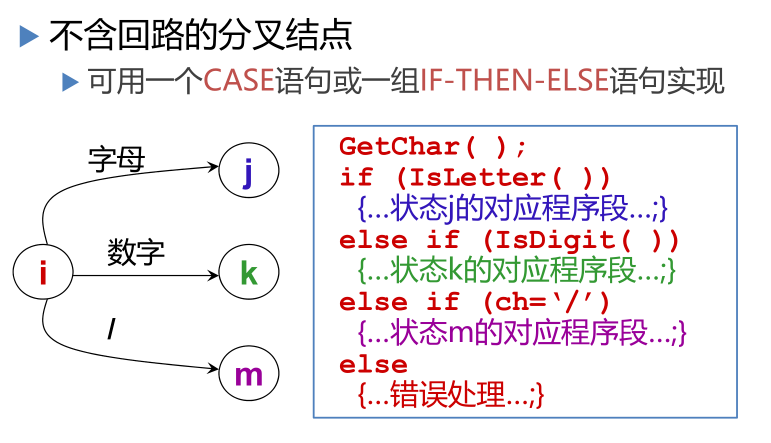
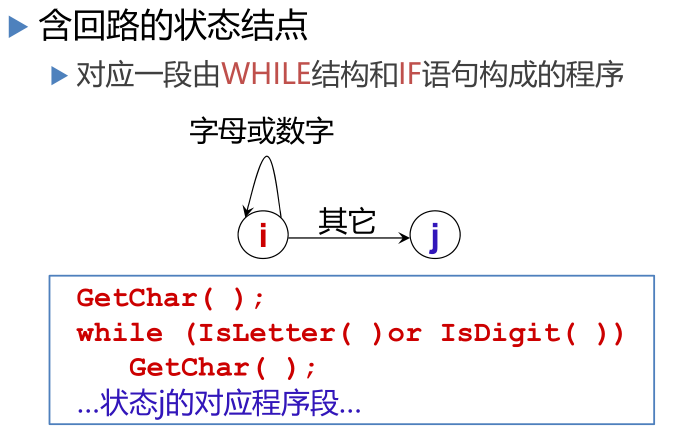

全局变量与过程
- ch 字符变量,存放最新读入的源程序字符
- strToken 字符数组,存放构成单词符号的字符串
- GetChar 子程序过程,把下一个字符读入到 ch 中
- GetBC 子程序过程,跳过空白符,直至 ch 中读入一非空白符
- Concat 子程序,把ch中的字符连接到 strToken
- IsLetter和 IsDisgital 布尔函数,判断ch中字符是否为字母和数字
- Reserve 整型函数,对于 strToken 中的字符串查找保留字表,若它是保留字则给出它的编码,否则回送0
- Retract 子程序,把搜索指针回调一个字符位置
- InsertId 整型函数,将strToken中的标识符插入符号表,返回符号表指针
- InsertConst 整型函数过程,将strToken中的常数插入常数表,返回常数表指针
词法分析器的实现
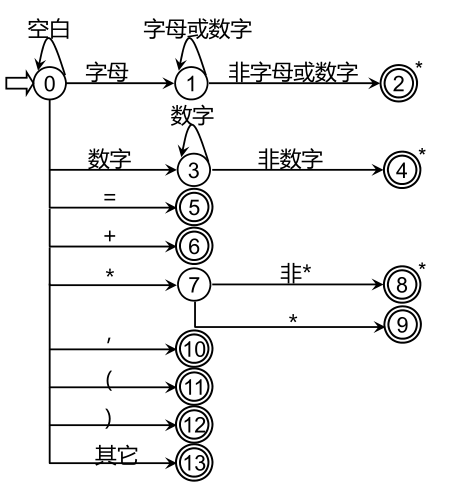



将状态图的代码一般

变量curState用于保存现有的状态,用二维数组表示状态图:stateTrans[state][ch]
