论数据分片技术及其应用
信1805-2班 20183583 张志伟
数据分片就是按照一定的规则,将数据集划分成相互独立正交的数据子集。然后将数据子集分布到不同的节点上,通过设计合理的数据分片规则,可将系统中的数据分布在不同的物理数据库中,达到提升应用系统数据处理速度的目的。在解决数据库日志解析的问题中,我承担了进行数据分片的任务。
数据分片,就是依照分片算法将数据打散到多个不同的节点上,每个节点上存储部分数据。一般来说,分片算法最常见的就是Hash分片、一致性Hash分片和按照范围数据分片三种。下面将对这三种分片技术进行简单的阐释,并介绍在数据库日志解析中采用的分片方式。
Hash分片
Hash 分片的算法就是对缓存的 Key 做哈希计算,然后对总的缓存节点个数取余。你可以这么理解:比如说,我们部署了三个缓存节点组成一个缓存的集群,当有新的数据要写入时,我们先对这个缓存的 Key 做比如 crc32 等 Hash 算法生成 Hash 值,然后对 Hash 值模 3,得出的结果就是要存入缓存节点的序号。
这个算法最大的优点就是简单易理解,缺点是当增加或者减少缓存节点时,缓存总的节点个数变化造成计算出来的节点发生变化,从而造成缓存失效不可用。所以我建议你,如果采用这种方法,最好建立在你对于这组缓存命中率下降不敏感,比如下面还有另外一层缓存来兜底的情况下。那有没有更好的方案能解决这个问题呢?那就是一致性 Hash 分片算法。
一致性Hash分片
用一致性 Hash 算法可以很好地解决增加和删减节点时,命中率下降的问题。在这个算法中,我们将整个 Hash 值空间组织成一个虚拟的圆环,然后将缓存节点的 IP 地址或者主机名做 Hash 取值后,放置在这个圆环上。当我们需要确定某一个 Key 需要存取到哪个节点上的时候,先对这个 Key 做同样的 Hash 取值,确定在环上的位置,然后按照顺时针方向在环上“行走”,遇到的第一个缓存节点就是要访问的节点。比方说下面这张图里面,Key 1 和 Key 2 会落入到 Node 1 中,Key 3、Key 4 会落入到 Node 2 中,Key 5 落入到 Node 3 中,Key 6 落入到 Node 4 中。
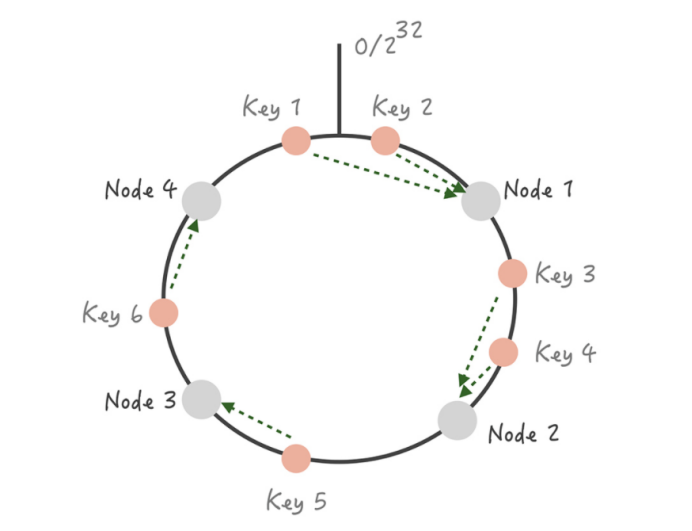
这时如果在 Node 1 和 Node 2 之间增加一个 Node 5,你可以看到原本命中 Node 2 的 Key 3 现在命中到 Node 5,而其它的 Key 都没有变化;同样的道理,如果我们把 Node 3 从集群中移除,那么只会影响到 Key 5 。所以你看,在增加和删除节点时,只有少量的 Key 会 漂移 到其它节点上,而大部分的 Key 命中的节点还是会保持不变,从而可以保证命中率不会大幅下降。
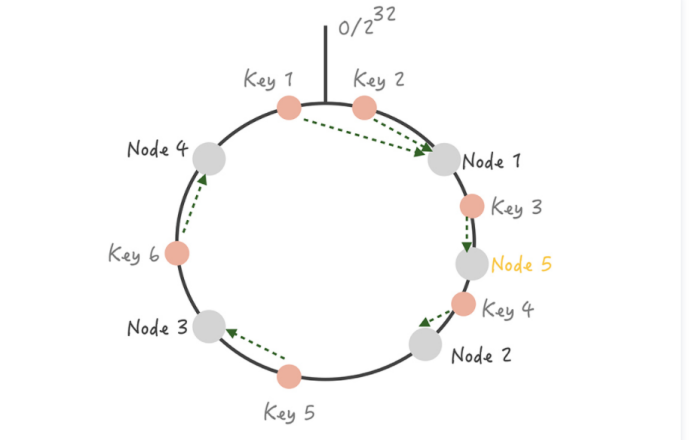
不过,事物总有两面性。虽然这个算法对命中率的影响比较小,但它还是存在问题:
- 缓存节点在圆环上分布不平均,会造成部分缓存节点的压力较大;
- 当某个节点故障时,这个节点所要承担的所有访问都会被顺移到另一个节点上,会对后面这个节点造成压力。
按照数据范围分片
常见场景就是按照 时间区间 或 ID区间 来切分。例如:按日期将不同月甚至是日的数据分散到不同的库中;将 userId 为 1~9999 的记录分到第一个库, 10000~20000 的分到第二个库,以此类推。某种意义上,某些系统中使用的 "冷热数据分离" ,将一些使用较少的历史数据迁移到其他库中,业务功能上只提供热点数据的查询,也是类似的实践。
这样的优点在于: - 单表大小可控
- 天然便于水平扩展,后期如果想对整个分片集群扩容时,只需要添加节点即可,无需对其他分片的数据进行迁移
- 使用分片字段进行范围查找时,连续分片可快速定位分片进行快速查询,有效避免跨分片查询的问题。
缺点: - 热点数据成为性能瓶颈。连续分片可能存在数据热点,例如按时间字段分片,有些分片存储最近时间段内的数据,可能会被频繁的读写,而有些分片存储的历史数据,则很少被查询。
数据库日志解析进行分片
在解析数据库日志的过程中,为了提高日志数据的解析和查找效率,也要进行分片。查找日志的过程中有一些关键的变量数值:事务日志的唯一标识就是TransactionID,事务的操作类型Operation主要是分为增删改三类,AllocUnitName是事务操作的数据表名称,再有就是事务的开始时间BeginTime和结束时间EndTime。在进行分片时,可以采用的分片技术有三种:Hash分片、一致性Hash分片和按照数据范围分片。
在进行日志分析时,假定要使用Hash分片,那么可以根据TransactionID进行分片,但这样分片的意义并不大,因为只是单纯的将数据分开,但并没有方便后续的查找和分析。我们最终采用的是按照数据范围分片,首先,可以按照时间段进行分片,因为如果最终要做成一个数据库同步软件,我们需要做的工作,是要在能够解析日志的基础上加上定时任务,按照时间段进行分片,可以说是将每次同步的任务单独存放,这样分片不仅减小了每个分片的数据量,也方便后续出现问题时,进行按照任务进行排查,也便于统计每次任务所完成的数据量,操作类型。亦或是按照操作类型进行分片,将增删改的分别单独存放,这样的类型区分明显,降低了后续统计的工作量。也可以按照所操作的表进行分片,方便在进行数据增量同步时直接在对应的表进行操作,也可以给每一个表设置一个线程,提高效率。
综合上面的几种设想,在最终进行数据分片时,先按照时间段进行划分,也就是每次的同步任务是一个分片,在此基础上按照所操作的表对象进行分,然后在按照操作类型分,这样分完之后,单个分片的数据量大大减少,在进行查询统计时,也可以根据需要来对这些小的分片按照需要进行组合,直接得到大部分想要的结果,大幅提高了执行效率。
小结
数据分片可以提高程序的可扩展性,提高性能,从而能够支持起更加庞大的数据规模,当然分片也有不好的地方,因为数据进行了分片导致了数据过于分散,在进行数据备份和迁移时就会耗费更大的精力。