Day2:
查看robots协议:
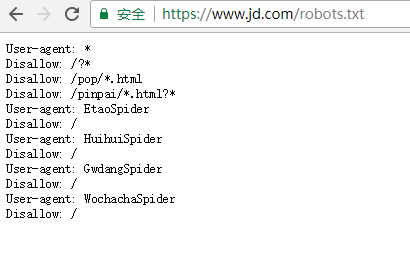
查看京东的robots协议
查看百度的robots协议,可以看到百度拒绝了搜狗的爬虫233

爬取京东商品页面相关信息:
import requests url = "https://item.jd.hk/1974631870.html" try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding print(r.text[:1000]) except: print("产生异常")

爬取亚马逊商品页面相关信息:
由于亚马逊拒绝爬虫访问,所以需要更改header的值,将python伪装成浏览器访问
import requests url = "https://www.amazon.cn/dp/B0186FESGW/ref=fs_kin" try: kv = { 'user-agent':'Mozilla/5.0'} r = requests.get(url,headers = kv) r.status_code r.raise_for_status() r.encoding = r.apparent_encoding print(r.text[:1000]) except: print("产生异常")

爬取百度关键词查询结果 : 本例关键词为python
1 import requests 2 keyword = "python" 3 try: 4 kv = {'wd':keyword} 5 r = requests.get("http://www.baidu.com/s",params=kv) 6 print(r.request.url) 7 r.raise_for_status() 8 print(len(r.text)) 9 10 except: 11 print("爬取失败")
网络图片,视频等二进制文件的爬取和保存:
import requests import os url = "http://image.nationalgeographic.com.cn/2017/0819/20170819021922613.jpg" root = "f://pics//" path = root + url.split('/')[-1] try: if not os.path.exists(root): #处理根目录是否存在问题 os.mkdir(root) if not os.path.exists(path): #处理文件是否存在问题 kv = { 'user-agent':'Mozilla/5.0'} r = requests.get(url,headers = kv) r.status_code with open(path,'wb') as f: f.write(r.content)#r.content为二进制形式 f.close() print("文件保存成功") else: print("文件已存在") except: print("爬取失败")
Ip地址归属地的查询:
import requests url = "http://m.ip138.com/ip.asp?ip=" try: r=requests.get(url+'202.204.80.112') r.raise_for_status() r.encoding = r.apparent_encoding print(r.text[-500:]) except: print("爬取失败")
