Day3:
只需两行代码解析html或xml信息 具体代码实现:day3_1 注意BeautifulSoup的B和S需要大写,因为python大小写敏感
import requests
r= requests.get("http://python123.io/ws/demo.html")
r.text
demo = r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo , "html.parser")
print(soup.prettify())
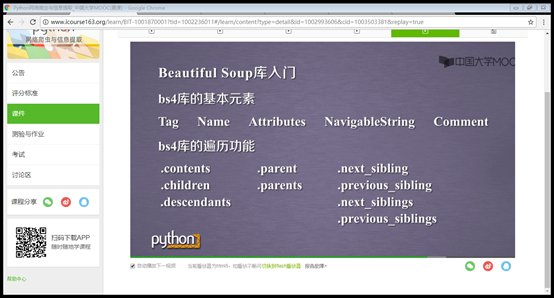
BeautifulSoup库的基本元素:详参html的基本信息
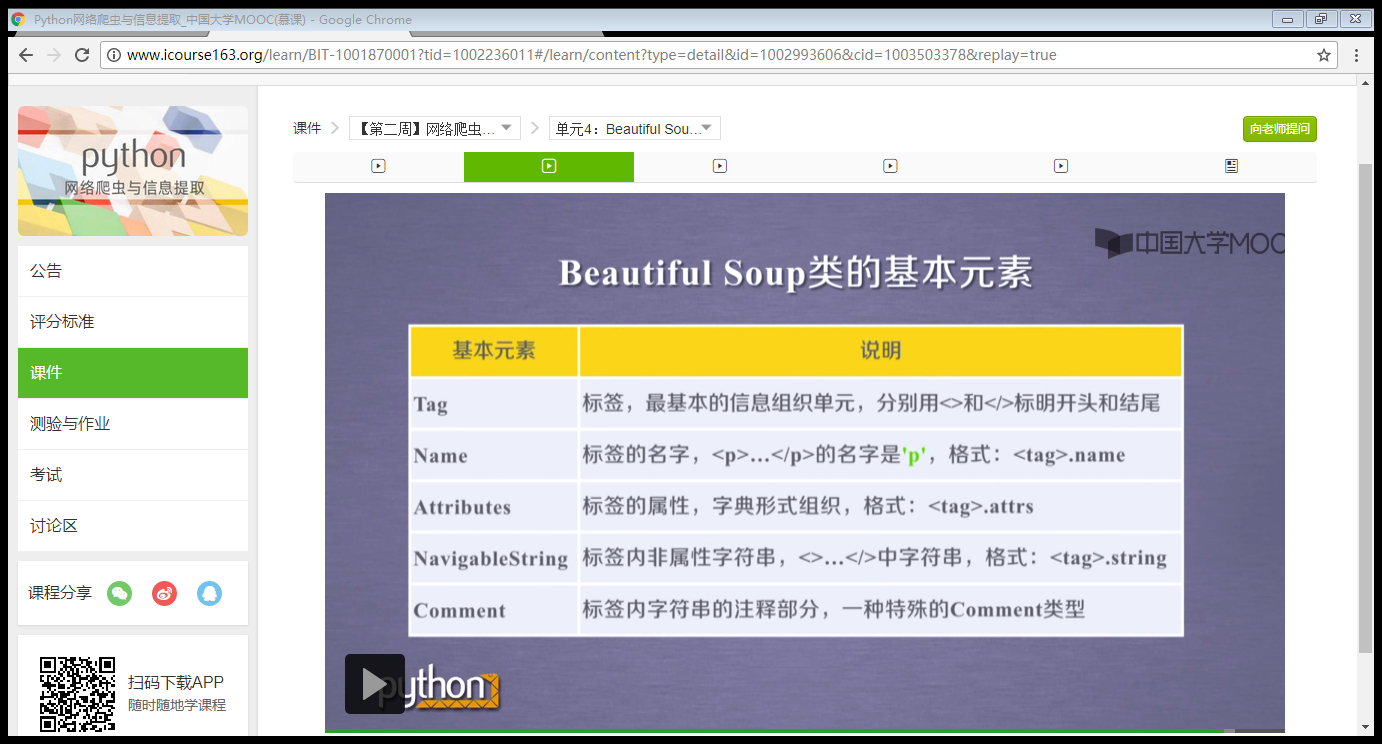
from bs4 import BeautifulSoup 语句含义:从bs4库中引入一个BeautifulSoup的类型

下行遍历,上行遍历和平行遍历:
爬取中国大学排名
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
print("{:^10} {:^6} {:^10}".format("排名","学校名称","总分"))
for i in range(num):
u=ulist[i]
print("{:^10} {:^6} {:^10}".format(u[0],u[1],u[2]))
def main():
uinfo = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univs
main()