说实话,爬虫对于我来说还是很神秘的,对爬虫的学习动力,可能仅仅是因为能够快速的在校花网上爬取一些妹子图片,或者是完成自己的作业任务,还有可能是因为或许以后可以通过爬虫为自己爬来一碗口粮。。。。哎,不想了!管他呢
爬虫
百度百科定义:
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
自己定义:一只有饥肠辘辘的蜘蛛在一张蜘蛛网上瞎转悠找吃的,找吃的同时找和其他蜘蛛网连接的蜘蛛丝,,如果找到相连的蜘蛛丝的话,就派手下的小弟去这个网上找吃的,就这样一层一层的找,如果小弟有找到的就拿回来
Scrapy
既然爬虫早就出现了,那肯定就有一些好心前辈们的呕心沥血总结,So,那我就先拿来用用。。哈哈
Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
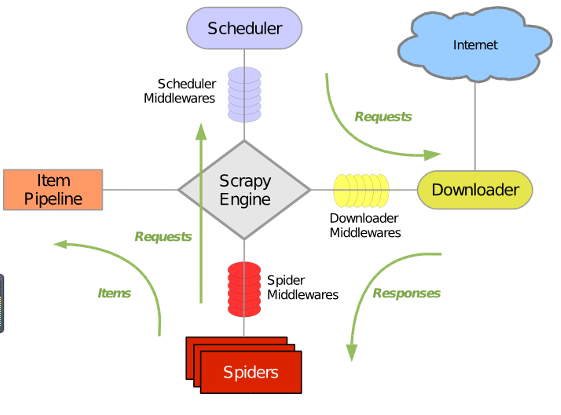
Scrapy主要包括了以下组件: 引擎(Scrapy) 用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler) 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 下载器(Downloader) 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) 爬虫(Spiders) 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 项目管道(Pipeline) 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 下载器中间件(Downloader Middlewares) 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 爬虫中间件(Spider Middlewares) 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 调度中间件(Scheduler Middewares) 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
1.引擎从调度器中取出一个链接(URL)用于接下来的抓取
2.引擎把URL封装成一个请求(Request)传给下载器
3.下载器把资源下载下来,并封装成应答包(Response)
4.爬虫解析Response
5.解析出实体(Item),则交给实体管道进行进一步的处理
6.解析出的是链接(URL),则把URL交给调度器等待抓取
一、安装
pip install Scrapy
注:windows平台需要依赖pywin32,请根据自己系统32/64位选择下载安装,https://sourceforge.net/projects/pywin32/
二、基本使用
1、创建项目
运行命令:
scrapy startproject your_project_name
这个命令会在当前目录下创建一个新目录,它的结构如下:
project_name:
│
│ scrapy.cfg
│
└─project_name
│ items.py
│ pipelines.py
│ settings.py
│ __init__.py
│
└─spiders
__init__.py
文件说明:
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
2、编写爬虫
在spiders目录中新建 xiaohuar_spider.py 文件
 xiaohuar_spider.py
xiaohuar_spider.py3、运行
进入project_name目录,运行命令
scrapy crawl spider_name --nolog
4、递归的访问
以上的爬虫仅仅是爬去初始页,而我们爬虫是需要源源不断的执行下去,直到所有的网页被执行完毕
View Code以上代码将符合规则的页面中的图片保存在指定目录,并且在HTML源码中找到所有的其他 a 标签的href属性,从而“递归”的执行下去,直到所有的页面都被访问过为止。以上代码之所以可以进行“递归”的访问相关URL,关键在于parse方法使用了 yield Request对象。
注:可以修改settings.py 中的配置文件,以此来指定“递归”的层数,如: DEPTH_LIMIT = 1
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import scrapy
from scrapy.selector import HtmlXPathSelector
class XiaoHuarSpider(scrapy.spiders.Spider):
name = "s1"
allowed_domains = ["xiaohuar.com"]
start_urls = [
"http://www.beautyleg.com/list_album.php",
]
def parse(self, response):
hxs = HtmlXPathSelector(response)
items = hxs.select('//table//img/@src')
print items
下面俩中获取的方法相同,推荐使用下面的那种:
hxs = HtmlXPathSelector(response)
items = hxs.select('//table//img/@src')
print items
from scrapy.selector import Selector
ret = Selector(response=response).xpath('//table//img/@src').extract()
print ret
获取内容:
//div[@class='item_list'] 表示找到所有的div下属性为class='item_list'的 //div[@class='item_list']/div 表示找到这个div的所有儿子 //div[@class='item_list']//span 表示找在这个div下的子子孙孙中的所有span标签 //div[@class='item_list']//a/text() 表示找在这个div下的子子孙孙中的所有a标签并获得所有a标签的内容 //div[@class='item_list']//img/@src 表示找在这个div下的子子孙孙中的所有img标签并获得所有img标签的src属性
正则选择器 选择器规则 获取响应cookies5、格式化处理
上述实例只是简单的图片处理,所以在parse方法中直接处理。如果对于想要获取更多的数据(获取页面的价格、商品名称、QQ等),则可以利用Scrapy的items将数据格式化,然后统一交由pipelines来处理。
在items.py中创建类:
# -*- coding: utf-8 -*- # Define here the models for your scraped items # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy class JieYiCaiItem(scrapy.Item):
company = scrapy.Field() title = scrapy.Field() qq = scrapy.Field() info = scrapy.Field() more = scrapy.Field()
上述定义模板,以后对于从请求的源码中获取的数据同意按照此结构来获取,所以在spider中需要有一下操作:
spilder此处代码的关键在于:
- 将获取的数据封装在了Item对象中
- yield Item对象 (一旦parse中执行yield Item对象,则自动将该对象交个pipelines的类来处理)
pipelines上述中的pipelines中有多个类,到底Scapy会自动执行那个?哈哈哈哈,当然需要先配置了,不然Scapy就蒙逼了。。。
在settings.py中做如下配置:
ITEM_PIPELINES = {
'beauty.pipelines.DBPipeline': 300,
'beauty.pipelines.JsonPipeline': 100,
}
# 每行后面的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内。