SQL性能优化
订单导出: SXSSFWorkBook 大型EXCEL文件导出不会内存溢出 用磁盘换内存
限制100W行、1500列
rightOrderInfo ightInfo ightRuleInfo ightUserInfouserCardInfodrivingOrderInfoparkOrderInfo
优化前:for循环
In/exists https://blog.csdn.net/u013825231/article/details/82776721
in想必大家用的很多吧,原理也是很简单就是和我们上面一样,而exists的原理就不一样了,他是通过子查询返回的数据是否为null,如果不为null,那么就会将当前的数据加入结果集,因此我们select * from a的时候,我们是从第一条数据开始执行的,每次执行都会去执行exists的子查询,如果不为null就加入结果集,反之则不加入,直到最后执行完主查询为止。
索引原理
https://www.cnblogs.com/aspwebchh/p/6652855.html
·为什么要给表加上主键?
·为什么加索引后会使查询变快?
主键(也叫聚集索引)会将数据结构编程平衡树结构,无主键前查询最大复杂度O(N),添加主键后查询复杂度logaN[a是每个叶节点的分叉数,N是数据总量]
·为什么加索引后会使写入、修改、删除变慢?
增删改数据都会改变平衡树各节点中的索引数据内容,破坏树结构, 因此,在每次数据改变时, DBMS必须去重新梳理树(索引)的结构以确保它的正确,这会带来不小的性能开销,也就是为什么索引会给查询以外的操作带来副作用的原因。
非主键索引(非聚集索引),每建立一个,该字段的所有数据都会被复制,叶节点的值由 该条数据的主键值+该条数据该字段的值 组成,索引之间没有影响,给表添加索引,会增加表的体积,占用磁盘存储空间。
非聚集索引和聚集索引的区别在于,通过聚集索引可以直接查到需要查找的数据, 而通过非聚集索引先查到记录对应的主键值 ,再使用主键的值通过聚集索引查找到需要的数据,如下图
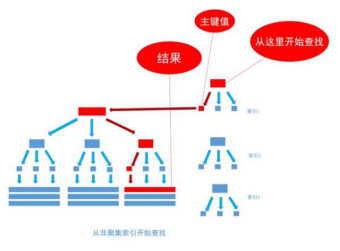
有一种例外可以不使用聚集索引就能查询出所需要的数据,复合索引(为一个索引指定两个字段)
·什么情况下要同时在两个字段上建索引?
存储过程
- IN 输入参数:表示调用者向过程传入值(传入值可以是字面量或变量)
- OUT 输出参数:表示过程向调用者传出值(可以返回多个值)(传出值只能是变量)
- INOUT 输入输出参数:既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量)