一年半之前刚来到这个团队,便遭遇了一次挑战:
当时有个CRM系统,老是出问题,之前大的优化进行了4次小的优化进行了10多次,要么BUG重复出现,要么性能十分拉胯,总之体验是否糟糕!技术团队因此受到了诸多质疑,也成了我这边过来外部的第一枪。
当时排查下来,问题反复的核心原因是:
该系统依赖一个核心IM系统;这套IM系统已经有几年时间,之前的同学一来是没有魄力去做重构,二来是没有能力做重构,所以每次只能小打小闹,但里面的服务旁枝错节,总有依赖服务没被修复好。
考虑这种情况,我这边派出了两支团队,一只由小孙带团,给一个月时间做完整重构势必解决问题;一只之前的小分队,应付一下业务团队即可,而真实业务端的压力以及上层的质疑,由我一肩挑起,我这里毕竟是新来的,由一个耍赖皮的窗口期,以下是重新设计的核心模块。
— 1 —业务梳理
在线上,医患沟通、患者与健康管理师、医生和医生助理沟通,这些远程交流的场景离不开IM,它是这些沟通一个基础建设。
健康管理师和医生助理在协助医生帮助患者的场景下,他们使用的工作台是让线上的随诊、问诊快速方便的开展相关重要功能。
如果要做这么一个满足现在业务场景的工作台需要怎么来实现及优化,以下讲解如何搭建和优化工作台IM核心功能。
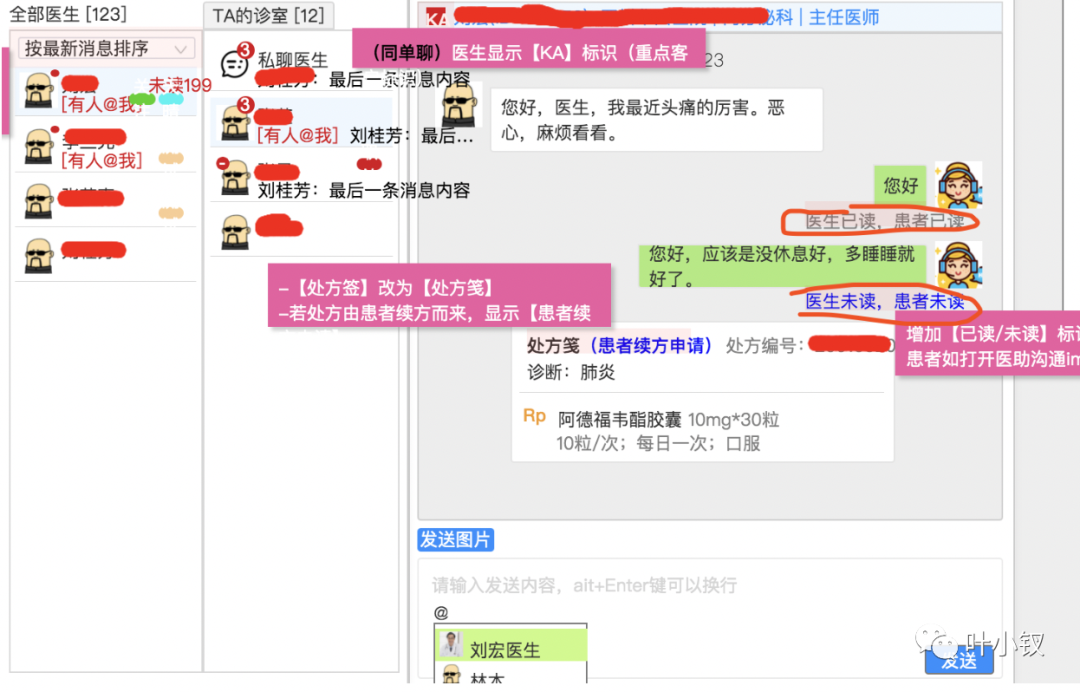
— 2 —IM核心架构
第一个问题业务底层的IM架构是如何的?
下图中分了三种类型的服务一种是comet,一种是gateway以及内部使用grape-http。
comet:推送核心是长链接接实时推送,comet主要是作为tcp/websocket的一个接入层足够简单负责客户端长链接的维护链接保活的心跳机制和消息下行推送,同时还具备一些比如重链的一些特殊指令下发;
gateway:为了减少服务的复杂度将消息上行的功能抽到http接口来承接,包括登陆功能、comet集群负载均衡,发送图片、音视频,基础信息查询等。
grape-http:作为内部其他服务调用comet推送的内部服务。
需要特别注意:
1)网络传输大小端;
在网络传输中需要注意大小端问题,什么是大小端?
对于一个由2个字节组成的16位整数,在内存中存储这两个字节有两种方法:
一种是将低序字节存储在起始地址,这称为小端(little-endian)字节序;
另一种方法是将高序字节存储在起始地址,这称为大端(big-endian)字节序。
总而言之,大端是高字节存放到内存的低地址;小端是高字节存放到内存的高地址,在网络通信中,不同的大小端CPU需要做数据处理再进行传输。
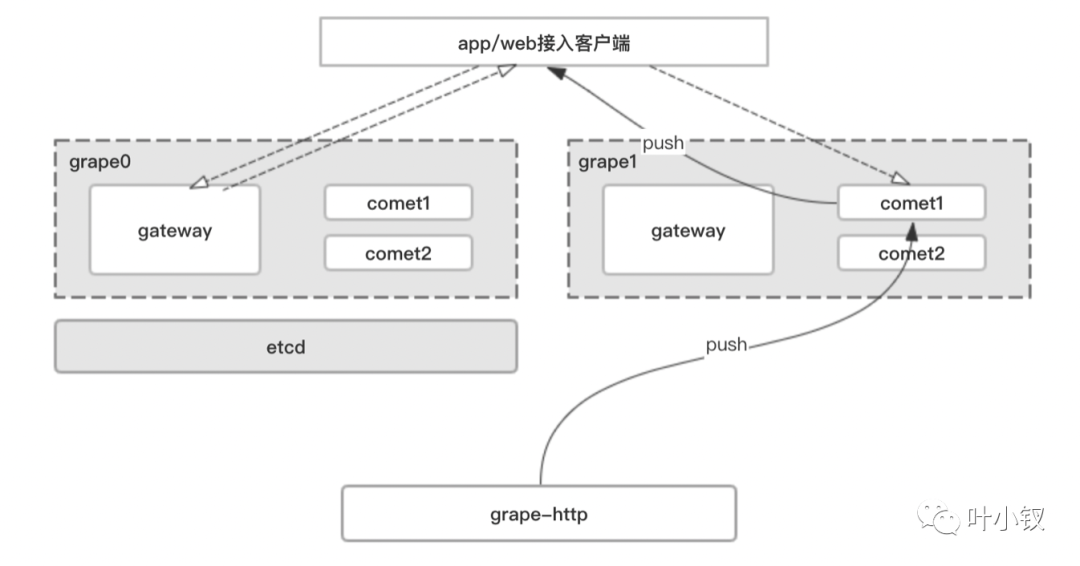
2)TCP粘包;
在socket网络编程中,都是端到端通信,由客户端端口、服务端端口、客户端IP、服务端IP和传输协议组成的五元组可以明确的标识一条连接。
在TCP的socket编程中,发送端和接收端都有成对的socket,发送端为了将多个发往接收端的包,更加高效的的发给接收端,于是采用了优化算法(Nagle算法),将多次间隔较小、数据量较小的数据,合并成一个数据量大的数据块,然后进行封包。
那么这样一来,接收端就必须使用高效科学的拆包机制来分辨这些数据。
解决方式:
第一个种特定分割符格式化数据,每条数据有固定的格式(开始符,结束符)。这种方式简单,但是选择符号时一定要确保每条数据的内部不包含这些分隔符;
第二种自定义协议发送定长数据,发送每条数据时,将数据长度一并发送,例如规定数据的前4位的数据的长度,应用层在处理时可以根据长度来判断每个分组的开始和结束位置,如下图自定义协议格式:
— 3 —核心流程描述
上面说了整体的架构以及网络编程中需要注意的大小端和TCP粘包问题,接下来描述下大致的流程
1)客户端首先登陆,此处是采用http的方式进行登陆和鉴权
2)鉴权成功后,会返回一个comet的列表ip加端口的列表,客户端可以选择1个节点进行接入,通常负载最少的排在最前面,进行tcp/websocet的Auth认证通过之后链接上一个comet的节点。
3)此时已经建立了长链接,客户端可以通过http接口发送文本消息、图片、视频、语音消息,其中图片、语音、视频都是传到cdn上,然后将链接地址放在消息体中发送。
4)当comet某个节点挂掉了,客户端会尝试重新获取comet节点列表进行链接,如果多次都没有可用节点或者链接不成功,会告知用户服务链接失败。
5)如果comet的节点需要进行灰度升级,服务端会先加入新节点,然后灰度下线某个节点,下线的n节点会分批向该节点链接的client,发送重链的指令让客户端无损的方式断开重新链接其他节点,当client都转移到其他节点上之后,节点自动退出。
TCP链接是有链接的和http不一样,为了comet高可用做多个comet的集群不像http的负载均衡那么简单可以在前面挂一个nginx,每个client链接上一个comet的节点上,要推送到指定的client消息,需要判断这个client是链接到哪一个节点上的,comet的集群为了让所有节点更均衡采用了一致性hash算法的方式来进行comet负载均衡
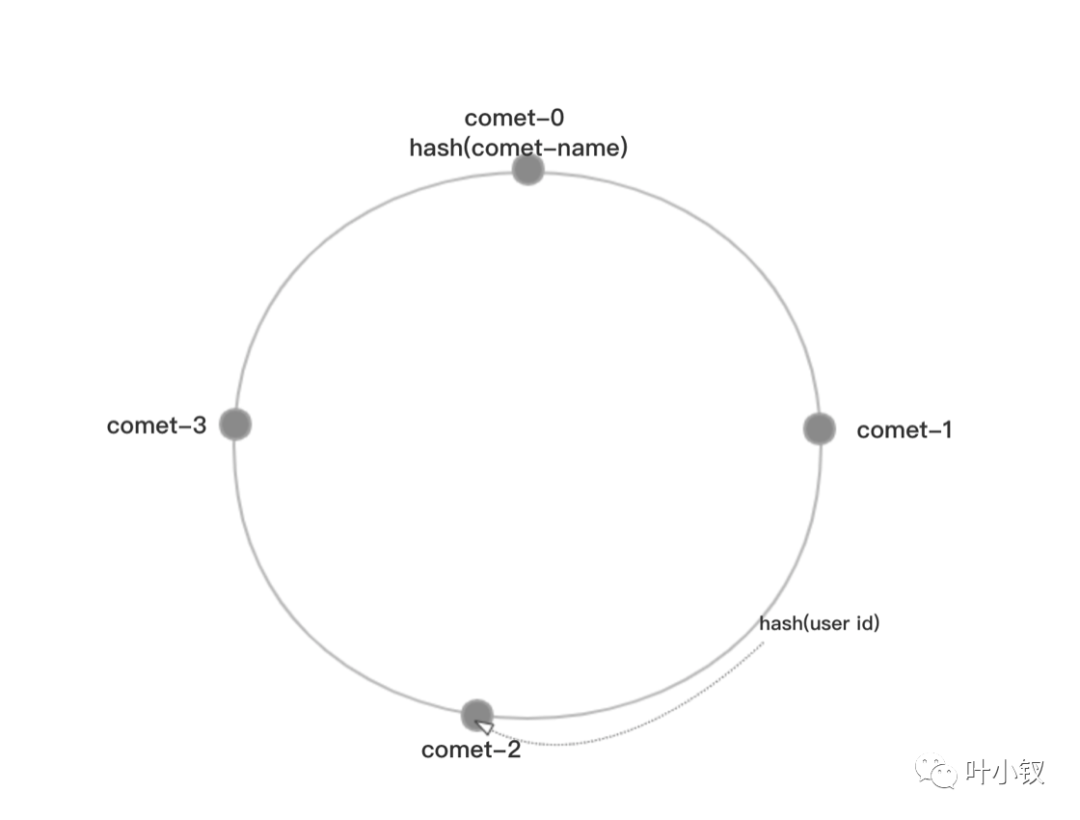
这样重新加入或者减少comet节点,需要client发起重链的就会变少。
— 4—业务心跳链接保火
先看下comet如何维持链接的存活,TCP协议自身已经有KeepAlive机制,难道不能保持链接存活么?
为什么需要应用层做心跳,这是TCP KeepAlive的机制决定的,KeepAlive存在一个探针以确定链接的可靠性,一般时间为7200s,失败后重试10次,每次超时时间75s,默认值无法满足我们的需求,即使修改设置后还是不能满足,TCP KeepAlive是用于检测链接的死活,而心跳机制则有一些业务的额外功能,检测通讯双方的可用的存活状态,比如TCP是链接成功的。
但是服务器已经CPU使用率100%无法处理业务了,此时链接成功,但是业务上是失败的,基本上心跳回复不了。
在我们comet中有TCP/websocket的心跳机制,简单的做法是客户端定时心跳,比如间隔30s发起一次Ping消息,服务端回复Pong消息,如果15s内没有收到心跳Pong消息,则此链接失效,需要断开之后重新进行链接。
为了节省流量,心跳包要足够小,并且频率也不能太高,尽量拉长心跳间隔,5分钟,10分钟,或者更加优化的方式是5分钟内没有和服务器交互消息空闲才会触发心跳逻辑,减少请求次数,移动端需要考虑心跳定时的范围耗电等资源消耗。
— 5 —消息时序&一致性
严格需要时序的场景:消息发送走的http上行,如何保证群消息的有序性和一致性,根据群id进行sharding到单点串行化写db的inc_id生成的递增id,返回后进入推送的有序队列中进行消息下行阶段
非严格时序场景:分布式集群下,采用分布式id生成器进行递增生成,每个群需要id串行。
分布式场景下,消息的有序性很难,原因很多,时钟不一致,多发送方,多接收方,消息量大网络传输问题等。也可以要有序可以客户端,或者服务端来进行有序标志
绝对有序场景需要严格控制id有序生成,单对单聊天,只需保证发出的时序与接收的时序一致,可以利用客户端有序;群聊,只需保证所有接收方消息时序一致,需要利用服务端seq,方法有两种,一种单点绝对时序,另一种id串行化。
— 6—消息丢失问题
作为严格的医疗问诊场景,用户和医生的聊天记录是不能重复和丢失,使用业务层进行消息的ACK回执保证线上的消息不丢,发送消息出去。
用户在线:推送消息,并且业务上进行ACK回复确认发送成功;
用户离线:服务端会记录未推送的未读列表,当用户再次进入聊天窗口,拉取历史消息进行ACK确认发送成功。
在客户端要进行消息的去重操作,如果ACK回复没有返回或者操作失败的情况下,服务端会再次推送消息。
在线情况下:每发送一条消息,群里有多少用户,就会有多少个消息ACK确认的应答,如何群人数足够多会对服务器造成瞬时的ACK请求,为了减少这种减少瞬时大量请求,通过两个业务逻辑进行优化,每收到X条ACK一次批量ACK回执,则请求降低到1/X了;
但是如果一直达不到X条呢,需要每隔一段时间进行一次批量ACK,能补偿一直达不到X条的情况。
离线情况下:在用户长时间离线,再次登陆时,需要拉取未读消息,如果是APP会保持到本地,需要保证APP和服务端的消息列表数据同步。
1)登陆成功需要拉取好友列表(id+姓名+未读数量+最后一条信息+最后一条信息时间)
2)群组列表(id+群组名称+未读数量+最后一条信息+最后一条信息时间)
3)群详情(按需加载)
设备长期未登陆在未读消息量大的情况下,防止client端拉取大量未读消息卡顿,需要延迟分页拉取,当进入群列表时分页拉取消息,下一页的拉取,同时作为上一页的ACK,这样可以减少与服务器的请求次数。
更换新设备登陆需要拉取全量数据,可以将数据打包下发此场景也需要区分整个数据拉取的分批次,优先是好友记录,群列表,然后拉取部分消息,最后的消息记录需要按需拉取尽可能减少初始化拉取的数据量以及访问服务器的次数。
好友在线状态
好友在线状态,如果对展示的实时性要求高,可以采用推送方式同步,但是如果好友太多,这推送的资源成本太高,好友数几十万进行推送同步这种不太现实。
可以做按需展示,当到好友聊天界面或者进去群聊,采用拉取,延迟拉取的方式同步,界面可视的区域拉取在线状态。
— 6—消息已读功能
在进行聊天中,发出去的消息是否对方已经收到。
谁读了,谁假装没在线,要做这个功能实现前面已经说过,保证消息不丢失有业务层ACK反馈,同样消息已读也需要有回执机制。
和ACK不一样的是已读标记只需要记录last_msg_id标记,在last_msg_id之前的都是已读,有新的msg_id> last_msg_id存在未读消息,当client打开消息对话框,last_msg_id标记为最新的则清空未读数量,并且需要广播未读人数,修改未读数逻辑。
client发送已读的last_msg_id到服务器端,则判断用户进入群的时间和消息时间进行对比,如果进入群时间早则需要修改last_msg_id和之前群成员表中的last_msg_id中消息的unread数量。
群消息:g_msgs(msg_id, gid, suid, time, msg, unread)
群成员表:g_users(gid, uid, last_msg_id)
已读成员列表:g_readers(msg_id,gid,uid,time)
来看群消息流程:
1、client A 发出群消息
2、服务器将消息写入到db,然后查询群成员。
3、分别对群成员进行在线判断并实时推送。
4、根据client 回执的last_msg_id来记录消息的已读人数。
同样已读回执也会出现短时间大量回执请求的情况,也需要减少回执的请求量。
做好一个IM系统支持业务真的很不容易,这些优化只是九牛一毛,欢迎大家一起讨论学习,让自己的系统更加稳定更好的服务业务。
— 6—结语
经过一轮操作,系统首轮重构结束,小孙在团队中的势能得到了很好的提升,我来团队的对外一枪也打响了,为后续机制推行、技术升级都有莫大好处。
