一、过滤器概念
基础API中的查询操作在面对大量数据的时候是非常物无力的,这里Hbase提供了高级的查询方法:Filter(过滤器)。过滤器可以根据簇、列、版本等更多的条件来对数据进行过滤,基于Hbase本身提供的三维有序(主键有序、列有序、版本有序),这些Filter可以高效的完成查询过滤的任务。带有Filter条件的RPC查询请求会把Filter分发到各个RegionServer,是一个服务器端的过滤器,这样可以减少网络传输的压力。
二、数据准备

二、Hbase过滤器的分类
比较过滤器
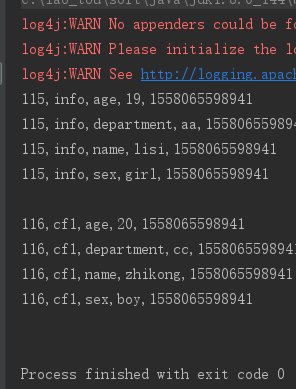
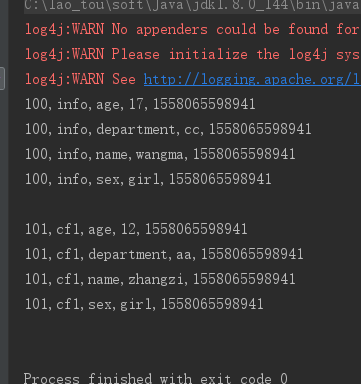
1、行键过滤器——Rowfilter,过滤rowkey=104以前的行
Filter rowFilter = new RowFilter(CompareFilter.CompareOp.GREATER, new BinaryComparator("104".getBytes()));
scan.setFilter(rowFilter);
package com.laotou; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.*; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.filter.BinaryComparator; import org.apache.hadoop.hbase.filter.CompareFilter; import org.apache.hadoop.hbase.filter.Filter; import org.apache.hadoop.hbase.filter.RowFilter; import org.apache.hadoop.hbase.util.Bytes; /** * @Author: * @Date: 2019/5/17 */ public class Test { private static final String ZK_CONNECT_KEY = "hbase.zookeeper.quorum"; private static final String ZK_CONNECT_VALUE = "192.168.200.100,192.168.200.101,192.168.200.102"; private static final String ZK_CONNECT_CLIENT = "hbase.zookeeper.property.clientPort"; private static final String ZK_CONNECT_CLIENT_PORT = "2181"; private static Configuration conf = new Configuration(); private static Connection connection = null; public static void main(String[] args) throws Exception { conf.set(ZK_CONNECT_CLIENT,ZK_CONNECT_CLIENT_PORT); conf.set(ZK_CONNECT_KEY,ZK_CONNECT_VALUE); connection = ConnectionFactory.createConnection(conf); scanData(); } private static void scanData() throws Exception { //拿到表 Table table = connection.getTable(TableName.valueOf("filtertest")); Scan scan=new Scan(); Filter rowFilter = new RowFilter(CompareFilter.CompareOp.GREATER, new BinaryComparator("104".getBytes())); scan.setFilter(rowFilter); // //调一次返回50的cell,可以减少请求次数 // scan.setCaching(50); ResultScanner scanner = table.getScanner(scan); //是通过迭代器的方式,每调用 一次next,将光标向下移动一个,所以需要动态修改next对象的值 Result next = scanner.next(); while (next!=null){ //将一个Result中的对象转为一个cell数组 Cell[] cells = next.rawCells(); for(Cell cell:cells){ System.out.println(Bytes.toString(CellUtil.cloneRow(cell))+ ","+Bytes.toString(CellUtil.cloneFamily(cell))+ ","+ Bytes.toString(CellUtil.cloneQualifier(cell))+ ","+Bytes.toString(CellUtil.cloneValue(cell))); } System.out.println(); //每循环一次,修改next的值一次 next=scanner.next(); } scanner.close(); table.close(); } }
运行结果部分截图
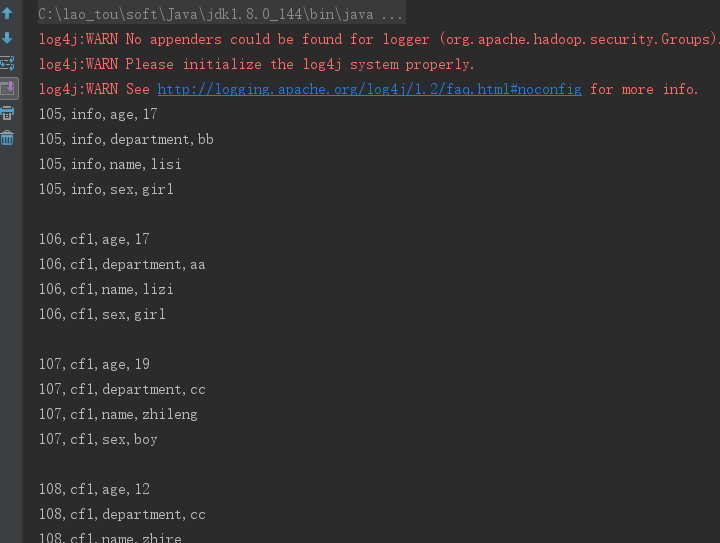
2、列簇过滤器 FamilyFilter (将列簇为info的行全部取出来)
Filter familyFilter = new FamilyFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator("info".getBytes()));
scan.setFilter(familyFilter);
package com.laotou; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.*; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.filter.*; import org.apache.hadoop.hbase.util.Bytes; /** * @Author: * @Date: 2019/5/17 */ public class Test { private static final String ZK_CONNECT_KEY = "hbase.zookeeper.quorum"; private static final String ZK_CONNECT_VALUE = "192.168.200.100,192.168.200.101,192.168.200.102"; private static final String ZK_CONNECT_CLIENT = "hbase.zookeeper.property.clientPort"; private static final String ZK_CONNECT_CLIENT_PORT = "2181"; private static Configuration conf = new Configuration(); private static Connection connection = null; public static void main(String[] args) throws Exception { conf.set(ZK_CONNECT_CLIENT,ZK_CONNECT_CLIENT_PORT); conf.set(ZK_CONNECT_KEY,ZK_CONNECT_VALUE); connection = ConnectionFactory.createConnection(conf); scanData(); } private static void scanData() throws Exception { //拿到表 Table table = connection.getTable(TableName.valueOf("filtertest")); Scan scan=new Scan(); Filter familyFilter = new FamilyFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator("info".getBytes())); scan.setFilter(familyFilter); // //调一次返回50的cell,可以减少请求次数 scan.setCaching(50); ResultScanner scanner = table.getScanner(scan); //是通过迭代器的方式,每调用 一次next,将光标向下移动一个,所以需要动态修改next对象的值 Result next = scanner.next(); while (next!=null){ //将一个Result中的对象转为一个cell数组 Cell[] cells = next.rawCells(); for(Cell cell:cells){ System.out.println(Bytes.toString(CellUtil.cloneRow(cell))+ ","+Bytes.toString(CellUtil.cloneFamily(cell))+ ","+ Bytes.toString(CellUtil.cloneQualifier(cell))+ ","+Bytes.toString(CellUtil.cloneValue(cell))); } System.out.println(); //每循环一次,修改next的值一次 next=scanner.next(); } scanner.close(); table.close(); } }
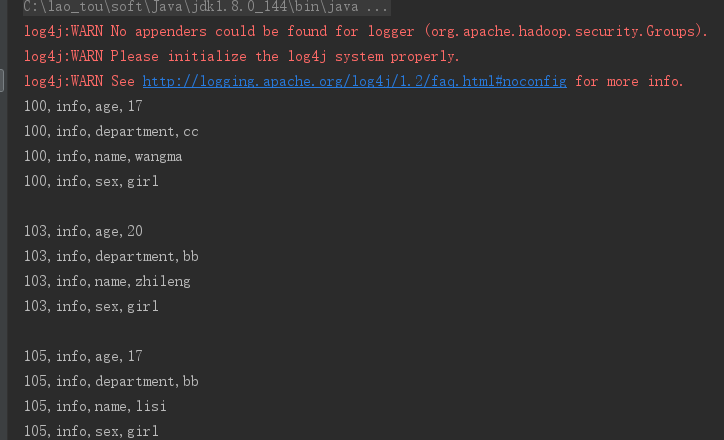
3、列过滤器 QualifierFilter
Filter valueFilter = new ValueFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator("boy"));
scan.setFilter(valueFilter);
private static void scanData() throws Exception { //拿到表 Table table = connection.getTable(TableName.valueOf("filtertest")); Scan scan=new Scan(); Filter valueFilter = new ValueFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator("boy")); scan.setFilter(valueFilter); // //调一次返回50的cell,可以减少请求次数 scan.setCaching(50); ResultScanner scanner = table.getScanner(scan); //是通过迭代器的方式,每调用 一次next,将光标向下移动一个,所以需要动态修改next对象的值 Result next = scanner.next(); while (next!=null){ //将一个Result中的对象转为一个cell数组 Cell[] cells = next.rawCells(); for(Cell cell:cells){ System.out.println(Bytes.toString(CellUtil.cloneRow(cell))+ ","+Bytes.toString(CellUtil.cloneFamily(cell))+ ","+ Bytes.toString(CellUtil.cloneQualifier(cell))+ ","+Bytes.toString(CellUtil.cloneValue(cell))); } System.out.println(); //每循环一次,修改next的值一次 next=scanner.next(); } scanner.close(); table.close(); }

4、时间戳过滤器 TimestampsFilter
List<Long> list = new ArrayList<>();
list.add( Long.valueOf("1558072555745").longValue());
TimestampsFilter timestampsFilter = new TimestampsFilter(list);
scan.setFilter(timestampsFilter);
private static void scanData() throws Exception { //拿到表 Table table = connection.getTable(TableName.valueOf("filtertest")); Scan scan=new Scan(); List<Long> list = new ArrayList<>(); list.add( Long.valueOf("1558072555745").longValue()); TimestampsFilter timestampsFilter = new TimestampsFilter(list); scan.setFilter(timestampsFilter); // //调一次返回50的cell,可以减少请求次数 scan.setCaching(50); ResultScanner scanner = table.getScanner(scan); //是通过迭代器的方式,每调用 一次next,将光标向下移动一个,所以需要动态修改next对象的值 Result next = scanner.next(); while (next!=null){ //将一个Result中的对象转为一个cell数组 Cell[] cells = next.rawCells(); for(Cell cell:cells){ System.out.println(Bytes.toString(CellUtil.cloneRow(cell))+ ","+Bytes.toString(CellUtil.cloneFamily(cell))+ ","+ Bytes.toString(CellUtil.cloneQualifier(cell))+ ","+Bytes.toString(CellUtil.cloneValue(cell))+ ","+cell.getTimestamp()); } System.out.println(); //每循环一次,修改next的值一次 next=scanner.next(); } scanner.close(); table.close(); }

专用过滤器
1、单列值过滤器 SingleColumnValueFilter ----会返回满足条件的整行
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(
"info".getBytes(), //列簇
"name".getBytes(), //列
CompareFilter.CompareOp.EQUAL,
new SubstringComparator("lisi"));
private static void scanData() throws Exception { //拿到表 Table table = connection.getTable(TableName.valueOf("filtertest")); Scan scan=new Scan(); SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter( "info".getBytes(), //列簇 "name".getBytes(), //列 CompareFilter.CompareOp.EQUAL, new SubstringComparator("lisi")); //如果不设置为 true,则那些不包含指定 column 的行也会返回 singleColumnValueFilter.setFilterIfMissing(true); scan.setFilter(singleColumnValueFilter); // //调一次返回50的cell,可以减少请求次数 scan.setCaching(50); ResultScanner scanner = table.getScanner(scan); //是通过迭代器的方式,每调用 一次next,将光标向下移动一个,所以需要动态修改next对象的值 Result next = scanner.next(); while (next!=null){ //将一个Result中的对象转为一个cell数组 Cell[] cells = next.rawCells(); for(Cell cell:cells){ System.out.println(Bytes.toString(CellUtil.cloneRow(cell))+ ","+Bytes.toString(CellUtil.cloneFamily(cell))+ ","+ Bytes.toString(CellUtil.cloneQualifier(cell))+ ","+Bytes.toString(CellUtil.cloneValue(cell))+ ","+cell.getTimestamp()); } System.out.println(); //每循环一次,修改next的值一次 next=scanner.next(); } scanner.close(); table.close(); }
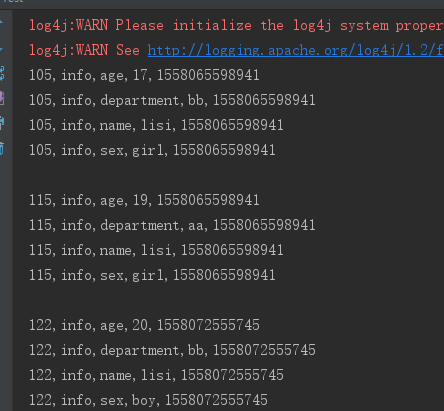
2、单列值排除器 SingleColumnValueExcludeFilter
SingleColumnValueExcludeFilter singleColumnValueExcludeFilter = new SingleColumnValueExcludeFilter( "info".getBytes(), "name".getBytes(), CompareOp.EQUAL, new SubstringComparator("lisi")); singleColumnValueExcludeFilter.setFilterIfMissing(true); scan.setFilter(singleColumnValueExcludeFilter);
private static void scanData() throws Exception { //拿到表 Table table = connection.getTable(TableName.valueOf("filtertest")); Scan scan=new Scan(); SingleColumnValueExcludeFilter singleColumnValueExcludeFilter = new SingleColumnValueExcludeFilter( "info".getBytes(), "name".getBytes(), CompareFilter.CompareOp.EQUAL, new SubstringComparator("lisi")); singleColumnValueExcludeFilter.setFilterIfMissing(true); scan.setFilter(singleColumnValueExcludeFilter); // //调一次返回50的cell,可以减少请求次数 scan.setCaching(50); ResultScanner scanner = table.getScanner(scan); //是通过迭代器的方式,每调用 一次next,将光标向下移动一个,所以需要动态修改next对象的值 Result next = scanner.next(); while (next!=null){ //将一个Result中的对象转为一个cell数组 Cell[] cells = next.rawCells(); for(Cell cell:cells){ System.out.println(Bytes.toString(CellUtil.cloneRow(cell))+ ","+Bytes.toString(CellUtil.cloneFamily(cell))+ ","+ Bytes.toString(CellUtil.cloneQualifier(cell))+ ","+Bytes.toString(CellUtil.cloneValue(cell))+ ","+cell.getTimestamp()); } System.out.println(); //每循环一次,修改next的值一次 next=scanner.next(); } scanner.close(); table.close(); }
与上面单列值过滤器相比结果中排除了打印lisi这个字段和值
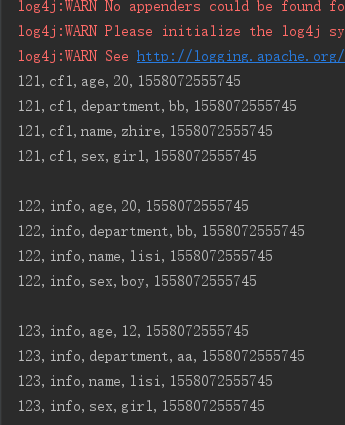
3、前缀过滤器 PrefixFilter----针对行键,将rowkey以12开头的打印出来
PrefixFilter prefixFilter = new PrefixFilter("12".getBytes()); scan.setFilter(prefixFilter);
package com.laotou; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.*; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.filter.*; import org.apache.hadoop.hbase.util.Bytes; import java.util.ArrayList; import java.util.List; /** * @Author: * @Date: 2019/5/17 */ public class Test { private static final String ZK_CONNECT_KEY = "hbase.zookeeper.quorum"; private static final String ZK_CONNECT_VALUE = "192.168.200.100,192.168.200.101,192.168.200.102"; private static final String ZK_CONNECT_CLIENT = "hbase.zookeeper.property.clientPort"; private static final String ZK_CONNECT_CLIENT_PORT = "2181"; private static Configuration conf = new Configuration(); private static Connection connection = null; public static void main(String[] args) throws Exception { conf.set(ZK_CONNECT_CLIENT,ZK_CONNECT_CLIENT_PORT); conf.set(ZK_CONNECT_KEY,ZK_CONNECT_VALUE); connection = ConnectionFactory.createConnection(conf); scanData(); } private static void scanData() throws Exception { //拿到表 Table table = connection.getTable(TableName.valueOf("filtertest")); Scan scan=new Scan(); PrefixFilter prefixFilter = new PrefixFilter("12".getBytes()); scan.setFilter(prefixFilter); // //调一次返回50的cell,可以减少请求次数 scan.setCaching(50); ResultScanner scanner = table.getScanner(scan); //是通过迭代器的方式,每调用 一次next,将光标向下移动一个,所以需要动态修改next对象的值 Result next = scanner.next(); while (next!=null){ //将一个Result中的对象转为一个cell数组 Cell[] cells = next.rawCells(); for(Cell cell:cells){ System.out.println(Bytes.toString(CellUtil.cloneRow(cell))+ ","+Bytes.toString(CellUtil.cloneFamily(cell))+ ","+ Bytes.toString(CellUtil.cloneQualifier(cell))+ ","+Bytes.toString(CellUtil.cloneValue(cell))+ ","+cell.getTimestamp()); } System.out.println(); //每循环一次,修改next的值一次 next=scanner.next(); } scanner.close(); table.close(); }
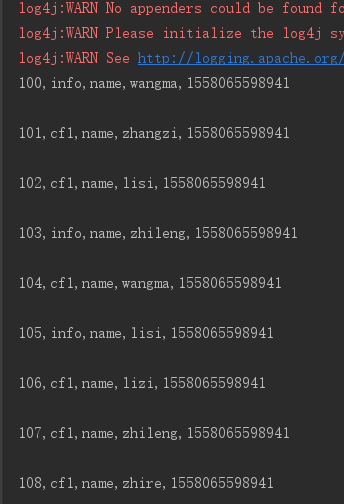
4、列前缀过滤器 ColumnPrefixFilter
ColumnPrefixFilter columnPrefixFilter = new ColumnPrefixFilter("name".getBytes()); scan.setFilter(columnPrefixFilter);
private static void scanData() throws Exception { //拿到表 Table table = connection.getTable(TableName.valueOf("filtertest")); Scan scan=new Scan(); ColumnPrefixFilter columnPrefixFilter = new ColumnPrefixFilter("name".getBytes()); scan.setFilter(columnPrefixFilter); // //调一次返回50的cell,可以减少请求次数 scan.setCaching(50); ResultScanner scanner = table.getScanner(scan); //是通过迭代器的方式,每调用 一次next,将光标向下移动一个,所以需要动态修改next对象的值 Result next = scanner.next(); while (next!=null){ //将一个Result中的对象转为一个cell数组 Cell[] cells = next.rawCells(); for(Cell cell:cells){ System.out.println(Bytes.toString(CellUtil.cloneRow(cell))+ ","+Bytes.toString(CellUtil.cloneFamily(cell))+ ","+ Bytes.toString(CellUtil.cloneQualifier(cell))+ ","+Bytes.toString(CellUtil.cloneValue(cell))+ ","+cell.getTimestamp()); } System.out.println(); //每循环一次,修改next的值一次 next=scanner.next(); } scanner.close(); table.close(); }
5、分页过滤器 PageFilter
每一页打印两条数据
Filter filter = new PageFilter(2);
private static void scanData() throws Exception { //拿到表 Table table = connection.getTable(TableName.valueOf("filtertest")); Scan scan=new Scan(); Filter filter = new PageFilter(2); scan.setFilter(filter); // //调一次返回50的cell,可以减少请求次数 scan.setCaching(50); ResultScanner scanner = table.getScanner(scan); //是通过迭代器的方式,每调用 一次next,将光标向下移动一个,所以需要动态修改next对象的值 Result next = scanner.next(); while (next!=null){ //将一个Result中的对象转为一个cell数组 Cell[] cells = next.rawCells(); for(Cell cell:cells){ System.out.println(Bytes.toString(CellUtil.cloneRow(cell))+ ","+Bytes.toString(CellUtil.cloneFamily(cell))+ ","+ Bytes.toString(CellUtil.cloneQualifier(cell))+ ","+Bytes.toString(CellUtil.cloneValue(cell))+ ","+cell.getTimestamp()); } System.out.println(); //每循环一次,修改next的值一次 next=scanner.next(); } scanner.close(); table.close(); }
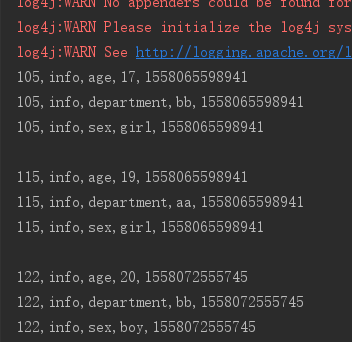
6、行键范围过滤 [startkey,endkey),结果为左闭右开
scan.setStartRow(Bytes.toBytes("115")); scan.setStopRow(Bytes.toBytes("117"));
private static void scanData() throws Exception { //拿到表 Table table = connection.getTable(TableName.valueOf("filtertest")); Scan scan=new Scan(); scan.setStartRow(Bytes.toBytes("115")); scan.setStopRow(Bytes.toBytes("117")); // //调一次返回50的cell,可以减少请求次数 scan.setCaching(50); ResultScanner scanner = table.getScanner(scan); //是通过迭代器的方式,每调用 一次next,将光标向下移动一个,所以需要动态修改next对象的值 Result next = scanner.next(); while (next!=null){ //将一个Result中的对象转为一个cell数组 Cell[] cells = next.rawCells(); for(Cell cell:cells){ System.out.println(Bytes.toString(CellUtil.cloneRow(cell))+ ","+Bytes.toString(CellUtil.cloneFamily(cell))+ ","+ Bytes.toString(CellUtil.cloneQualifier(cell))+ ","+Bytes.toString(CellUtil.cloneValue(cell))+ ","+cell.getTimestamp()); } System.out.println(); //每循环一次,修改next的值一次 next=scanner.next(); } scanner.close(); table.close(); }