我们知道一些网站是需要账号密码才可以登陆的,例如知乎。而利用requests库里的get方法的headers参数可以达到这个目的
首先在知乎的网页上登陆自己的知乎账号,利用chrome的开发者工具(F12)可以捕获我们的get方法向浏览器提供的cookie内容,以及user-agent内容
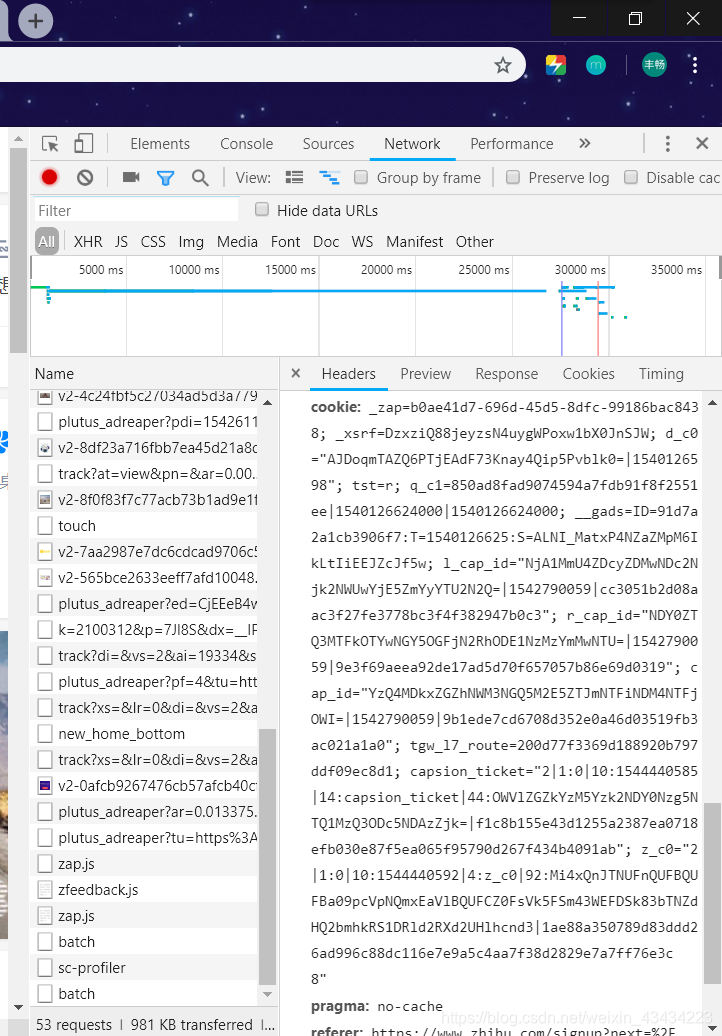

将这两个信息复制下来,添加到我们向浏览器发出请求的get()方法的headers参数中
可以这么写
header={'user-agent':'浏览器的请求头','cookie':'捕捉到的cookie'}
r=requests.get(url,headers=header)
这样浏览器就会返回给我们登陆后网站的代码了
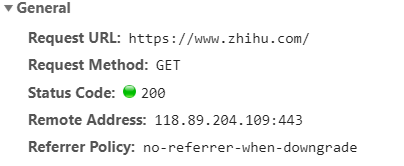
另外值得注意的是,在向知乎网页提供get请求时,应该将https://www.zhihu.com这个网址作为url而不是https://www.zhihu.com/signup?next=%2F这个网址。我们利用F12开发者工具也可以看到我们是想第一个网址来发出get请求的
通过这种方法我们就完成了爬虫上的模拟登陆