一、hdfs文件读取过程
hdfs有一个FileSystem实例,客户端通过调用这个实例的open()方法就可以打开系统中希望读取的文件,hdfs通过rpc协议调用Nadmenode获取block的位置信息,对于文件的每一块,Namenode会返回含有该block副本的Datanode的节点地址;客户端还会根据网络拓扑来确定它与每一个DataNode的位置信息,从离它最近的哪个DataNode获取block的副本(所谓的就近原则),最理想的情况是该block就存储在客户端所在的节点上。
hdfs会返回一个FDSaraInputStream对象,FDSDataInputStream类转而封装成DFSDataInputStream对象,这个对象管理着与DataNode和NameNode的I/O,具体过程如下:
1、客户端发起请求。
2、客户端从NameNode得到文件块及位置信息列表(即客户端从NameNode获取该block的元数据信息)
3、客户端直接和DataNode交互读取数据
4、读取完成关闭连接
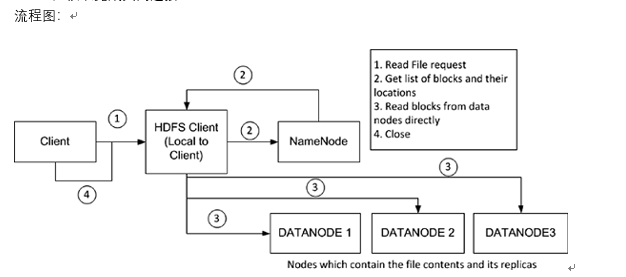
当FSDataInputStream与DataNode通信时遇到错误,它会选取另一个较近的DataNode,并为出故障的DataNode做标记以免重复向其读取数据。
FSDataInputStream还会对读取的数据块进行校验和确认,发现块损坏时也会重新读取并通知NameNode。
这样设计的巧妙之处:
1、 让客户端直接联系DataNode检索数据,可以使hdfs扩展到大量的并发客户端,因为数据流就是分散在集群的每个节点上的,在运行MapReduce任务时,每个客户端就是 DataNode节点。
2、 NameNode仅需相应数据块的weiz信息请求(位置信息在内存中,速度极快),否则随着客户端的增加,NameNode会很快成为瓶颈。
二、hdfs文件写入过程
hdfs有一个DistributedFileSystem实例,客户端通过调用这个实例的create()方法就可以创建文件。DistributedFileSystem会发送给NameNode一个RPC调用,在文件系统的命名空间创建一个新文件,在创建文件前NameNode会做一些检查,如文件是否存在,客户端是否有创建权限等,若检查通过,NameNode会为创建文件写一条记录到本地磁盘的EditLog,若不通过会向客户端抛出IOException。创建成功之后DistributedFileSystem会返回一个FSDataOutputStream对象,客户端由此开始写入数据。
同读文件过程一样,FSDataOutputStream类转而封装成DFSDataOutputStream对象,这个对象管理着与DataNode和NameNode的I/O,具体过程是:
1. 客户端在向NameNode请求之前先写入文件数据到本地文件系统的一个临时文件2. 待临时文件达到块大小时开始向NameNode请求DataNode信息3. NameNode在文件系统中创建文件并返回给客户端一个数据块及其对应DataNode的地址列表(列表中包含副本存放的地址)4. 客户端通过上一步得到的信息把创建临时文件块flush到列表中的第一个DataNode5. 当文件关闭,NameNode会提交这次文件创建,此时,文件在文件系统中可见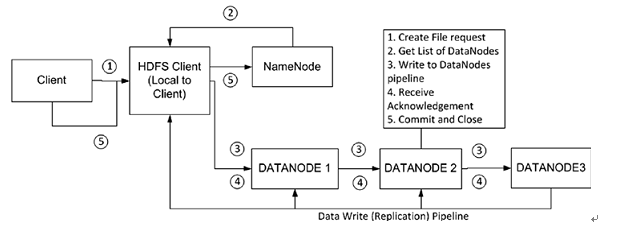
上面第四步描述的flush过程实际处理过程比较负杂,现在单独描述一下:
上面第四步描述的flush过程实际处理过程比较负杂,现在单独描述一下:
1. 首先,第一个DataNode是以数据包(数据包一般4KB)的形式从客户端接收数据的,DataNode在把数据包写入到本地磁盘的同时会向第二个DataNode(作为副本节点)传送数据。
2. 在第二个DataNode把接收到的数据包写入本地磁盘时会向第三个DataNode发送数据包
3. 第三个DataNode开始向本地磁盘写入数据包。此时,数据包以流水线的形式被写入和备份到所有DataNode节点
4. 传送管道中的每个DataNode节点在收到数据后都会向前面那个DataNode发送一个ACK,最终,第一个DataNode会向客户端发回一个ACK
5. 当客户端收到数据块的确认之后,数据块被认为已经持久化到所有节点。然后,客户端会向NameNode发送一个确认
6. 如果管道中的任何一个DataNode失败,管道会被关闭。数据将会继续写到剩余的DataNode中。同时NameNode会被告知待备份状态,NameNode会继续备份数据到新的可用的节点
7. 数据块都会通过计算校验和来检测数据的完整性,校验和以隐藏文件的形式被单独存放在hdfs中,供读取时进行完整性校验
三、hdfs文件删除过程
hdfs文件删除过程一般需要如下几步:
hdfs文件删除过程一般需要如下几步:
1. 一开始删除文件,NameNode只是重命名被删除的文件到/trash目录,因为重命名操作只是元信息的变动,所以整个过程非常快。
在/trash中文件会被保留一定间隔的时间(可配置,默认是6小时),在这期间,文件可以很容易的恢复,恢复只需要将文件从/trash移出即可。
2. 当指定的时间到达,NameNode将会把文件从命名空间中删除
3. 标记删除的文件块释放空间,HDFS文件系统显示空间增加