6.0 ZooKeeper 系统模型
1)数据模型
和unix系统类似的树状结构。每一个数据节点成为ZNode,可以向节点中写入数据、也可以在节点下创建子节点

2)节点类型
-
持久节点(PERSISTENT):客户端与zookeeper断开连接后,该节点依旧存在
-
持久顺序节点(PERSISTENT_SEQUENTIAL): 客户端与zookeeper断开连接后,该节点依旧存在,zookeeper给该节点名称进行顺序编号
-
临时节点(EPHEMERAL):客户端与zookeeper断开连接后,删除该节点
-
临时顺序节点(EPHEMERAL_SEQUENTIAL): 客户端与zookeeper断开连接后,删除该节点,zookeeper给该节点名称进行顺序编号
3)Watcher——数据变更通知
客户端注册Watcher监听,服务端发生特定事件时,会向客户端发送事件通知
事件类型(znode节点相关):
①EventType.NodeCreated:节点创建
②EventType.NodeDataChanged:节点数据变更
③EventType.NodeChildrenChanged:子节点变更(子节点列表发生变更,即新增子节点或删除子节点,子节点内容的变化不会触发这个事件)
④EventType.NodeDeleted:节点删除
状态类型(客户端实例相关):
①KeeperState.Disconnected:未连接
②KeeperState.SyncConnected:已连接
③KeeperState.AuthFailed:认证失败
④KeeperState.Expired:会话失效
6.1 Zookeeper的应用场景
1)统一命名服务
命名服务(Name Service):在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。
常见的分布式服务框架(如RPC)中的注册中心,通过使用命名服务,实现服务注册、服务发现功能。
a.服务注册:服务提供者启动后,在相应服务节点下创建子节点。
b.服务发现:客户端能够根据名字获取服务提供者的ip地址列表,监听后能够获知服务提供者ip地址列表变化。
2)统一配置管理
分布式环境下,配置文件的同步非常常见。
(1)一般要求一个集群中,所有节点的配置信息是一致的,比如Kafka集群。
(2)对配置文件修改后,希望能够快速同步到各个节点上。
zookeeper实现统一配置管理
(1)将配置信息写入zookeeper上的一个节点
(2)服务启动时,从节点获取配置信息;并监听这个节点的内容变化,当节点内容发生变化,将受到通知

3)统一集群管理
分布式环境下,实时掌握每个节点的运行状态是非常有必要的。
我们可根据节点实时状态做出一些调整。
zookeeper实现统一集群管理
(1)服务将自身状态信息写入zookeeper的一个节点。
(2)监听这个节点可获取它的实时状态变化。
在线云主机管理
-
如何快速的统计出当前生产环境一共有多少台机器?
-
如何快速的获取到机器上/下线的情况?
-
如何实时监控集群中每台主机的运行时状态?
机器上下线
机器上线:向zookeeper上注册临时节点,监控中心可接收到”子节点变更“通知
机器下线:临时节点删除,监控中心同样可接收到”子节点变更”通知
机器监控
Agent定时将主机的运行状态信息写入相应节点,监控中心订阅节点变更获取到机器运行状态。
4)Master选举
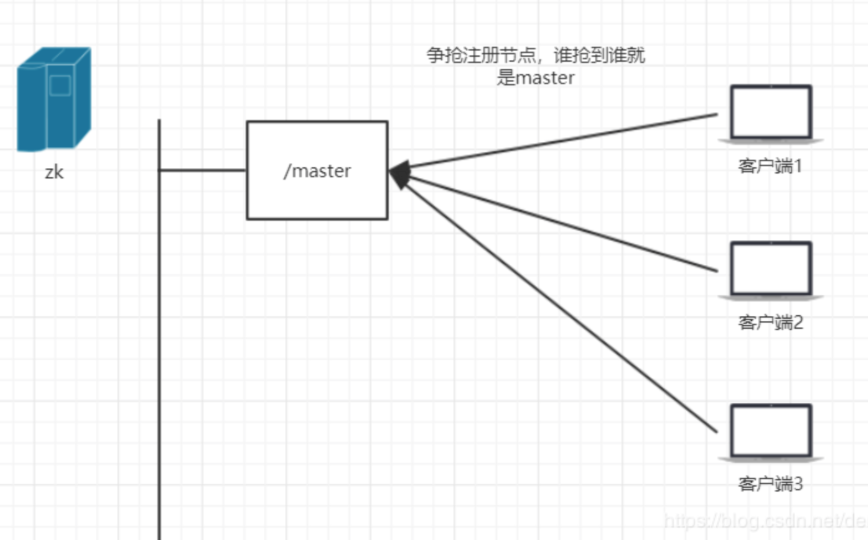
所有机器尝试创建master节点(临时节点),只会有一台机器创建成功,这台机器就成为了Master,将自己的ip等信息写入master节点,其他机器就能够知道当前集群中谁是master了。
其他机器在master上注册监听,用于监控当前的master是否存活,一旦发现当前的master挂了,重新进行master选举。
5)分布式锁
5.1)排它锁
排他锁(Exclusive Locks,X锁)或称为写锁/独占锁:事务T1对数据对象O1加上了排他锁,整个加锁期间,仅T1可以对O1进行操作,直到T1释放了排他锁。
实现排他锁的核心
1)如果保证当前有且仅有一个事务获得锁
2)锁被释放后,所有等待锁的事务都能够被通知到
使用Zookeeper如何实现排他锁?
定义锁
Zookeeper上的数据节点来表示一个锁,如/exclusive_lock/lock

获得锁
所有的客户端尝试在/exclusive_lock节点下创建临时子节点/exclusive_lock/lock。
Zookeeper会保证在所有客户端中,最终仅有一个客户端能够创建成功,则认为该客户端获取了锁。
同时,所有没有获得锁的客户端在/exclusive_lock节点上注册一个子节点变更的Watcher监听,以便实时监听lock节点变更情况。
释放锁
/exclusive_lock/lock是一个临时节点,以下两种情况下会释放锁
-
当前持有锁的客户端机器发生宕机,代表锁的临时节点将会被移除
-
当前持有锁的客户端正常执行完业务逻辑后,主动将自己创建的临时节点删除
/exclusive_lock/lock被删除后,所有在/exclusive_lock节点上注册子节点变更Watcher监听的客户端都会收到通知。
收到通知后,重新发起获取锁流程。
排他锁获取和释放的整个流程如下。

5.2)共享锁
共享锁(Shared Locks,S锁),或称为读锁:事务T1对数据对象加上了共享锁,当前事务只能对O1进行读操作,其他事务也只能对这个数据对象加共享锁,直到该数据对象上所有共享锁被释放。
使用Zookeeper如何实现共享锁?
定义锁
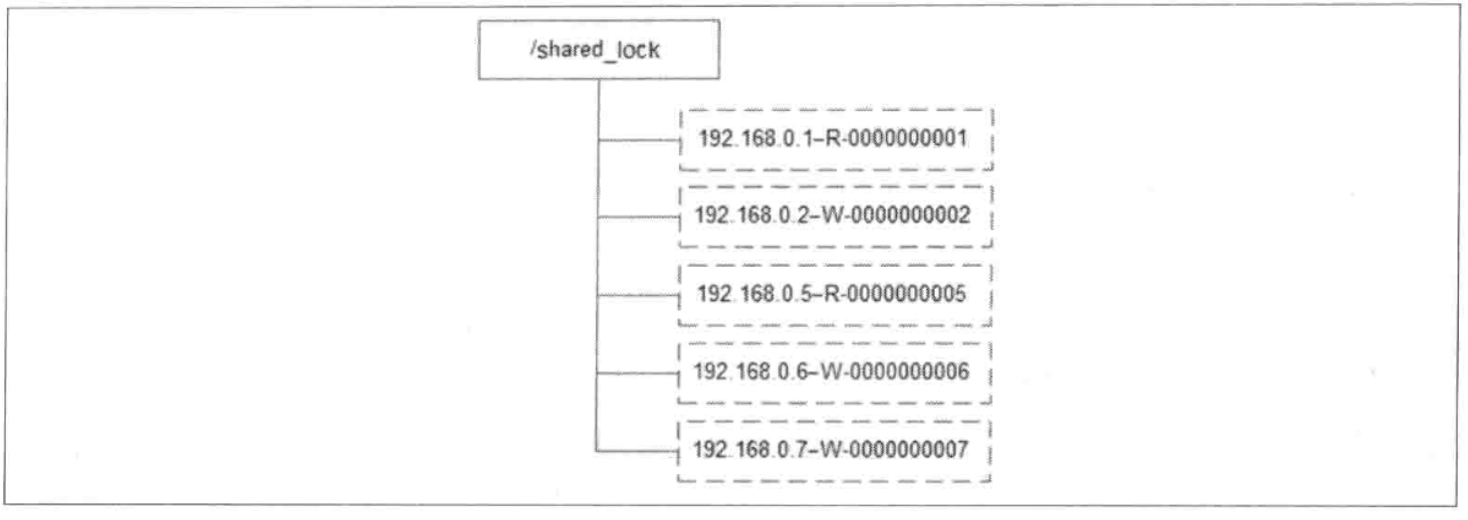
使用Zookeeper上的数据节点表示一个锁,类似于【/shared-lock/[Hostname]-请求类型-序号】的临时顺序节点。
比如/shared_lock/192.168.0.1-R-0000000001节点代表了一个共享锁。
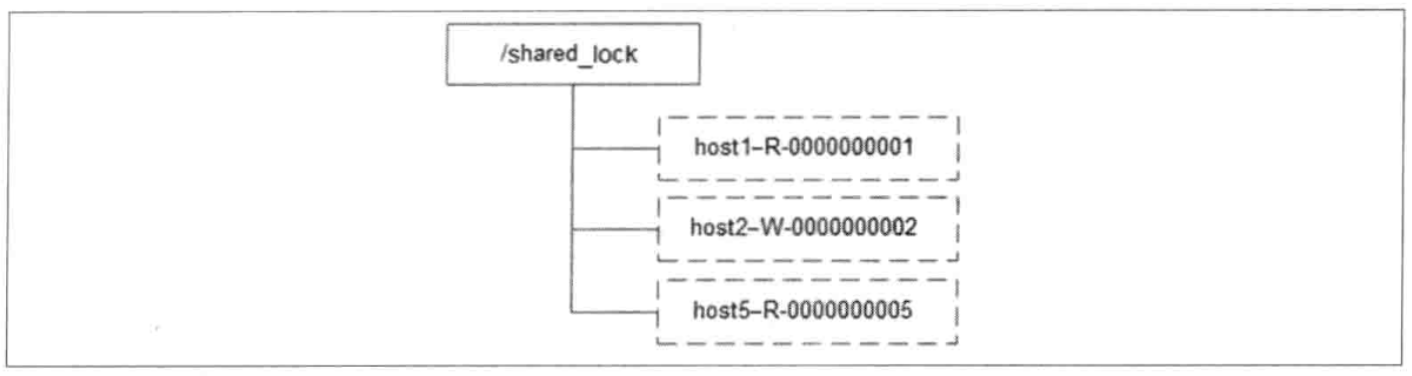
获取锁
获取共享锁时,所有客户端都会到/shared_lock节点下创建临时节点。
如果为读请求,创建形如/shared_lock/192.168.0.1-R-0000000001的节点。
如果为写请求,创建形如/shared_lock/192.168.0.1-W-0000000001的节点。
判断读写顺序
1.创建完节点后,获取/shared_lock节点下所有子节点,并对该节点注册子节点变更Watcher监听
2.确定自己的节点序号在所有子节点中的顺序
3.
对于读请求:
如果没有比自己序号小的子节点,或者,所有比自己序号小的子节点都是读请求,表明自己成功获取到了共享锁,开始执行读取操作。
如果比自己序号小的子节点中有写请求,那么就要进行等待
对于写请求:
如果自己不是序号最小的节点,那么就要进行等待
4.接收到Watcher通知后,重复步骤1
释放锁
释放锁的逻辑同排他锁一致。
共享锁的整个获取和释放过程,如下。
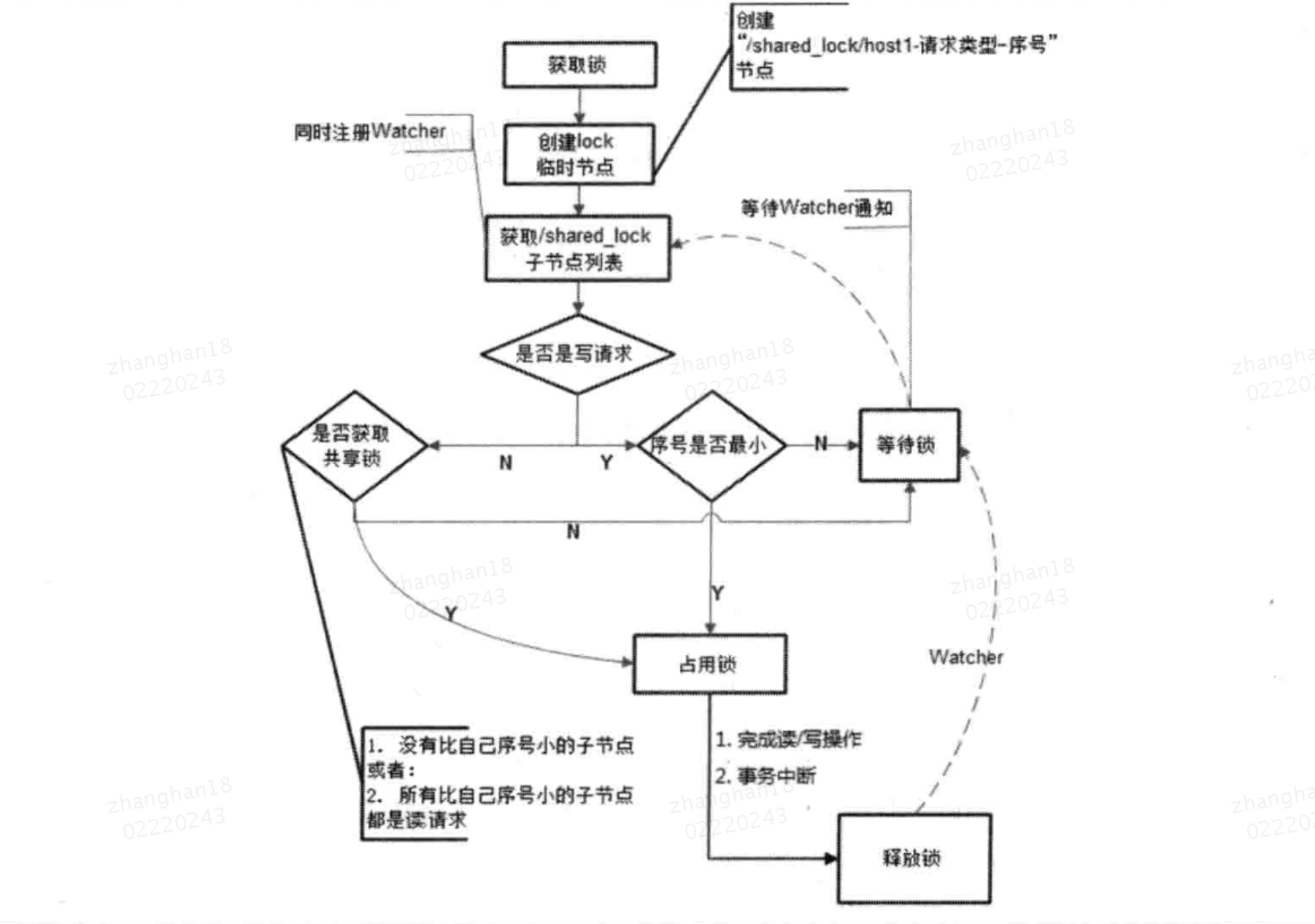
羊群效应
上面的共享锁实现存在的问题?
192.168.0.1执行读操作,读操作完成后将节点/192.168.0.1-R-0000000001删除。剩下4台机器都收到节点被删除的通知,重新获取新的子节点列表,并判断自己的读写顺序。
如果发现没有轮到自己进行读取或更新操作,继续等待。
“剩下所有机器都收到节点删除watcher通知”并且“剩下所有机器重新获取子节点列表”
客户端无端收到大量和自己无关的通知。在集群规模较大的情况下,会对Zookeeper服务器造成巨大的性能影响。
这就是所谓羊群效应。
改进后的分布式锁实现
每个客户端仅需要关注比自己需要小的相关节点的变更情况就可以了,而不需要关注全局子列表变更情况。
1.客户端调用创建形如"/shared-lock/[Hostname]-请求类型-序号"的临时顺序节点
2.客户端获取所有已经创建的子节点列表(注意:不注册子节点列表变更的watcher)
3.向“比自己序号小的节点”注册Watcher
对于读请求:向比自己序号小的最后一个写请求节点注册Watcher监听
对于写请求:向比自己序号小的最后一个节点注册Watcher监听
4.等待Watcher通知,继续进入步骤2
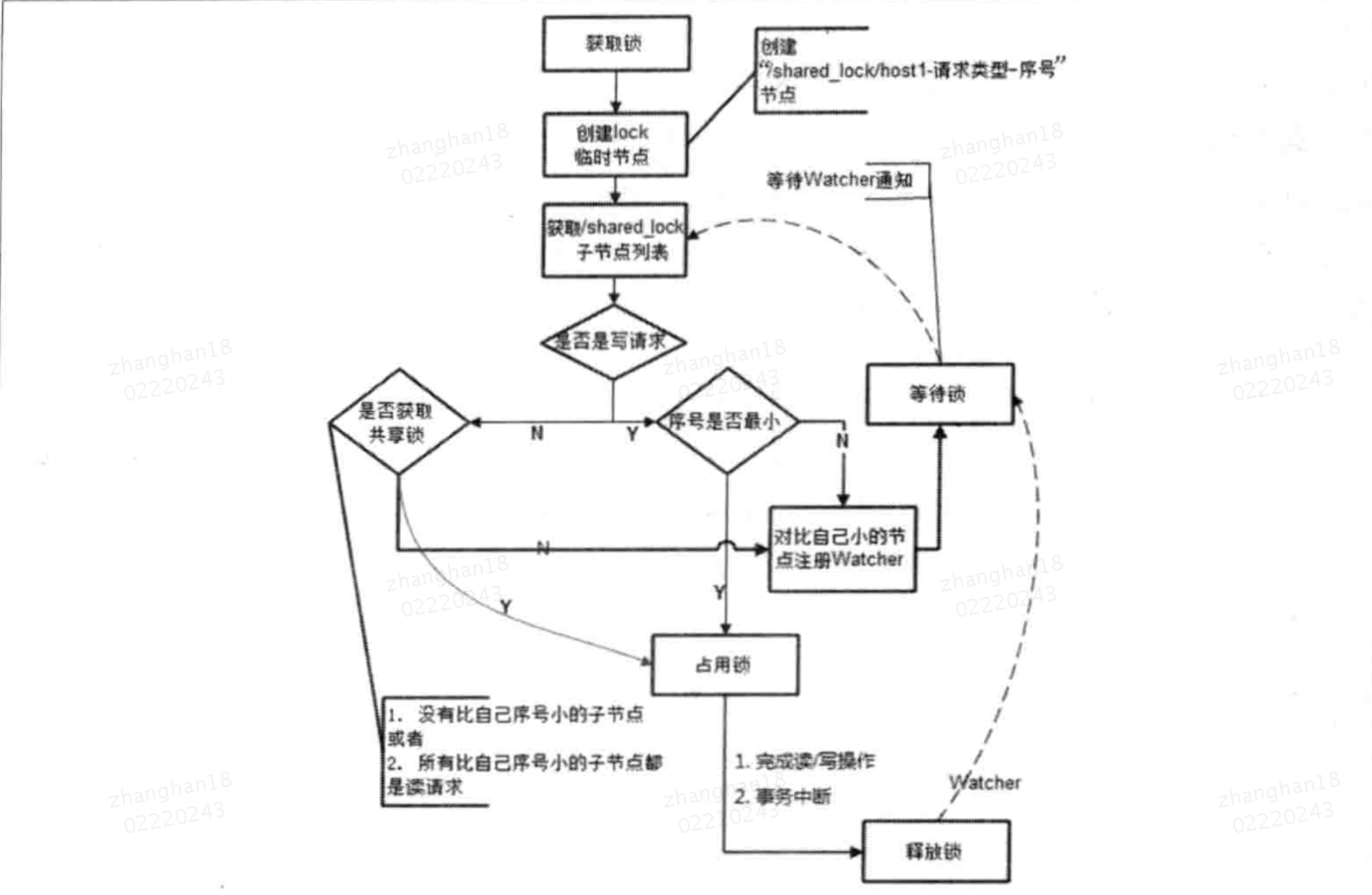
对于集群规模不大的情况,可以选用第一种实现方式
对于集群规模达到一定程度,希望精细化控制锁的,可以选用改进版的。
6)分布式队列
分布式队列可分为两大类:
1)先进先出队列(FIFO)
2)等到队列元素聚集之后统一安排执行的Barrier模型
先进先出队列(FIFO)
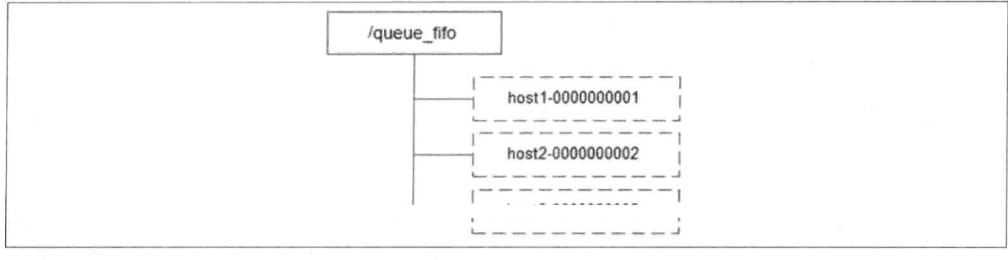
queue_fifo节点为一个队列。
入队
客户端会到/queue_fifo节点下创建一个临时顺序节点,如/queue_fifo/192.168.0.1-000000001
出队
1.获取/queue_fifo节点下的所有子节点,即获取队列中所有的元素
2.确定自己的节点序号在所有子节点中的顺序
3.如果自己不是序号最小的子节点,那么就需要进入等待,同时向比自己序号小的最后一个节点注册Watcher监听
如果自己是序号最小的子节点,主动删除自己创建的临时节点,出队
4.接收到Watcher通知后,重复步骤1
先进先出队列流程图如下。

Barrier:分布式屏障
Barrier:规定一个队列的所有元素都聚齐后才同意安排。
应用场景:分布式并行计算
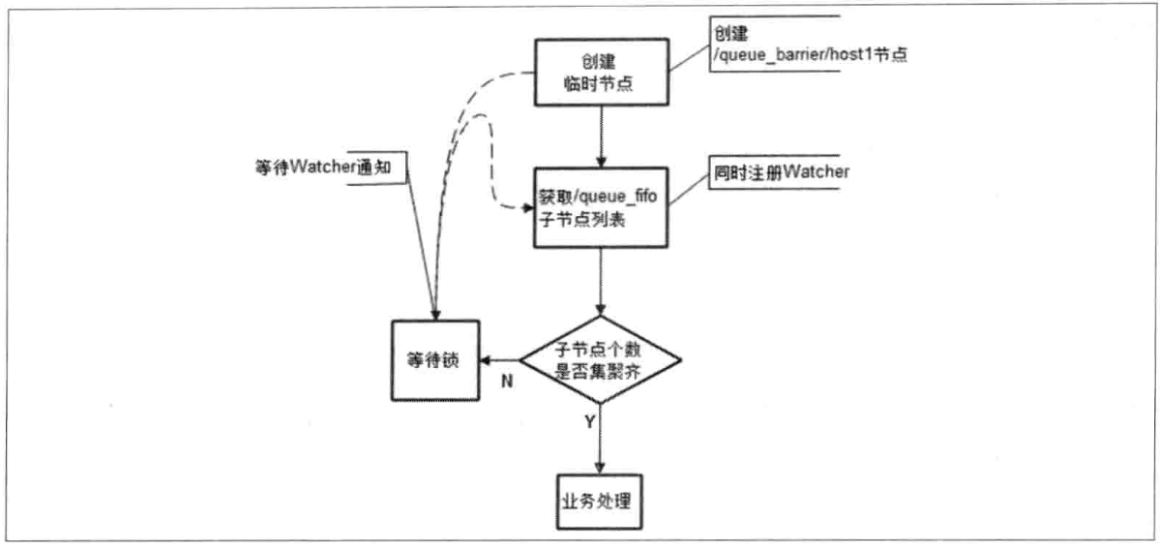
queue_barrier节点为一个barrier,节点数据内容n,例如n=10表示只有当queue_barrier节点下的子节点个数达到10后,才会打开Barrier
到达屏障
客户端到/queue_barrier节点下创建一个临时节点,如/queue_barrier/192.168.0.1
是否需要执行
1.获取/queue_barrier节点的数据内容:10
2.获取/queue_barrier节点的所有子节点,同时注册对子节点列表变更的Watcher通知
3.统计子节点个数,如果子节点个数不足10个,需要进入等待;
如果子节点个数达到了10个,执行任务
4.接收到Watcher通知后,重复步骤2
Barrier的流程图如下。