【导语】
这篇文章本人在CSDN也发布了。浮世绘太空
作为一个刚开始学习爬虫的小白,逐渐感觉想要写好网络爬虫并不是一件容易的事,其中需要考虑的地方有很多。受大环境影响,无论是工程领域还是研究领域,数据已然成为了不可或缺的部分,而数据的获取除却人工模拟,很大程度上通过爬虫来爬虫需要的数据。当然,掌握了爬虫,对工作上或者是生活上,在收集各种各样的数据或者文件都会更加的方便快捷。
学习爬虫的过程,想要基础更加扎实,就必须学习爬虫相关的各种基础库,比如:
发送请求:urlib,urlib3,requests
返回数据:html,js,json,以及处理字符串的各种库
针对各种格式,需要对应的解析器例如,正则表达式,解析html需要用到xpath,beautifulsoup,pyquery,js代码需要用到js引擎来进行运行和分析,例如:node js,v8,json等
到后期,渐渐追求效率,也就是提高爬虫爬取的速度,了解到requests属于同步请求,也就是从发出请求到收到响应,线程一直在等,也许会想到用多线程,但是python的单进程只能跑满一个核,何况也不是那么好写,同步控制,分配任务。。。
在python3.5新增了一个aiohttp(异步请求库),可以实现发送一批请求,以事件驱动,根据回调函数来实现单线程异步
效率有了,又觉得不够方便,于是乎便有了框架scrapy
分析网站
首先必须需要知道网站的几个要素:
-
网站URL
-
使用浏览器的F12查看,点击跳转链接操作或者进行网站请求时,是否有network是否有新的API
-
请求头
headers,包含User-Agent,Accept,Accept-Encoding,Accept-Language,Referer以及Cookie
前期准备工作
-
分析网站的URL
我们以”39问医生“网站的网址为例:
http://ask.39.net -
确定要爬取的数据,包括:
关键字,文本等-
需要爬取的目标数据:
问题标题,问题描述以及医生回答;
注意:各占一行,若问题标题与问题描述相同时,取其一即可
当标题与描述相同,则用空行代替描述,便于后续处理数据;
-
分析过程
- 通过操作流程确定,我们首先访问网站地址
http://ask.39.net,可以看到如下图所示的页面,重点关注红框内的内容;
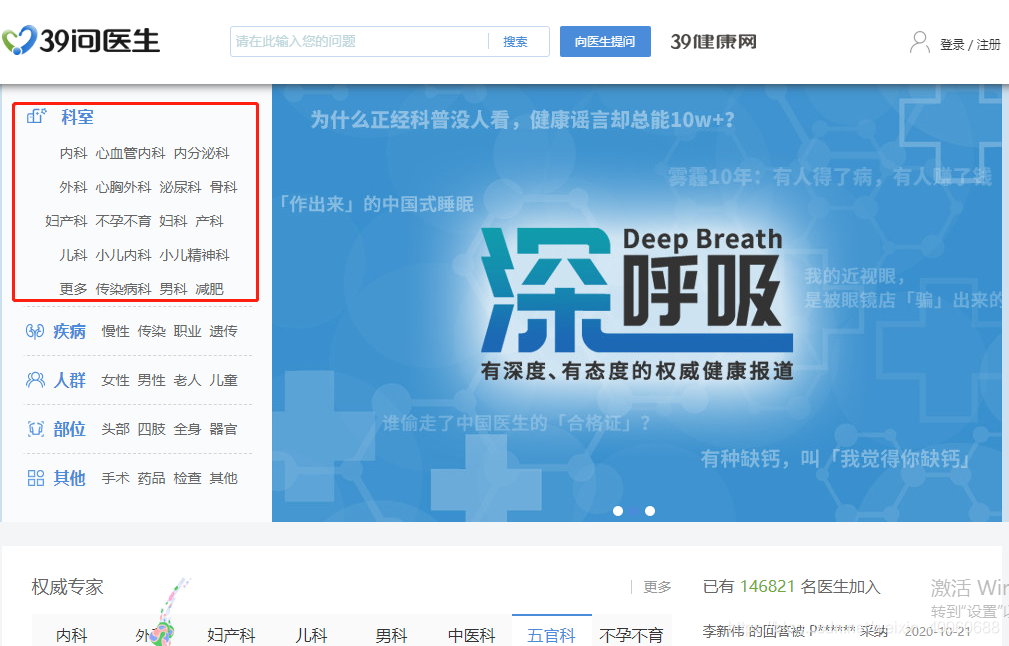
- 比如,我现在要点击内科,此时可以看到关于内科的最新问题
此时的地址:http://ask.39.net/browse/313-1-1.html,往下拉就会看到如下图所示红框内的字样,点击它;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hcs94n1m-1610962423917)(E:HelloautoHttprunnerdoccrawler.assetsimage-20210118171231221.png)]](https://img-blog.csdnimg.cn/20210118173916759.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MDk2MDY4OA==,size_16,color_FFFFFF,t_70)
-
然后进入到如下图所示的内容此时地址链接:
http://ask.39.net/news/313-1.html,这个页面包含内科专题所有的问题,我们点击问题“我的病,七月份生了一次,吃药养到十二月”,也可以任意选择问题,看个人兴趣爱好.....
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g3r2eDwi-1610962423922)(E:HelloautoHttprunnerdoccrawler.assetsimage-20210118171344492.png)]](https://img-blog.csdnimg.cn/20210118174010654.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MDk2MDY4OA==,size_16,color_FFFFFF,t_70)
-
重点来了,这个页面就是我们要爬取数据的最终页面
http://ask.39.net/question/79045037.html,然后保存到txt文件中,保存后需要检查一下文件里面的格式,不然后面跑脚本的时候会因为格式的问题报错;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H5oFNnoJ-1610962423931)(E:HelloautoHttprunnerdoccrawler.assetsimage-20210118171556172.png)]](https://img-blog.csdnimg.cn/2021011817413814.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MDk2MDY4OA==,size_16,color_FFFFFF,t_70)
-
使用浏览器的开发者工具(F12),在点击跳转链接操作或者进行你要爬虫数据的操作流程时,查看Network 是否有新API出现,决定访问的方式;
-
有API如何访问?
# 使用requests库 import requests source = requests,get(url) -
若无API如何访问?
# 使用urllib库 from urllib import request source = request.Request(url=url) response = request.urlopen(source)
-
-
解析 HTML
常用的解析方式主要有
正则,beautifulsoup,xpath,pyquery;在这里我是使用
beautifulsoup,正则来解析html的from bs4 import BeautifulSoup import lxml html = response.read().decode('utf-8') soup = BeautifulSoup(html, 'lxml')
代码解读
访问网站地址
import urllib3
import urllib.error
from urllib import request
from io import BytesIO
import gzip
import ssl
from bs4 import BeautifulSoup
class AskCrawler:
def __init__(self):
self.user_headers = {}
def get_html(self, url):
"""
建立连接
当你urllib.urlopen一个 https 的时候会验证一次 SSL 证书
context = ssl._create_unverified_context()
URLError
:return: soup
"""
try:
context = ssl._create_unverified_context()
req = request.Request(url=url, headers=self.user_headers)
response = request.urlopen(req, context=context)
htmls = response.read()
buff = BytesIO(htmls)
f = gzip.GzipFile(fileobj=buff)
html = f.read().decode('utf-8',"ignore")
soup = BeautifulSoup(html, 'lxml')
return soup
except urllib3.exceptions.HTTPError as e:
print('http error %s'% e)
except urllib.error.URLError as e:
print(e.reason)
- 发送请求访问
'http://ask.39.net'
from urllib import request
# 加入浏览器信息,由于网站有反爬机制,如果没有加入headers,可能会抛出403异常
req = request.Request(url=url, headers=self.user_headers)
# 获取网页
response = request.urlopen(req, context=context)
# 得到的是网页的字节码
htmls = response.read()
- 封装请求头(在这里说明一下,本网站没有
Cookie)
# 伪装成客户端访问,如果有需要可以做个浏览器列表池
self.user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
# 请求头,规避出现403异常
self.user_headers = {
'User-Agent': self.user_agent,
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,zh-HK;q=0.8',
'Referer': 'http://ask.39.net/',
}
- 避免
URLError异常,这是为了防止遇到https的情况,当你urllib.urlopen一个https的时候会验证一次SSL证书
import ssl
context = ssl._create_unverified_context()
-
解码
-
为什么要进行解码?
因为原始数据是十六进制内容,需要对其进行解析,解析后,中文字符没有解析出来,导致出现乱码(decode的默认参数为
strict); -
解决方案:
binascii.unhexlify(hex_str).decode('utf8','ignore')回到原文。。。
from io import BytesIO import gzip # 以下三行,是处理 数据被压缩过,我们要对数据进行解压(解码) buff = BytesIO(htmls) f = gzip.GzipFile(fileobj=buff) html = f.read().decode('utf-8',"ignore") # ignore(解码的参数),直接忽略乱码注意:当没有进行解码的操作时,可能会抛出如下的错误:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte
-
-
使用
lxml解析器来对网页html进行解析from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml')
接下来,我们要对获取到的html进行分析,并使用正则表达式提取我们需要的数据。由于网站从一开始的链接地址到我们需要爬取的页面过程经过几个链接地址,为了提高效率,更加便捷性,也在一定程度上规避网站的反爬,在这里我选择避开前面几个链接地址,从 http://ask.39.net/news/313-1.html 这个地址链接作为入口,并获取每个问题的ID,然后通过拼接,从而得到最终我们需要的数据页面地址链接。
设计思路:我们首先分为两个阶段来获取数据,第一个阶段,由于 http://ask.39.net/news/313-1.html 这个页面展示的是指定专题所有的问题,我们可以先获取该专题所有的问题ID,然后通过拼接得到最终问题答案的地址链接,最后我们暂时将问题的URL保存起来;第二个阶段,使用正则表达式分别对每个问题页面的数据进行提取。
前面讲到分阶段获取数据,为什么要这样处理?
在这里,主要考虑到如果提取一次数据,就要对该网站进行两次访问,可能会对网站造成负担,而且访问过于频繁容易引起反爬机制的注意;即使在这里加上时间等待,效果并不是很理想,所以,我将其分为两个阶段进行处理。
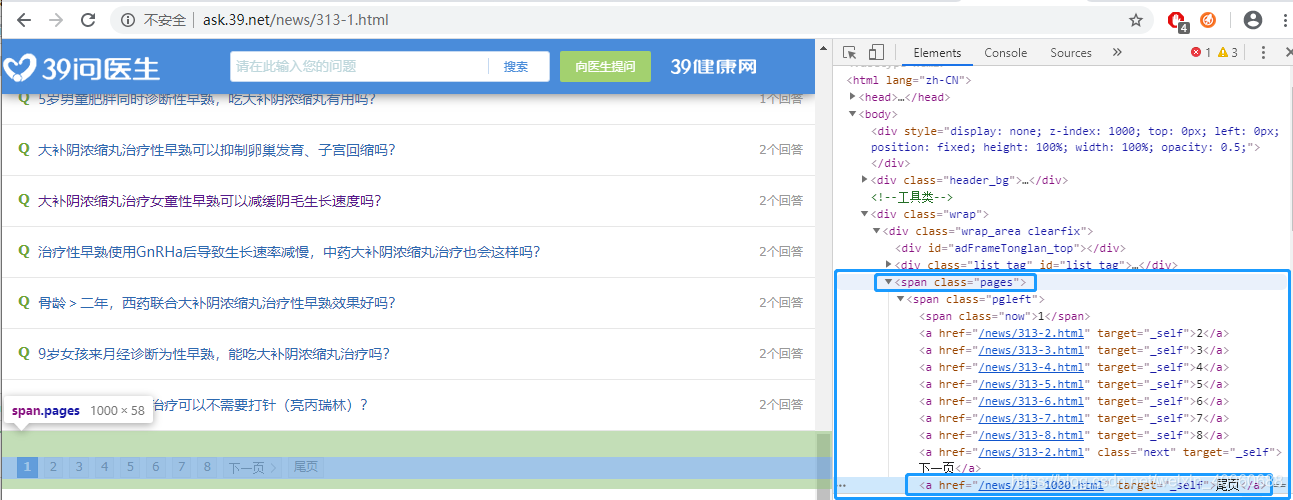
- 第一个阶段
在该网站我们如果要获取所有的问题ID,就必须要先获取所有的分页链接,也就是 /news/{313-1...max_page}.html ( 需要特别注意的是分页问题);最终拼接成:http://ask.39.net/question/79010365.html类似的地址;
"""
分页的链接
通过获取最大页数,循环遍历生成
"""
def get_pagination(self, url, id):
"""
'<a href="/news/313-1000.html" target="_self">尾页</a>'
:return: -> list
"""
try:
soup = self.get_html(url)
max_page = soup.find_all("span",class_="pages")
# 提取a标签
maxpage_num_pattern = r'<a .*?>(.*?)</a>'
max_num_val = ''
all_urls = []
for i in max_page:
#all_attr = re.findall(maxpage_pattren, str(i), re.I | re.S | re.M)
max_page_num = re.findall(maxpage_num_pattern, str(i), re.S | re.M)
#print(max_page_num)
'''
获取分页链接
通过获取最大页数(尾页),然后进行循环遍历获取生成链接,如以下
http://ask.39.net/news/313-1...1000.html
'''
for k in max_page_num:
if k == '尾页':
all_num = re.findall(r'href="(.*?)"', str(i), re.I | re.S | re.M)
# 尾页的链接,可以获取尾页id
max_num_href = all_num[len(all_num)-1]
max_num = max_num_href.replace(id,'')
# 去掉字符串的后缀,获取最大页数
max_num_val = max_num.replace('.html','')
for j in range(1, int(max_num_val)+1):
#print(j)
url_suffix = f'{id}{j}.html'
#print(url_suffix)
# 拼接链接
viurl = self.base_url + url_suffix
#print(viurl)
all_urls.append(viurl)
return all_urls
except:
pass
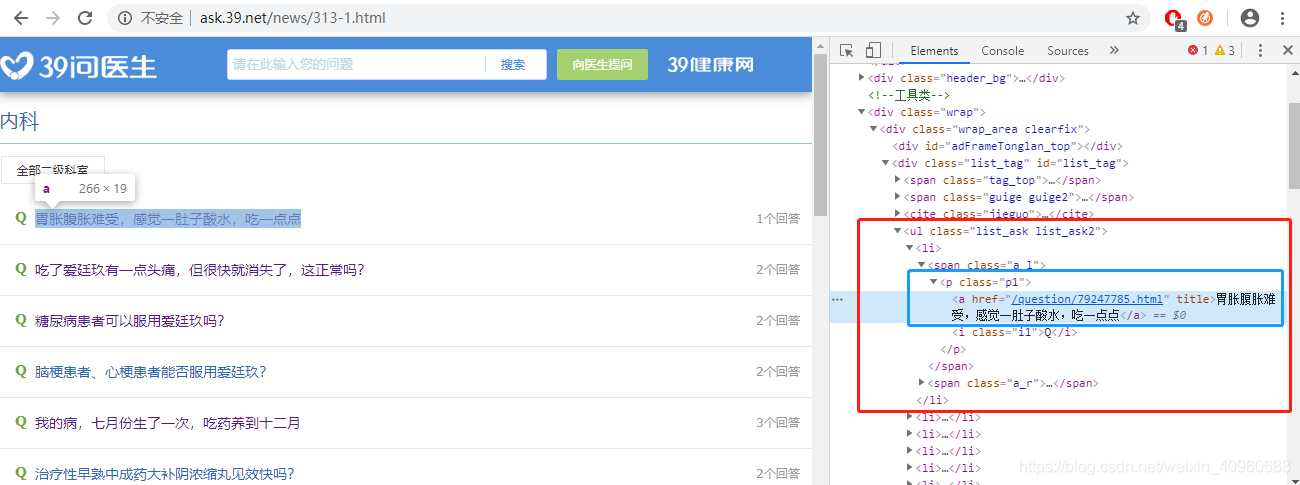
获取每个问题的URL,并将其保存在一个列表嵌套字典里面,例如:[{'title':'question_title','descript':'question_descript','anwser':'question_anwser'},{},{},....]
def get_question_title(self, url):
"""
获取问题标题,描述,以及医生精选回答
注意:问题标题与问题描述相同时取起义即可!!!
:return:
"""
back_url = []
content = {}
soup = self.get_html(url)
#print(soup)
#print(type(soup))
#规避404异常
if soup != int(404):
# try:
## 获取问题标题
#print(soup.find_all("p", class_="ask_tit"))
pattern = r'<p .*?>(.*?)</p>'
question_div = soup.find_all("p",class_="ask_tit")
#print(question_div)
if question_div != '' and question_div != []:
question_title = re.findall(pattern, str(question_div[0]), re.S | re.M)
if question_title != []:
content['title'] = question_title[0].strip()
#print(question_title.strip())
else:
content['title'] = ''
else:
back_url.append(url)
## 获取问题描述
ask_descript = soup.find_all("p",class_="txt_ms")
#print(ask_descript)
if ask_descript != '' and ask_descript != []:
question_descript = re.findall(pattern, str(ask_descript[0]), re.S | re.M)
if question_descript != []:
content['descript'] = question_descript[0].strip()
#print(question_descript.strip())
else:
content['descript'] = ''
else:
back_url.append(url)
## 获取医生精选回答
featured_answer = soup.find_all("p",class_="sele_txt")
#print(featured_answer)
if featured_answer != [] and featured_answer != '':
#print(featured_answer)
answer_content = re.findall(pattern, str(featured_answer[0]), re.S | re.M)
if answer_content != []:
content['answer'] = answer_content[0].strip()
#print(answer_content.strip())
elif featured_answer == [] or featured_answer == '':
content['answer'] = ''
else:
back_url.append(url)
back_path = r"/root/craler/back_url/bacl_url.txt"
with open(back_path, 'a+',encoding='utf-8-sig') as ft:
for urll in back_url:
ft.write(urll + '
')
return content
# except:
# self.notfound_url.append(url)
#print('保存页面发生403或者404异常的url:%s' % e)
-
第二个阶段,提取我们需要的数据
(1)提取问题标题
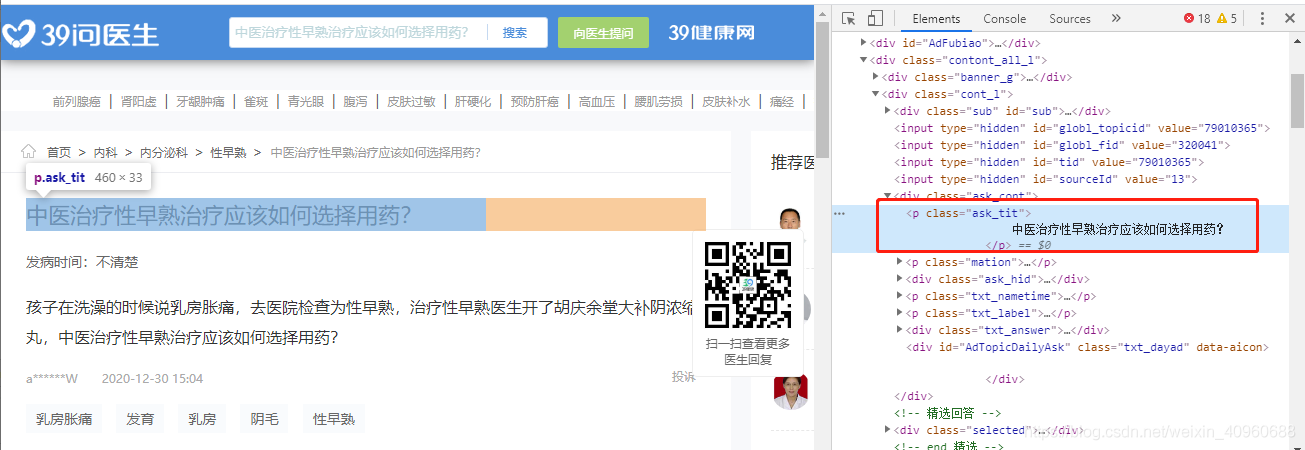
pattern = r'<p .*?>(.*?)</p>' question_div = soup.find_all("p",class_="ask_tit") question_title = re.findall(pattern, str(question_div[0]), re.S | re.M)(2)提取问题描述
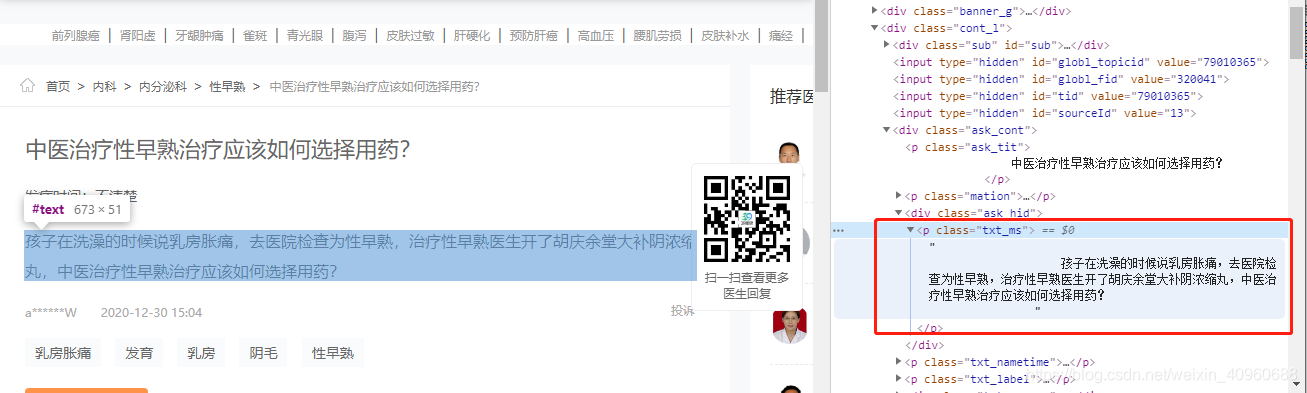
pattern = r'<p .*?>(.*?)</p>' ask_descript = soup.find_all("p",class_="txt_ms") question_descript = re.findall(pattern, str(ask_descript[0]), re.S | re.M)(3)提取问题对应的医生回答
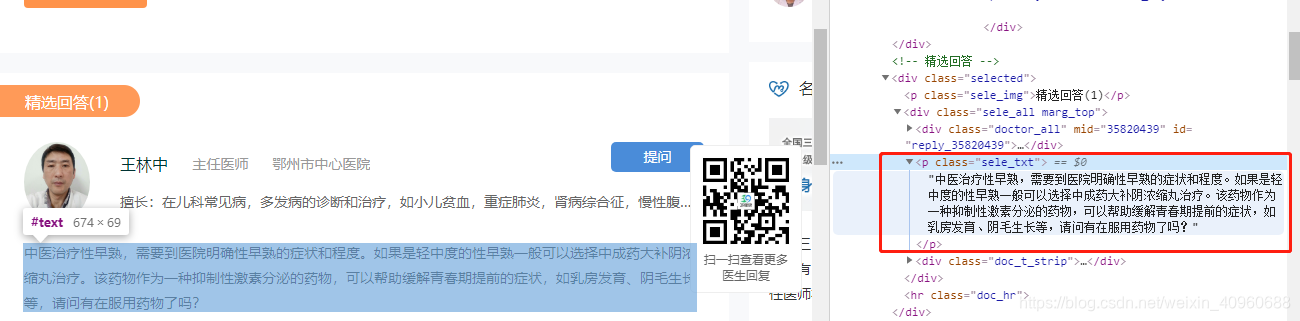
这里需要注意的是,精选医生的回答可能存在2条以上!!!pattern = r'<p .*?>(.*?)</p>' featured_answer = soup.find_all("p",class_="sele_txt") answer_content = re.findall(pattern, str(featured_answer[0]), re.S | re.M)
封装提取数据的代码如下:
def get_question_title(self, url):
"""
获取问题标题,描述,以及医生精选回答
注意:问题标题与问题描述相同时取起义即可!!!
:return:
"""
back_url = []
content = {}
soup = self.get_html(url)
time.sleep(1)
## 获取问题标题
#print(soup.find_all("p", class_="ask_tit"))
try:
pattern = r'<p .*?>(.*?)</p>'
question_div = soup.find_all("p",class_="ask_tit")
#print(question_div)
if question_div != '' and question_div != []:
question_title = re.findall(pattern, str(question_div[0]), re.S | re.M)
if question_title != []:
content['title'] = question_title[0].strip()
#print(question_title.strip())
else:
content['title'] = ''
else:
back_url.append(url)
## 获取问题描述
ask_descript = soup.find_all("p",class_="txt_ms")
#print(ask_descript)
if ask_descript != '' and ask_descript != []:
question_descript = re.findall(pattern, str(ask_descript[0]), re.S | re.M)
if question_descript != []:
content['descript'] = question_descript[0].strip()
#print(question_descript.strip())
else:
content['descript'] = ''
else:
back_url.append(url)
## 获取医生精选回答
featured_answer = soup.find_all("p",class_="sele_txt")
#print(featured_answer)
if featured_answer != [] and featured_answer != '':
#print(featured_answer)
answer_content = re.findall(pattern, str(featured_answer[0]), re.S | re.M)
if answer_content != []:
content['answer'] = answer_content[0].strip()
#print(answer_content.strip())
elif featured_answer == [] or featured_answer == '':
content['answer'] = ''
else:
back_url.append(url)
# 设置一个黑名单,将发生异常的url另存起来
back_path = r"E:HellospacesharkTT
eptiledoctoracl_url_237.txt"
with open(back_path, 'a+',encoding='utf-8-sig') as ft:
for urll in back_url:
ft.write(urll + '
')
return content
except Exception as e:
back_url.append(url)
print(e)
完整的代码
# _*_ coding: utf-8 _*_
#!/usr/bin/env python3
import re
import os
import time
import urllib3
import urllib.error
from urllib import request
from io import BytesIO
import gzip
import ssl
import socket
from bs4 import BeautifulSoup
class AskCrawler:
def __init__(self):
self.user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
self.user_headers = {
'User-Agent': self.user_agent,
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,zh-HK;q=0.8',
# 'Cookie': '_zap=f3027995-347b-41e2-8ea7-baedfcfb271c; d_c0="APCgCJrGWBCPTslzzWhr-35IDje4n2PZ_7g=|1573615549"; _ga=GA1.2.1012033787.1573799268; __utmz=51854390.1602557145.2.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmv=51854390.100--|2=registration_date=20171012=1^3=entry_date=20171012=1; __utma=51854390.1012033787.1573799268.1602640147.1603440680.6; z_c0="2|1:0|10:1604022475|4:z_c0|92:Mi4xYmtjdkJnQUFBQUFBOEtBSW1zWllFQ1lBQUFCZ0FsVk55NzZJWUFDUjFNQXpRS3dVc2hDN2VlQy16OUVhb0k0UnJB|420bfb84e913d52ee6044572021e398fc07fdf5746ef953a35d51f3483a2f0f9"; q_c1=24ee7a1427474a7298c672b83dd4a2a1|1608259725000|1573799265000; tst=h; tshl=; _xsrf=5RsypyACFL5CH2I9O46uAWSkWbID7lpR; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1610011834,1610011845,1610011864,1610074132; SESSIONID=HESvTCGzsVqwjnrqbkszJqMPwO6ran5did1c1C8uGtk; JOID=UFAXA0O62_5YcZ4XFLg7Ly4JhJkF-JSvJi_XWmzDh4UtE_pvb60bAwVxnh8eGtF59L0Xo44z1pu1sArgUwS_yY4=; osd=UFwWC0K61_9QcJ4bFbA6LyIIjJgF9JWnJy_bW2TCh4ksG_tvY6wTAgV9nxcfGt14_LwXr48715u5sQLhUwi-wY8=; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1610074164; KLBRSID=ca494ee5d16b14b649673c122ff27291|1610074212|1610074123',
'Referer': 'http://ask.39.net/',
# 'Host': 't.39.net'
}
self.base_url = 'http://ask.39.net'
self.aims_url = self.base_url + 'news/321-1.html'
self.url_pattern = r"<a.*?href=.*?</a>"
self.save_dir = r"E:Hellocrawler_adata"
# 提取访问是403,404异常的URL
#self.notfound_url = []
self.time_out = []
def get_time(self):
now_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
return now_time
def get_html(self, url):
"""
建立连接
当你urllib.urlopen一个 https 的时候会验证一次 SSL 证书
context = ssl._create_unverified_context()
:return: soup
"""
try:
context = ssl._create_unverified_context()
req = request.Request(url=url, headers=self.user_headers)
response = request.urlopen(req, timeout=30, context=context) # 设置请求超时
htmls = response.read()
buff = BytesIO(htmls)
f = gzip.GzipFile(fileobj=buff)
html = f.read().decode('utf-8',"ignore")
soup = BeautifulSoup(html, 'lxml')
return soup
#HTTPError的父类是URLError,根据经验,父类的异常应当写到子类异常的后面,如果子类捕获不到,那么可以捕获父类的异常
#如果捕获到了HTTPError,则输出code,不会再处理URLError异常。如果发生的不是HTTPError,则会去捕获URLError异常,输出错误原因。
#另外还可以加入 hasattr属性提前对属性进行判断,代码改写如下
# except urllib2.URLError, e:
#
# if hasattr(e, "code"):
# print
# e.code
#
# if hasattr(e, "reason"):
# print
# e.reason
except urllib.error.HTTPError as e:
print('http error:%s' % e.code)
return e.code
except urllib.error.URLError as e:
print('url error: %s' % e.reason)
if isinstance(e.reason, socket.timeout):
print('socket timed out - URL %s', url)
else:
print('some other error happened')
"""
分页的链接
通过获取最大页数,循环遍历生成
"""
def get_pagination(self, url):
"""
'<a href="/news/313-1000.html" target="_self">尾页</a>'
:return: -> list
"""
try:
soup = self.get_html(url)
print(soup)
max_page = soup.find_all("span",class_="pages")
maxpage_num_pattern = r'<a .*?>(.*?)</a>'
max_num_val = ''
all_urls = []
for i in max_page:
#all_attr = re.findall(maxpage_pattren, str(i), re.I | re.S | re.M)
max_page_num = re.findall(maxpage_num_pattern, str(i), re.S | re.M)
#print(max_page_num)
for k in max_page_num:
if k == '尾页':
all_num = re.findall(r'href="(.*?)"', str(i), re.I | re.S | re.M)
# 尾页的链接,可以获取尾页id
max_num_href = all_num[len(all_num)-1]
max_num = max_num_href.replace('/news/321-','')
# 最大页数
max_num_val = max_num.replace('.html','')
for j in range(1, int(max_num_val)+1):
#print(j)
url_suffix = f'/news/321-{j}.html'
#print(url_suffix)
viurl = self.base_url + url_suffix
#print(viurl)
all_urls.append(viurl)
#print(all_urls)
return all_urls
except:
pass
def get_all_question_url(self, url):
"""
获取所有的问题标题与问题id
:return:
"""
try:
# req = request.Request(url=url,headers=self.user_headers)
# response = request.urlopen(req)
# '''
# 问题:
# UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte
# 解决方案:
# htmls = response.read()
# buff = BytesIO(htmls)
# f = gzip.GzipFile(fileobj=buff)
# html = f.read().decode('utf-8')
# '''
#
# htmls = response.read()
# buff = BytesIO(htmls)
# f = gzip.GzipFile(fileobj=buff)
# html = f.read().decode('utf-8')
#
# soup = BeautifulSoup(html,'lxml')
soup = self.get_html(url)
pageurls = []
# 获取ul标签内的所有下级节点标签
pageurl=soup.find_all("ul",class_="list_ask list_ask2")
# 正则表达式匹配规则
link_pattern = r"<a.*?href=.*?</a>"
title_pattern = r'<a .*?>(.*?)</a>'
href_pattern = r'href="(.*?)"'
for i in pageurl:
try:
# 获取a标签完整内容
all_attr = re.findall(link_pattern, str(i), re.I | re.S | re.M)
for k in all_attr:
Upageurls = {}
# 获取标题
title = re.findall(title_pattern, k, re.S | re.M)[0]
# 获取href
url_suffix = re.findall(href_pattern, k, re.I | re.S | re.M)[0]
Upageurls['title'] = title
Upageurls['url'] = self.base_url + url_suffix
print(Upageurls)
pageurls.append(Upageurls)
except Exception as e:
print(e)
#print(pageurls)
return pageurls
except urllib3.exceptions.HTTPError as e:
print('网络异常 - %s' % e)
def save_url(self, base_url, filename):
"""
将组成的url保存到文本
:param:path - 保存文本的名称
:return:
"""
base_url = self.get_pagination(base_url)
print(base_url)
content = ''
with open(os.path.join(self.save_dir, filename), 'a+', encoding='utf-8-sig') as f:
for url_one in base_url:
print(url_one)
content = self.get_all_question_url(url_one)
for dict_one in content:
f.write(dict_one['title'] + ' ' + dict_one['url'] + '
')
print(dict_one['title'] + ' ' + dict_one['url'] + '
')
def get_question_title(self, url):
"""
获取问题标题,描述,以及医生精选回答
注意:问题标题与问题描述相同时取起义即可!!!
:return:
"""
back_url = []
content = {}
try:
soup = self.get_html(url)
#print(soup)
#print(type(soup))
# 避免网页DOM没有加载出来,获取不到html的标签
time.sleep(1)
if soup != int(404):
# try:
## 获取问题标题
#print(soup.find_all("p", class_="ask_tit"))
pattern = r'<p .*?>(.*?)</p>'
question_div = soup.find_all("p",class_="ask_tit")
#print(question_div)
if question_div != '' and question_div != []:
question_title = re.findall(pattern, str(question_div[0]), re.S | re.M)
if question_title != []:
content['title'] = question_title[0].strip()
#print(question_title.strip())
else:
content['title'] = ''
else:
back_url.append(url)
## 获取问题描述
ask_descript = soup.find_all("p",class_="txt_ms")
#print(ask_descript)
if ask_descript != '' and ask_descript != []:
question_descript = re.findall(pattern, str(ask_descript[0]), re.S | re.M)
if question_descript != []:
content['descript'] = question_descript[0].strip()
#print(question_descript.strip())
else:
content['descript'] = ''
else:
back_url.append(url)
## 获取医生精选回答
featured_answer = soup.find_all("p",class_="sele_txt")
#print(featured_answer)
if featured_answer != [] and featured_answer != '':
#print(featured_answer)
answer_content = re.findall(pattern, str(featured_answer[0]), re.S | re.M)
if answer_content != []:
content['answer'] = answer_content[0].strip()
#print(answer_content.strip())
elif featured_answer == [] or featured_answer == '':
content['answer'] = ''
else:
back_url.append(url)
back_path = r"/root/craler/back_url/bacl_url.txt"
with open(back_path, 'a+',encoding='utf-8-sig') as ft:
for urll in back_url:
ft.write(urll + '
')
return content
else:
pass
# 处理请求超时的异常处理,规避脚本直接退出运行;并且将其URL存储起来,方便后续爬取这些数据
except socket.timeout as e:
print('socket timed out - URL :%s', url)
self.time_out.append(url)
# except:
# self.notfound_url.append(url)
#print('保存页面发生403或者404异常的url:%s' % e)
@staticmethod
def _load_text_file(txt_file):
"""
加载text文件
:param txt_file:
:return:
"""
text_content = []
with open(txt_file, 'r', encoding='utf-8-sig') as text_file:
while True:
content = text_file.readline()
if not content:
break
line = content.strip('
')
text_content.append(line)
# FileUtils._check_format(txt_file, text_content)
return text_content
def save_ask_content(self, url_dir, save_dir):
base_url = self._load_text_file(url_dir)
with open(save_dir, 'a+', encoding='utf-8-sig') as f:
for url in base_url:
#print(url.split(' ',1)[1])
ask_url = url.rsplit(' ', 1)[1]
print(ask_url)
# 获取内容
ask_content = self.get_question_title(ask_url)
#print(ask_content)
"""
len(ask_content)=0 是正确的,却不能用 if len(ask_content)>0:
报错:TypeError: object of type 'NoneType' has no len()
仔细分析,发现ask_content 是一个tuple类型的数组
当ask_content是空的时候,同样不能用ask_content[0] = 'None' 判断,
能判断ask_content为空的方法只有 if ask_content!=‘’ 来判断
"""
if ask_content != '' and ask_content != None:
f.write(
ask_content.get('title', '') + '
' + ask_content.get('descript', '') + '
' + ask_content.get(
'answer', '') + '
')
print(
ask_content.get('title', '') + '
' + ask_content.get('descript', '') + '
' + ask_content.get(
'answer', '') + '
')
# 避免访问过于频繁
time.sleep(1)
if __name__ == '__main__':
app = AskCrawler()
##
# base_url = 'http://ask.39.net/news/321-1.html'
# app.save_url(base_url, 'question_urls_321.txt')
# 小儿内科
url_path = r"/root/craler/data_question_url/question_url_1.txt"
save_dir = r"/root/craler/result/question_anwser_45.txt"
app.save_ask_content(url_path, save_dir)
print(app.get_time())
# 儿科
url_path = r"/root/craler/data_question_url/question_urls_2.txt"
save_dir = r"/root/craler/result/question_anwser_309.txt"
app.save_ask_content(url_path, save_dir)
print(app.get_time())
# 小儿精神科
url_path = r"/root/craler/data_question_url/question_urls.txt"
save_dir = r"/root/craler/resultquestion_anwser_3159.txt"
app.save_ask_content(url_path, save_dir)
print(app.get_time())
知识补充
beautifulsoup的简单介绍
beautifulsoup 是python爬虫中针对HTML,XML的其中一个解析工具,为了便于提取页面我们需要的数据,我们不得不对beautifulsoup有更深入的了解;
beautifulsoup 为我们提供了以下四种解析器:
-
标准库
soup = BeautifulSoup(content, "html.parser") -
lxml解析器
soup = BeautifulSoup(content,"lxml") -
xml解析器
soup = BeautifulSoup(content."xml") -
html5lib解析器
soup = BeautifulSoup(content, "html5lib")
在以上四种解析器库中,lxml解析器具有解析速度块兼容错能力强的merits;
节点选择
在Beautiful Soup中,我们可以很方便的选择想要得到的节点,只需要在soup对象中使用.`的方式即可,使用如下:
title_bj = soup.title
title_bj_name = soup.title.name
title_name = soup.title.string
title_parent_bj_name = soup.title.parent.name
image_bj = soup.img
image_bj_dic = soup.img.attrs
image_all = soup.find_all("img")
image_idlg = soup.find("div", id="lg")
image_classlg = soup.find_all("div", class_="lg")
soup.title,正如前面所说,Beautiful Soup可以很简单的解析对应的页面,只需要使用soup.的方式进行选择节点即可,该行代码正是获得百度首页html的title节点内容soup.title.name,使用.name的形式即可获取节点的名称- soup.title.string,使用
.string的形式即可获得节点当中的内容,这句代码就是获取百度首页的title节点的内容,即浏览器导航条中所显示的百度一下,你就知道 soup.title.parent.name,使用.parent可以该节点的父节点,通俗地讲就是该节点所对应的上一层节点,然后使用.name获取父节点名称soup.img,如soup.title一样,该代码获取的是img节点,只不过需要注意的是:在上面html中我们可以看见总共有两个img节点,而如果使用.img的话默认是获取html中的第一个img节点,而不是所有soup.img.attrs,获取img节点中所有的属性及属性内容,该代码输出的结果是一个键值对的字典格式,所以之后我们只需要通过字典的操作来获取属性所对应的内容即可。比如soup.img.attrs.get("src")和soup.img.attrs["src"]的方式来获取img节点所对应的src属性的内容,即图片链接soup.find_all("img"),在上述中的.img操作默认只能获取第一个img节点,而要想获取html中所有的img节点,我们需要使用.find_all("img")方法,所返回的是一个列表格式,列表内容为所有的选择的节点soup.find("div", id="lg"),在实际运用中,我们往往会选择指定的节点,这个时候我们可以使用.find()方法,里面可传入所需查找节点的属性,这里需要注意的是:在传入class属性的时候其中的写法是.find("div", class_="XXX")的方式。所以该行代码表示的是获取id属性为lg的div节点,此外,在上面的.find_all()同样可以使用该方法来获取指定属性所对应的所有节点
数据提取
.get_text()
获取对象中所有的内容:
all_content = soup.get_text()
.strings,.stripped_strings
print(type(bd_soup.strings))
.strings用于提取bd_soup对象中所有的内容,而从上面的输出结果我们可以看出.strings的类型是一个生成器,对此可以使用循环来提取出其中的内容。但是我们在使用.strings的过程中会发现提取出来的内容有很多的空格以及换行,对此我们可以使用.stripped_strings方法来解决该问题,用法如下:
for each in soup.stripped_strings:
print(each)
.parent,.children,.parents
.parent可以选择该节点的父节点,.children可以选择该节点的孩子节点,.parents选择该节点所有的上层节店,返回的是生成器,各用法如下:
bd_div_bj = soup.find("div", id="u1")
print(type(div_bj.parent))
print("*" * 50)
for child in div_bj.children:
print(child)
print("*" * 50)
for parent in div_bj.parents:
print(parent.name)