卷积神经网络(Convolution Neural Network, CNN)在数字图像处理领域取得了巨大的成功,从而掀起了深度学习在自然语言处理领域(Natural Language Processing, NLP)的狂潮。2015年以来,有关深度学习在NLP领域的论文层出不穷。尽管其中必定有很多附庸风雅的水文,但是也存在很多经典的应用型文章。笔者在2016年也发表过一篇关于CNN在文本分类方面的论文,今天写这篇博客的目的,是希望能对CNN的结构做一个比较清晰的阐述,同时就目前的研究现状做一个简单的总结,并对未来的发展方向做一个小小的期望。由于笔者在深度学习方面的资历尚浅,因此如文中出现错误,请不吝赐教。
一. CNN的结构阐述(以LeNet-5为例)
我写这一节的目的,并不是从头到尾的对CNN做一个详细的描述,如果你对CNN的结构不清楚,我建议还是先去看LeCun大神的论文Gradient-based learning applied to document recognition,而且,网上也有很多经典的博客,对CNN的结构和原理都做了比较深入的阐述,这里推荐zouxy大神的博客。这里对结构进行重新阐述,主要是对一些入门的同学可能会碰到的问题进行一些突出和讨论,并且主要围绕以下几个问题展开(一看就懂得大神请绕道):
- CNN中的卷积的数学实现是什么?这里的卷积和数字信号处理的卷积是相同的吗?
- CNN中哪些层需要进行激活?
- 在LeNet-5中,C1和C3最大的区别是什么?
- CNN是如何进行训练的?
我们先来看LeNet-5的结构图(LeNet共有3个C层2个S层,故被称为LeNet-5,如果算上F6和输出层,则可以被称为LeNet-7):
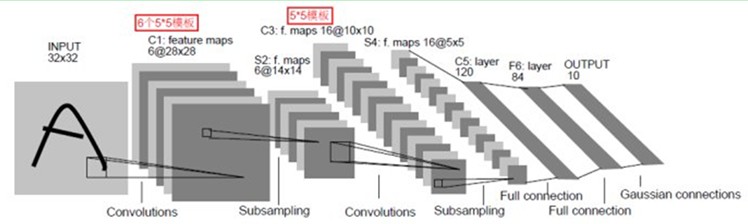
首先,我们先对CNN中的一些概念做一遍梳理。尤其需要注意的是Filter Window(卷积核的size,数字图像处理中一般为正方形),Feature Map(特征图,一般来说,对于每一个Filter Window有几个Feature Map,以捕捉不同的特征)。从图中我们可以看出,C1层的Feature Map是6,C3层的Feature Map是16,C5层的Feature Map是120,最后的F6相当于普通神经网络的隐层,通过全连接和C5相连,最后通过Gaussian Connection将其转换为一个10分类的问题。
针对第1个问题,卷积究竟是什么。卷积这个玩意儿在数字信号处理中经常被提及,它的数学表达式如下:
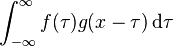
看到公式一般都比较头疼,所以在这里贴出来一个关于数字信号处理中的卷积的形象比喻:
比如说你的老板命令你干活,你却到楼下打台球去了,后来被老板发现,他非常气愤,扇了你一巴掌(注意,这就是输入信号,脉冲),于是你的脸上会渐渐地(贱贱地)鼓起来一个包,你的脸就是一个系统,而鼓起来的包就是你的脸对巴掌的响应,好,这样就和信号系统建立起来意义对应的联系。下面还需要一些假设来保证论证的严谨:假定你的脸是线性时不变系统,也就是说,无论什么时候老板打你一巴掌,打在你脸的同一位置(这似乎要求你的脸足够光滑,如果你说你长了很多青春痘,甚至整个脸皮处处连续处处不可导,那难度太大了,我就无话可说了哈哈),你的脸上总是会在相同的时间间隔内鼓起来一个相同高度的包来,并且假定以鼓起来的包的大小作为系统输出。好了,那么,下面可以进入核心内容——卷积了!
如果你每天都到地下去打台球,那么老板每天都要扇你一巴掌,不过当老板打你一巴掌后,你5分钟就消肿了,所以时间长了,你甚至就适应这种生活了……如果有一天,老板忍无可忍,以0.5秒的间隔开始不间断的扇你的过程,这样问题就来了,第一次扇你鼓起来的包还没消肿,第二个巴掌就来了,你脸上的包就可能鼓起来两倍高,老板不断扇你,脉冲不断作用在你脸上,效果不断叠加了,这样这些效果就可以求和了,结果就是你脸上的包的高度随时间变化的一个函数了(注意理解);如果老板再狠一点,频率越来越高,以至于你都辨别不清时间间隔了,那么,求和就变成积分了。可以这样理解,在这个过程中的某一固定的时刻,你的脸上的包的鼓起程度和什么有关呢?和之前每次打你都有关!但是各次的贡献是不一样的,越早打的巴掌,贡献越小,所以这就是说,某一时刻的输出是之前很多次输入乘以各自的衰减系数之后的叠加而形成某一点的输出,然后再把不同时刻的输出点放在一起,形成一个函数,这就是卷积,卷积之后的函数就是你脸上的包的大小随时间变化的函数。本来你的包几分钟就可以消肿,可是如果连续打,几个小时也消不了肿了,这难道不是一种平滑过程么?反映到剑桥大学的公式上,f(a)就是第a个巴掌,g(x-a)就是第a个巴掌在x时刻的作用程度,乘起来再叠加就ok了,大家说是不是这个道理呢?我想这个例子已经非常形象了,你对卷积有了更加具体深刻的了解了吗?(转自GSDzone论坛)
其实,在数字信号处理中,卷积就是信号B与信号A错开时间的内积,错开的时间长度就是卷积结果的自变量。但是,CNN中,卷积操作的作用是突出特征,将更明显的特征提取出来。那么这两个卷积是一样的吗?其实,在CNN中(尤其在自然语言处理的过程中),卷积的操作也是用一个公式来表示的:
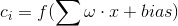
至于这个公式中为什么会有连加,我在接下来的问题中进行阐述。f是一个激活函数,从这里我们可以看出,CNN中的卷积层最后也是需要激活的。而w和x之间的点乘符号,其实就是两个矩阵之间普通的点乘操作。所以,在LeNet5中,卷积其实就是要卷积的区域和卷积核的点乘和,加上偏置之后的激活输出。但是这里和数字信号处理中的卷积有什么联系,以及为什么取名为卷积,在这里暂不讨论,不过知道的朋友可以留言,不胜感激。
针对第2个问题,CNN中哪些层是需要激活函数的?刚才我已经说了,在C层确实是需要激活函数的,那么在其他层需要吗?且看下面的图:
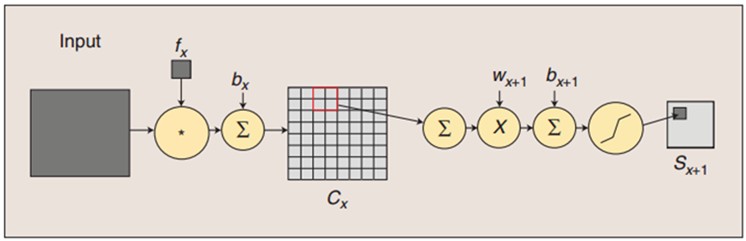
在这个图里主要展现的是卷积操作和池化操作,但是都没有体现f函数,即激活函数。其实,在卷积层和池化层,在最后都是需要加上偏置激活输出的。但是,有些神经网络在实现的时候,可能并不会去实现激活。比如,卷积操作直接将w和x的点积和作为输出,而池化操作直接使用1-max将top1的值输出,而不进行激活操作。要知道,sigmoid,tanh以及ReLU等激活函数,可以非常好的捕捉到非线性的特征。因此,在LeNet5中,卷积层和池化层都会进行偏置激活。全连接层F6和普通神经网络的隐层是一样的,也是最后要激活输出的,因此也需要激活函数。其实,CNN可以理解为,除了卷积操作和池化操作,其余的和NN没有区别,最后只是跟了一个多分类器。因此,CNN的训练也是基于BP算法,利用随机梯度下降(SGD)进行参数训练。
针对第3个问题,C1和C3有什么区别?其实没有区别,但是有一点需要注意(这一点刚入门的同学可能会忽略,容易想当然)。其实卷积操作都可以用上面的那个公式进行表示,但是公式里的连加符号表示什么呢?我们先来看C1,C1的卷积想必非常好理解,对于每个卷积核,会生成一个Feature Map,这个Feature Map在生成的过程中,只用到了输入图像这一个Feature Map,而不涉及连加操作。但是,从S2到C3,由于S2的Feature Map的数量是6,因此这时我们不再对S2的每一个Feature Map都在C3生成Feature Map。C3中的每个Feature Map是连接到S2中的所有6个或者几个Feature Map的,表示本层的Feature Map是上一层提取到的Feature Map的不同组合。这好比人的视觉系统,底层的结构构成上层更抽象的结构,例如边缘构成形状或者目标的部分。同样的原理,如果应用在NLP上,那么在对一篇文档进行分类的时候,这个操作可以类比为从句子级别的篇章理解上升到了从段落上的级别理解。理解了这一点,我们可以计算出每层所需要的参数,如下所示:
C1:6*(5*5+1) = 156, 对于每一个Filter来说,卷积之后,要加一个bias,因此每一个Filter会多一个bias;Map大小(32-5+1)*(32-5+1)=28*28
S2:6*(1+1) = 12, 在LeNet中,会通过avg pooling取出平均值,然后针对该值,进行加权偏置,激活输出,因此1个Feature Map的pooling只需要2个参数;Map Size 14*14;
C3:C3层共有16个Feature Map,Filter Window的大小依旧是5*5,并且每一个Feature Map和S2层的Map形成了全连接或者部分连接,因此需要根据情况进行计算。例如,假若在C3层,前6个Feature Map和S2层的4个Map相连,中间6个和S2层的4个Feature Map相连,最后4个和S2层的3个Feature Map相连,那么总共需要的参数个数为:6*(4*5*5+1)+6*(4*5*5+1)+4*(3*5*5+1) = 1440个参数。注意,这里在组合的时候,是对S2每一个相连的Map都训练了一个单独的w,最后在所有的wx的和上添加偏置。Map Size为(14-5+1)*(14-5+1) = 10*10;如下所示:
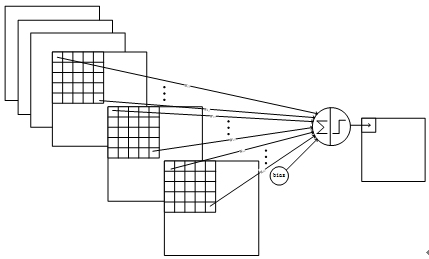
S4:pooling size的大小依旧是2*2,则16个Feature Map的参数个数,同S2的计算方式,为16*(1+1)=32个;Map Size为5*5;
C5:C5层有120个Feature Map,Filter Window的大小依旧是5*5,并且要注意的是,C5和S4之间是全连接的,这是第一个全连接层,也就是C5中的每一个1*1大小的Feature Map,和S4中16个Feature Map都有连接,那么参数个数也可以很容易的计算出来:120*(16*5*5+1)= 48120;此时,Feature Map的大小为1*1,在这里,这120个1*1大小的特征图,连接成一个向量,这便组成了C5;
F6:F6层就是普通神经网络里面的隐层,在这里是为了将120维的C5降维成84维的F6。F6中的每一个神经元和C5也形成了全连接,这是第二个全连接层,因此需要训练的参数个数为:84*(120+1)=10164个;
Output层:输出层由欧式径向基函数(Euclidean Radial Basis Function)单元组成,每类一个单元,每个有84个输入。换句话说,每个输出RBF单元计算输入向量和参数向量之间的欧式距离。输入离参数向量越远,RBF输出的越大。一个RBF输出可以被理解为衡量输入模式和与RBF相关联类的一个模型的匹配程度的惩罚项。用概率术语来说,RBF输出可以被理解为F6层配置空间的高斯分布的负log-likelihood。
针对第4个问题,CNN如何进行训练?卷积神经网络的训练其实和NN的训练过程大体类似,都是采用基于BP算法的训练方式,进行随机梯度下降。首先,通过前向传播计算各层节点的激活值,然后,通过后向传播计算各层之间的误差,如果遇到了pooling,若采用的是avg pooling,那么相应的也就将误差进行均分,反向传播;如果是max pooling,那么可以只将相连的最大节点的误差进行传播,其他节点误差为0;至于卷积操作,其实你仔细想一下的话,和普通的神经网络没啥子大的区别,无非就是权值共享了,因为如果是普通的神经网络,那么w一般针对的是全连接;而CNN是应用了权值共享减少参数个数,并且还进行了Feature Map之间的组合。
二. CNN在自然语言处理中的应用
卷积神经网络在自然语言处理中又是如何应用的呢?接下来,我也想围绕几个问题作几个比较基本的阐述:
- 在NLP中CNN的输入可以是什么?
- 如果输入是词向量,每一行代表一个词,那么如何解决不同的文本长度不统一的问题?
- NLP中CNN的常用超参数设置都有哪些?
- 接下来CNN在NLP的研究还可以从哪个方向进行?
首先,针对第1个问题,NLP中CNN的输入可以是什么?其实,任何矩阵都可以作为CNN的输入,关键是采用什么样的方法。如果你使用one-hot represention,那其实就是0-gram,这样输入的矩阵的大小肯定也是固定的(整个词表的长度);如果采用word2vec,那么每一行代表一个词语,文档中有多少个词语,就有多少行。这里,我们再来回顾一下词向量:其实它是神经语言概率模型[1]的一个副产品,不过可以反映出词语的语义信息。word embedding技术,主要分为两种思想,Hierarchical Softmax和Negative Sampling两种,其中每种思想下又分为两种方法,CBow模型和Skip-Gram模型,关于word embedding的数学原理,这里不再赘述,可以参考word2vec中的数学原理一文,这篇博文讲的很清楚。这里需要注意的是,word2vec一般通过pre-training的方式获得,比如google的word2vec就是从大量的文本中预训练得到的。你在CNN中使用的使用,可以按照static和non-static两种方式,如果是non-static的话,则表明你在训练CNN的时候,需要对使用的word2vec做一个轻微的tuning。word2vec可以算是CNN进行NLP应用时候的标配。
针对第2个问题,如何解决不同的文本长度不统一的问题?这是一个非常显然的问题,在LeNet-5中,每个输入都是32*32的图像文件,这样我们才能设置固定大小和数量的filters,如果图像分辨率发生了变化,那么就会造成多余的conv操作的结果丢失,从而对模型的结果产生影响,或者会使得网络内部状态发生混乱。在图像处理中,可以通过固定输入的图像的分辨率来解决,但是在自然语言处理中,由于输入的是文档或者sentence,而输入的长度是不固定的,那么如何解决这个问题呢?其实,在NLP中,研究人员一般都采用的是“单层CNN结构”,这里的单层并不是只有一层,而是只有一对卷积层和池化层。目前有两篇论文做的不错,一个是NYU的Yoon,另一个是Zhang Ye的分析报告[3],参看下面的图(图来自Yoon的论文[2],该论文的代码地址:yoon kim的github)
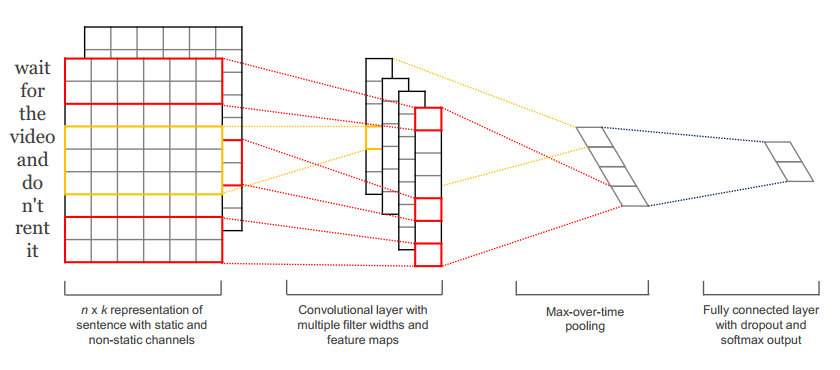
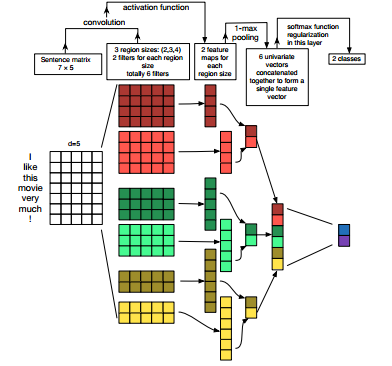
可以看到,每次在卷积的时候,都是整行整行的进行的。这好比是n-gram模型,如果每两行conv一次,那么就是2-gram,要知道,google最多也不过使用了5-gram模型,因为这种模型计算量非常大,但是如果在CNN中进行类似的操作,计算量反而减小了。在第二层的卷积层中,我们可以看到,每次得到的Feature Map的行数,是和输入的sentence的长度相关的。但是,在池化层,采用了1-max pooling的技术,从而将每个Feature Map的维度全部下降为1,因此,pooling结束之后,得到的向量的维度,就是卷积层Feature Map的数量。这样也便解决了输入长度的问题。但是,接下来无法再进行conv操作了,而且,在这个应用里,也不会出现像LeNet-5那样的Feature Map的组合输出的现象,因为只有一层卷积层。那么这里问题就来了,这样单层的结构到底效果如何?能不能扩展成多层的结构呢?能不能使用Feature Map的组合策略呢?单从Yoon的paper来看,结果是不错的,可是这样的结构一定适合其他应用问题吗?如果我们在conv操作的时候,不整行整行的卷积,那么这样就无法用n-gram去解释了,但是这样的效果如何呢?其实也有人做过了,是Nal的Paper,参考文献[4]. 个人不推荐这种部分卷积的做法。
针对第3个问题,CNN在应用的时候,超参数如何设定?下面,我们从几个方面进行阐述。首先是Filter Window的大小,由于在卷积的时候是整行整行的卷积的,因此只需要确定每次卷积的行数即可,而这个行数,其实就是n-gram模型中的n。一般来讲,n一般按照2,3,4这样来取值,这也和n-gram模型中n的取值相照应;当然,在文献[3]还详细分析了Filter Window大小对实验结果的影响,并且一直取值到7;其次是Feature Map的数量,在文献[2]中,针对2,3,4每一个Filter Window,都设置了100个,这样经过池化层之后,得到的向量是300维的;还有一些其他的超参数,比如为了防止过拟合,在全连接层加入了Dropout,从而随机地舍弃一部分连接,Dropout的参数为0.5;在Softmax分类时使用L2正则项,正则项的系数是3;训练的时候,SGD的mini-batchsize是50等。另外还有一个问题是,当训练的word embedding不足时,也就是待分类的document中包含没有被pre-training出来的词时,需要在某个区间上,对该词的词向量进行随机的初始化。
针对第4个问题,CNN在NLP的研究方向还可以从哪些地方进行?首先,我们来简要列举2015年CNN在NLP的应用研究列表(2016的paper还没有出来,等出来之后会在这里补上):
- 扩展CNN的输入,扩充词向量的维度,加入新特征[5];将RNN的输出作为CNN的输入[6],
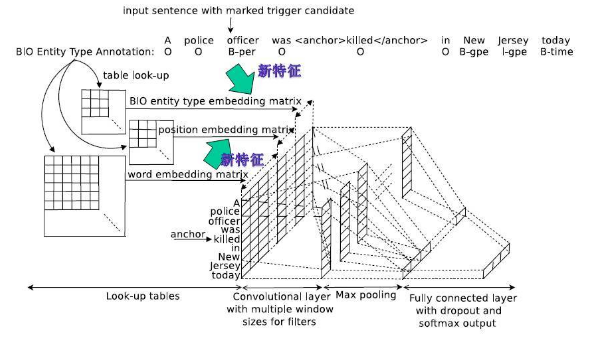
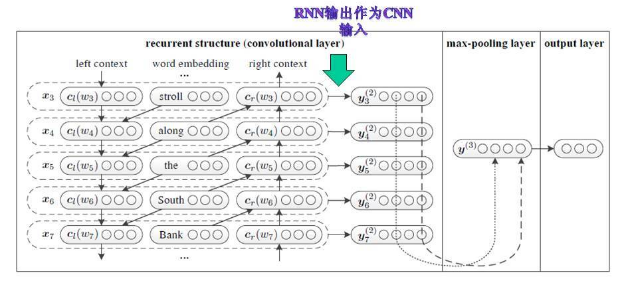
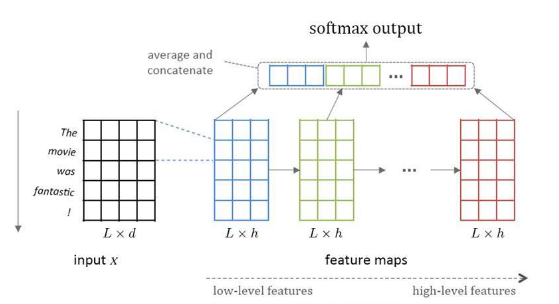
- 卷积层的改造。如:将word2vec横向组合,以发现句子层级的特征[7];卷积层的非线性化改造[8];

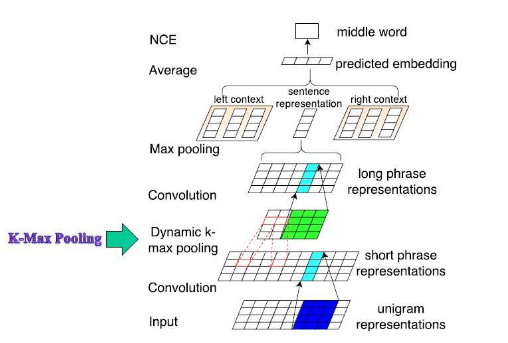
- Pooling层的改造。使用k-Max pooling以保留更多的特征[9];分段pooling[10];
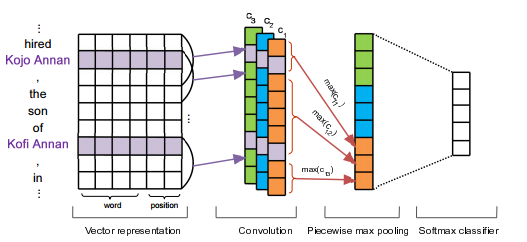
- CNN模型的组合。对同一输入做多重cnn分类,组合结果[11];一个句子一个CNN[12];
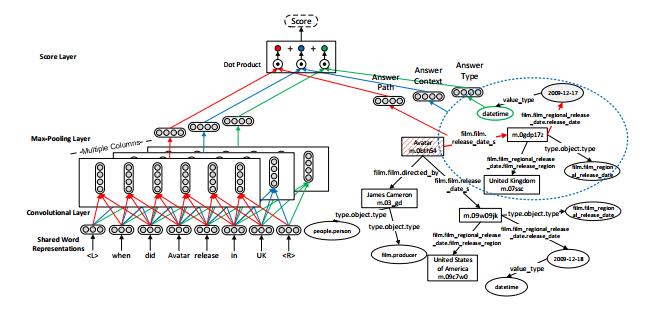
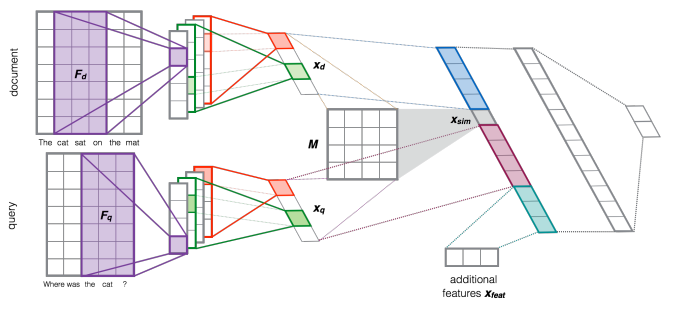
PS:这里有几个问题供读者思考,也是我正在思考的问题:目前我们所看到的CNN在NLP中的应用,大部分的网络结构都非常浅,主要是对于文本的不定长的特点,不好用多层CNN网络去训练,但是如果网络不够深,似乎又无法捕捉到更深层次的特征。因此,我们到底应不应该在NLP中应用多层CNN结构?如果应该,应采取怎样的策略?可不可以把S2到C3的Feature Map的组合卷积过程应用到NLP中?这都是我们都应该考虑的问题,如果您对这些问题有任何想法,欢迎留言交流。
参考文献:
[1] A neural probabilistic language model, Yoshua, Ducharme et al.
[2] Yoon Kim. Convolutional Neural Networks for Sentence Classification.
[3] Zhang Ye, et al. A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification.
[4] Kalchbrenner N, Grefenstette E, Blunsom P. A Convolutional Neural Network for Modelling Sentences[J]. Eprint Arxiv, 2014, 1.
[5] Event Detection and Domain Adaptation with Convolutional Neural Networks, TH Nguyen,R Grishman.
[6] Recurrent Convolutional Neural Network for Text Classification, Siwei Lai etc.
[7] Chen Y, Xu L, Liu K, et al. Event Extraction via Dynamic Multi-Pooling Convolutional Neural Networks[C]// The, Meeting of the Association for Computational Linguistics. 2015.
[8] Lei T, Barzilay R, Jaakkola T. Molding CNNs for text: non-linear, non-consecutive convolutions[J]. Computer Science, 2015, 58:págs. 1151-1186.
[9] Yin W, Schütze H. MultiGranCNN: An Architecture for General Matching of Text Chunks on Multiple Levels of Granularity[C]// Meeting of the Association for Computational Linguistics and the, International Joint Conference on Natural Language Processing. 2015.
[10] Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks Daojian Zeng, Kang Liu, Yubo Chen and Jun Zhao.
[11] Question Answering over Freebase with Multi-Column Convolutional Neural Networks, Li Dong etc.
[12] Severyn A, Moschitti A. Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks[C]// The, International ACM SIGIR Conference. 2015.
[13] Wang P, Xu J, Xu B, et al. Semantic Clustering and Convolutional Neural Network for Short Text Categorization[C]// Meeting of the Association for Computational Linguistics and the, International Joint Conference on Natural Language Processing. 2015.