Sleuth是 springcloud 分布式跟踪解决方案。
Sleuth 术语:
跨度(span ) :Sleuth 的基本工作单元,他用一个64位的id唯一标识。出ID外,span还包含 其他的数据,如 描述,时间戳事件,键值对注解等,spanid span父ID等。
trace 跟踪:一组span组成的树状结构称为 trace。
annotation 标注:
cs 客户端发送
SR 服务端接收
SS 服务端发送
CR 客户端接收
整合Sleuth:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency>
这就整合好了sleuth.
整合ZIPKIN
zipkin 的作用是 Twitter 开源分布式跟踪系统,主要用来收集系统的时序数据,从而跟踪系统的调用问题。
zip的下载与搭建
http://www.imooc.com/article/291572
增加 pom.xml
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>
这时候可以去掉 前面的 Sleuth依赖,应为这个已经包含了 sleuth 的依赖。

修改 application.properties 增加配置:
# 调用链配置。 spring.zipkin.base-url=http://localhost:9411/ spring.zipkin.discoveryClientEnabled=false spring.sleuth.sampler.probability=1
1.zipkin服务器地址
2.采样率 这里设置为1,在生产环境中这个 需要设置低一些,比如为0.1 就是十次采样一次。
测试访问一次服务后,查看zipkin。
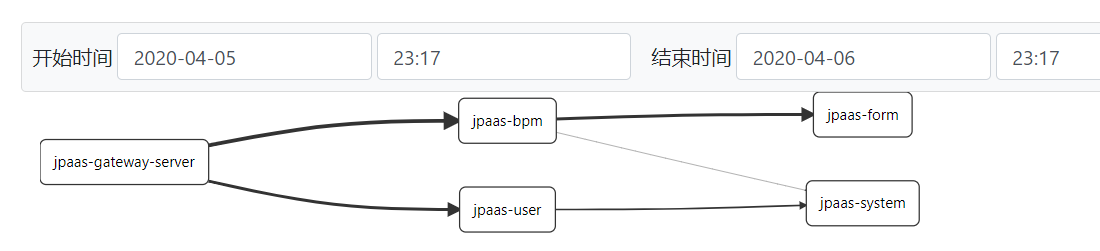
通过调用链 可以分析调用的问题。
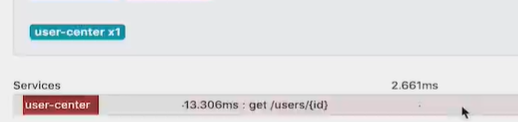
如果调用出现红色,那么这个表示出错,就需要分析原因了。
整合 zipkin nacos 报错解决