1.安装
1.1下载最新的 elasticsearch-6.5.4.tar.gz
1.2解压
tar -zxvf elasticsearch-6.5.4.tar.gz
1.3 创建用户
elastic默认不能在root用户下运行,所以需要专门的用户运行。
groupadd elsearch
useradd elsearch -g elsearch -p elasticsearch
chown -R elsearch:elsearch elasticsearch-6.5.4.
1.4 运行
su elsearch
./bin/elasticsearch
2.配置
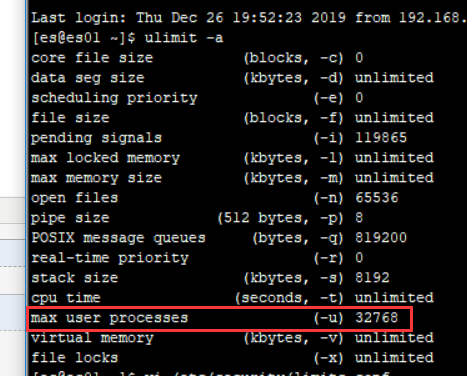
1.编辑配置文件 /etc/security/limits.conf
在最后增加
elsearch - nofile 65536
elsearch soft nproc 32768
elsearch hard nproc 65536
elsearch 为启动elasticsearch 的用户
可以使用 elsearch 用户登录 使用 ulimit -a 命令查看是否生效。
2.编辑/etc/sysctl.conf 文件
增加配置
vm.max_map_count=262144
并执行命令 sysctl -p
减少内存交换,紧急情况仍然允许交换。
vm.swappiness=1
3.在 elasticsearcm.yml 中配置
bootstrap.memory_lock: true
防止elastic的内存被交换出去。
配置完后可以通过
GET _nodes?filter_path=**.mlockall 检查是否成功。
3.配置集群
将 es 拷贝3份 ,分别为 es1,es2,es3
修改 conf 下的 elasticsearch.yml
es1
cluster.name: elastic
node.name: node-1
node.master:true
path.data: /redxun/elastic/es1/data
path.logs: /redxun/elastic/es1/logs
bootstrap.memory_lock: false
network.host: 202.10.79.170
network.publish_host: 202.10.79.170
http.port: 9201
transport.tcp.port: 9301
discovery.zen.ping.unicast.hosts: ["202.10.79.170:9201","202.10.79.170:9202","202.10.79.170:9203"]
discovery.zen.minimum_master_nodes: 2
es2
cluster.name: elastic
node.name: node-2
node.master:true
path.data: /redxun/elastic/es2/data
path.logs: /redxun/elastic/es2/logs
bootstrap.memory_lock: false
network.publish_host: 202.10.79.170
network.host: 202.10.79.170
http.port: 9202
transport.tcp.port: 9302
discovery.zen.ping.unicast.hosts: ["202.10.79.170:9201","202.10.79.170:9202","202.10.79.170:9203"]
discovery.zen.minimum_master_nodes: 2
es3
cluster.name: elastic
node.name: node-3
node.master:true
path.data: /redxun/elastic/es3/data
path.logs: /redxun/elastic/es3/logs
bootstrap.memory_lock: false
network.publish_host: 202.10.79.170
network.host: 202.10.79.170
http.port: 9203
transport.tcp.port: 9303
discovery.zen.ping.unicast.hosts: ["202.10.79.170:9201","202.10.79.170:9202","202.10.79.170:9203"]
discovery.zen.minimum_master_nodes: 2
需要注意的是 network.publish_host 必填。
4.配置JVM
编辑 es1/config/jvm.options
编辑
-Xms1g
-Xmx1g
内存的设置一般为系统内存的一半。
5.配置监控
下载 cerebro-0.8.1
https://github.com/lmenezes/cerebro
下载后配置:
编辑配置文件
application.conf
es = { gzip = true } # Authentication auth = { type: basic settings: { username = "admin" password = "1234" } } hosts = [ { host = "http://202.10.79.170:9201" name = "my-application" } ] http.port=8001 http.address=202.10.79.170
编辑完成后启动 cerebro
./bin/cerebro

创建索引
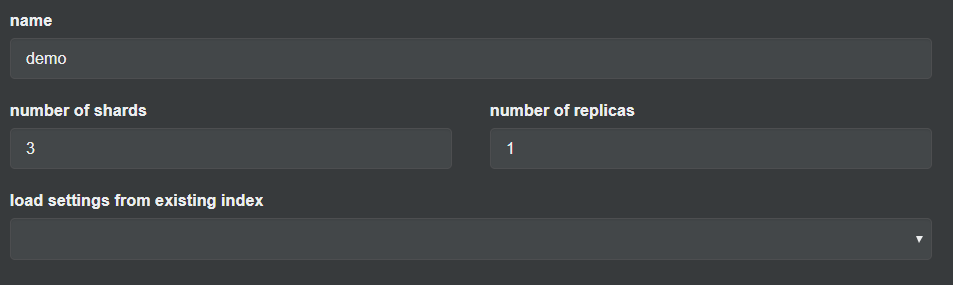
创建三个分配,一个副本。
索引分布

这里可以看到索引分布到了3个实例上,如果一台机器宕机,那么数据可以进行恢复。
6.安装中文分词器
下载
https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.5.4/elasticsearch-analysis-ik-6.5.4.zip
在es 的plugins目录创建一个ik目录
将文件解压到这个目录。
启动es
启动时可以看到日志
[2019-01-05T17:13:08,535][INFO ][o.e.p.PluginsService ] [node-1] loaded plugin [analysis-ik]
表示 ik 安装成功。
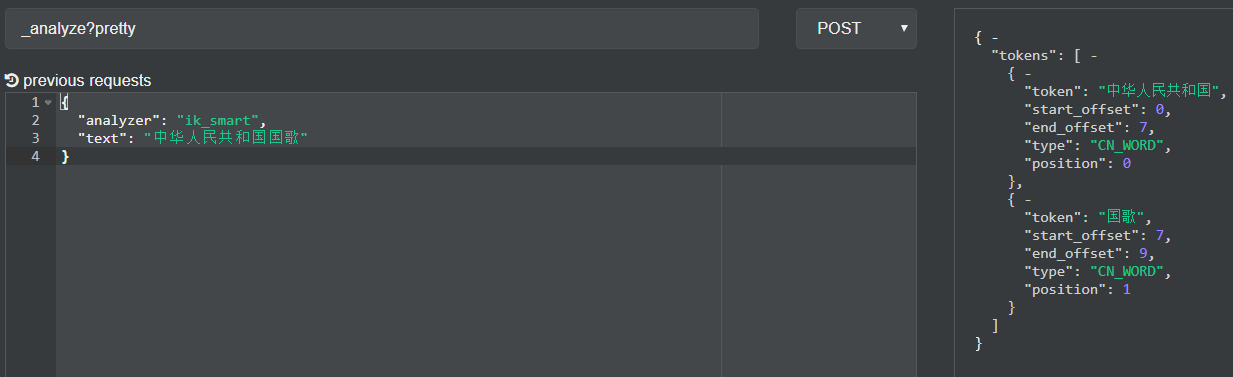
测试中文分词,使用cerebro测试
7.防止脑裂
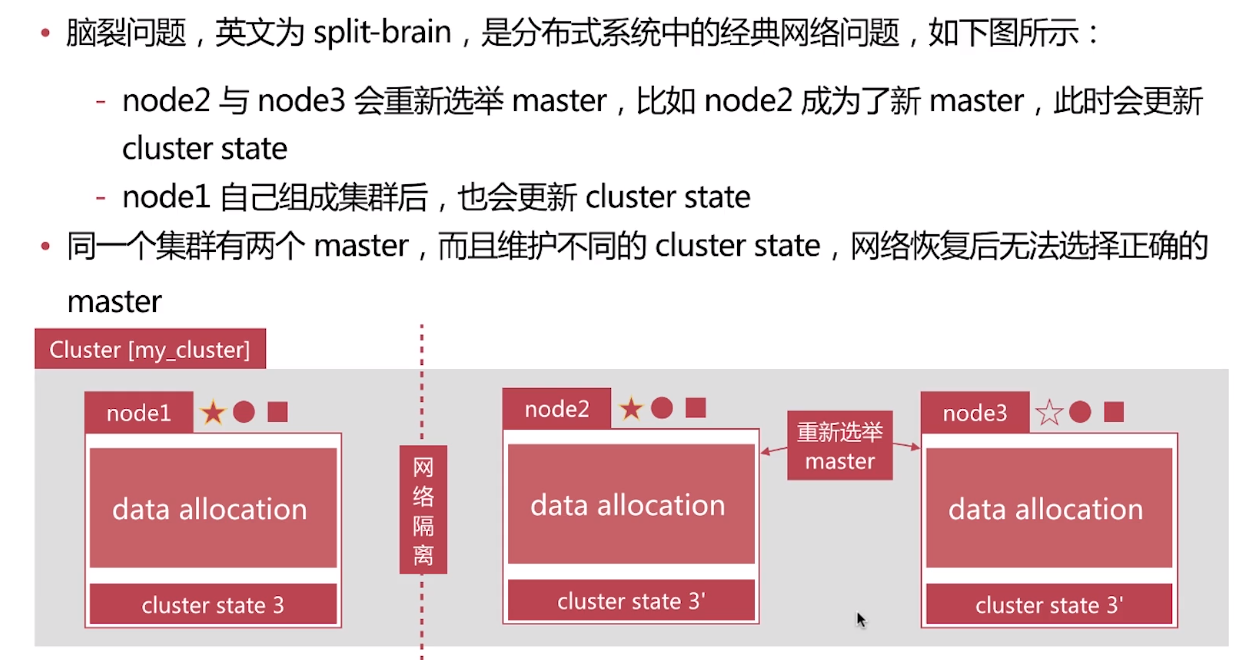
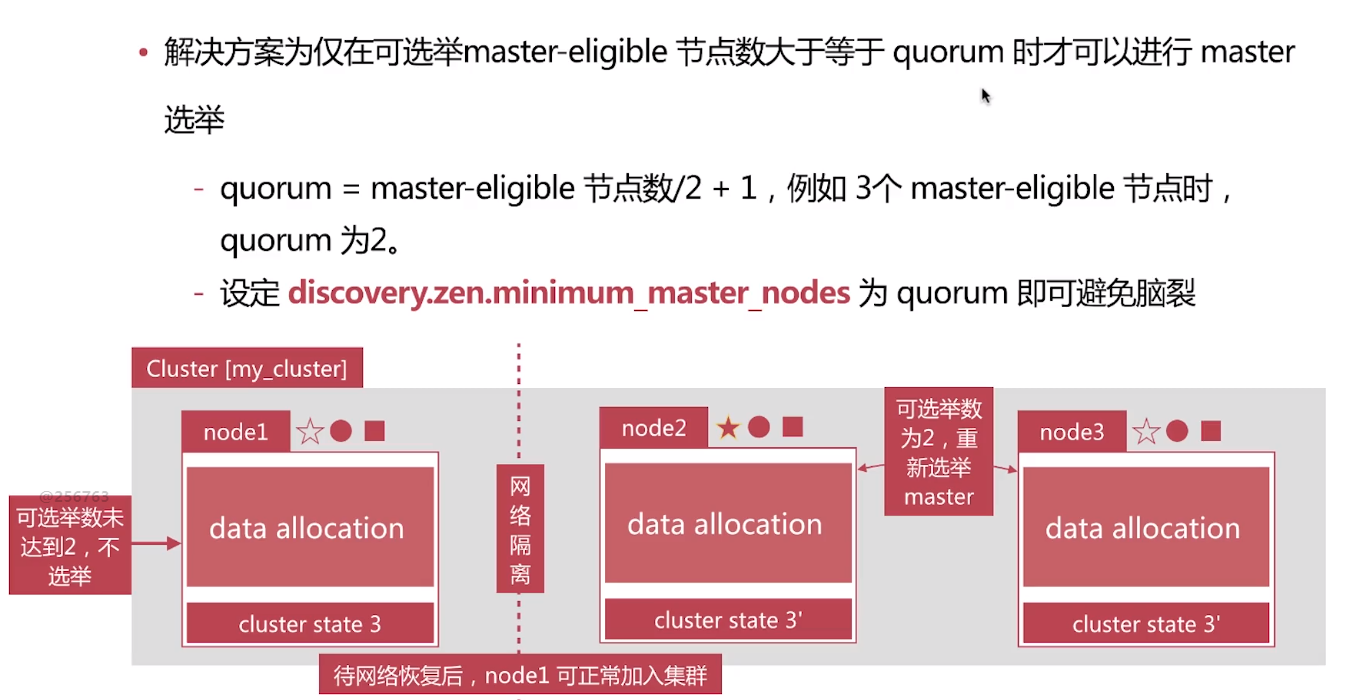
一般的做法在一个集群中设置3个MASTER节点,将discovery.zen.minimum_master_nodes 设置为2 就可以了。
集群配置参数

一般node.master 设置为3个
discovery.zen.ping.unicast.hosts 设置node.master的节点地址。
discovery.zen.minimum_master_nodes 设置为2

建议使用api进行设置。


内存数量量比:
搜索类每个节点存储数据最多496g
日志数据可以为31*48 1500g左右。