内容
一、一个大查询与多个小查询的抉择
1、查询拆分后,锁竞争较少
2、更加容易分库分表
3、
二、explain的参数
type:有all(全表扫描),ref(使用索引)等;
rows:扫描的行数;
extra:Using where (通过where条件筛选引擎返回的记录),using index(索引覆盖);
mysql使用where条件的3个场景(以次从好到坏):
1、在索引中使用where条件过滤不匹配的值,这实在引擎层实现的;
2、使用索引覆盖(using index),服务器完成;
3、在引擎层加载数据,然后在服务层过滤数据;
发出sql后,数据库都干了什么事情:
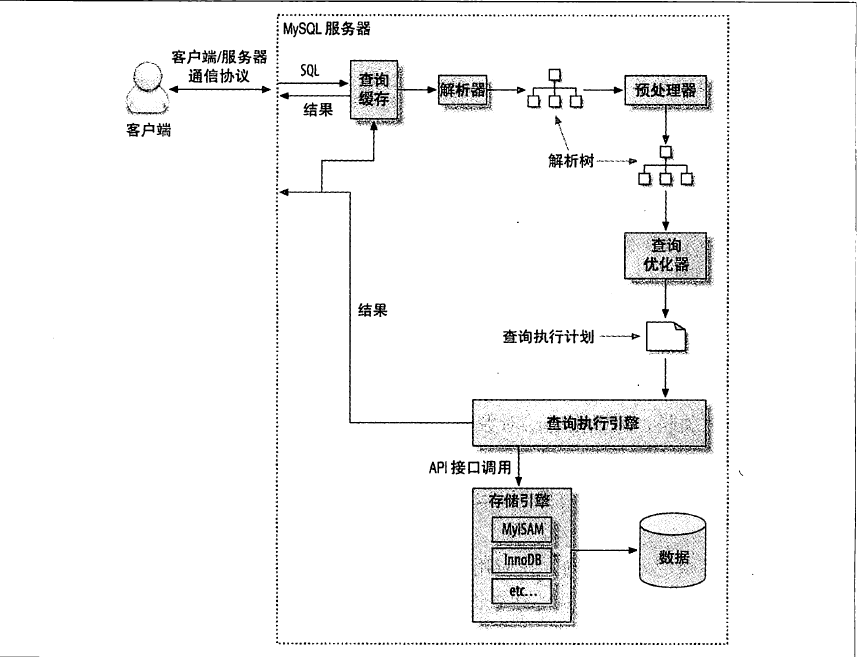
1、客服端发送一条查询给数据库;
2、有缓存则直接返回,没有则继续;
3、SQL解析,预处理,再由优化器生成相应的执行计划;
4、根据执行计划,调用储存引擎的api;
5、讲结果返回给客户端;
排序优化
1、讲结果返回给客户端;
快速、精确、简单,你永远只能实现其中2个;
优化关联查询:
对于select * from a join b on a.xid =b.xid;
1、确保b表在xid列上有索引,
2、group by a表的列
优化limit查询:
对于select id,name from table order by title limit 50,5;
可以改为:
select c1.id,c1.name from table c1 inner join (select a.id from table order by title limit 50,5) as c2 on c1.id =c2.id;