目录
1. 样本迁移(Instance-based Transfer Learning) 6
2. 特征迁移(Feature-based Transfer Learning) 7
3. 模型迁移(Model-based Transfer Learning) 7
4. 关系迁移(Relational Transfer Learning) 8
机器学习的明天----迁移学习
上个月,柯洁大战AlphaGo落下帷幕,19岁的男孩少有地在比赛中落泪,赛后他为我们留下一句话,柯洁说"AlphaGo"看上去像神一样的存在,好像他是无懈可击的···
的确,DeepMind创造的AlphaGo让人为之赞叹,让柯洁为之疯狂。而背后,从机器学习的角度,充分证明了深度强化学习和大数据的重要意义。DeepMind就是将深度学习应用到强化学习的范例,DeepMind把端到端的深度学习应用在强化学习上,使强化学习能够应付大数据,因此可以在围棋上把人类完全击倒,它做到这样是通过完全的自学习、自优化,然后一直迭代。

顶级棋手柯洁0:3败给了AlphaGo,但是从科学的角度看AlphaGo到底有没有弱点呢?答案是肯定有的,AlphaGo不仅有弱点,而且还很严重,这个弱点就是它没有"迁移学习"的能力,而迁移学习是我们人类智慧的一种特质。接下来本文将重点介绍迁移学习的由来、思想、分类和主要应用。
-
什么是迁移学习
在机器学习的传统监督学习情况下,如果我们准备为某个任务/领域 A 来训练模型,获取任务/领域 A 里标记过的数据,会是前提。下图把这表现的很清楚:model A 的训练、测试数据的任务/领域是一致的。
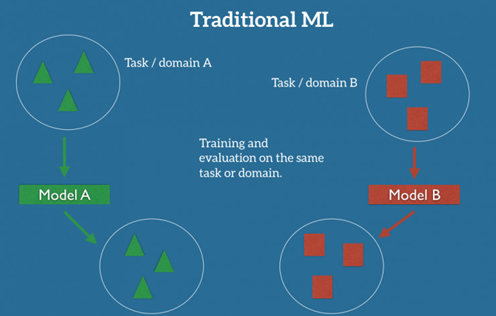
可以预期,我们在该数据集上训练的模型 A,在相同任务/领域的新数据上也能有良好表现。另一方面,对于给定任务/领域 B,我们需要这个领域的标记数据,来训练模型 B,然后才能在该任务/领域取得不错的效果。
但传统的监督学习方法也会失灵——在缺乏某任务/领域标记数据的情况下,它往往无法得出一个可靠的模型。举个例子,如果我们想要训练出一个模型,对夜间的行人图像进行监测,我们可以应用一个相近领域的训练模型——白天的行人监测。理论上这是可行的。但实际上,模型的表现效果经常会大幅恶化,甚至崩溃。这很容易理解,模型从白天训练数据获取了一些偏差,不知道怎么泛化到新场景。
如果我们想要执行全新的任务,比如监测自行车骑手,重复使用原先的模型是行不通的。这里有一个很关键的原因:不同任务的数据标签不同。但有了迁移学习,我们能够在一定程度上解决这个问题,并充分利用相近任务/领域的现有数据。迁移学习试图把处理源任务获取的知识,应用于新的目标难题。
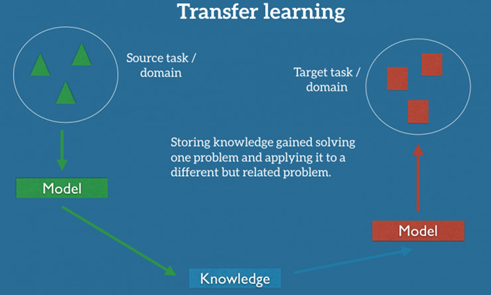
实践中,我们会试图把源场景尽可能多的知识,迁移到目标任务或者场景。这里的知识可以有许多种表现形式,而这取决于数据:它可以是关于物体的组成部分,以更轻易地找出反常物体;它也可以是人们表达意见的普通词语。
-
迁移学习的重要性
在去年的 NIPS 2016 讲座上,吴恩达表示:"在监督学习之后,迁移学习将引领下一波机器学习技术商业化浪潮。"

有一点是毋庸置疑的:迄今为止,机器学习在业界的应用和成功,主要由监督学习推动:最新的残差网络(residual networks)已经能在 ImageNet 上取得超人类的水平;谷歌 Smart Reply 能自动处理 10% 的手机回复;语音识别错误率一直在降低,精确率已超过打字员;机器对皮肤癌的识别率以达到皮肤科医生的水平;谷歌 NMT 系统已经应用于谷歌翻译的产品端;百度 DeepVoice 已实现实时语音生成……这个列表可以搞得很长。我要表达的意思是:这个水平的成熟度,已经让面向数百万用户的大规模模型部署变得可能。
但在另一方面,这些成功的模型对数据极度饥渴,需要海量标记数据来达到这样的效果。在某些任务领域,这样的数据资源是存在的——背后是多年的艰辛数据收集。而在个别情况下,数据是公共的,比如 ImageNet。但是大量的标记数据一般是专有的、有知识产权,亦或是收集起来极度昂贵,比如医疗、语音、MT 数据集。
同时,当机器学习模型被应用于现实情形,它会遇到无数的、此前未遭遇过的情况;也不知道该如何应付。每个客户、用户都有他们的偏好,会产生异于训练集的数据。模型需要处理许多与此前训练的任务目标相近、但不完全一样的任务。当今的尖端模型虽然在训练过的任务上有相当于人类或超人类的能力,但在这些情况下,性能会大打折扣甚至完全崩溃。
近年来,这一波公众对人工智能技术的关注、投资收购浪潮、机器学习在日常生活中的商业应用,主要是由监督学习来引领。如果我们忽略"AI 冬天"的说法,相信吴恩达的预测,机器学习的这一波商业化浪潮应该会继续。相比无监督学习和强化学系,迁移学习目前的曝光程度不高,但越来越多的人正把目光投向它。
迁移学习的智慧体现在什么方面呢?
首先,机器的一个能力是在大数据里学习,所以数据的质量是非常重要的。因此今年AlphaGo的训练数据与去年和李世石下棋时候的数据就做了改变,去年还用了很多人类大事们下棋的数据,但近年更多地用了AlphaGo自我对弈的数据,使得数据质量大幅提高,也就让机器学习的效果大为提高。但是,你能不能把在19x19的棋盘学到的知识再推广到21x21的棋盘里呢?你在学会下围棋之后,你能不能去下象棋,能不能把它运用在生活的方方面面,如商业活动、人际交往、指挥机器人的行动中呢?很显然,目前的机器是没有这个能力的,而迁移学习正式针对于此产生的。
今天的深度学习算法仍然欠缺的,是在新情况(不同于训练集的情况)上的泛化能力。而把别处学得的知识,迁移到新场景的能力,就是迁移学习。
在人类进化中,迁移学习这种能力是非常重要的。比如说,人类在学会骑自行车后,再骑摩托车就很容易了,人类在学会打羽毛球后再学习打网球也会容易很多。我们看一两张照片就可以把它拓展到许多其他不同的景象;我们有了知识,把这个知识再推广到其他知识中,简言之,就是我们能把过去的经验带到不同的新的场景中去,这样就有了一种适应的能力。
那么我们怎样才能让机器也有这种能力呢?最关键的就是发现共性,发现两个领域之间的共性。一旦发现了这种关键的共性,迁移就非常容易。我们在机器学习中称其为特征,即发现这种共同的特征。比如在国内和国外开车为例,国内司机是坐在车的左边,而国外司机是做在右边,我们在国内学会开车后如何能够尽快地学会在国外开车而不出事呢?这里就有一个共性——司机的座位总是靠近路中间的,发现了这个窍门,迁移就容易多了。
下面我们来讨论一下,为何要研究迁移学习以及什么样的迁移学习才是我们的目的。

首先,我们在生活中遇到的更多的是小数据。家里的小朋友看一张猫的照片,那么当他在看到一只真猫,就会说这是猫。我们不用给他一千万个正样本、一千万个负样本,他就能有这种能力,人是自然就有这种能力的。因此小数据上如何实现迁移?这才是真正的智能。
其次是可靠性。我们制造一个系统,希望它不仅是在原来那个领域能够发挥作用,在周边领域也能发挥作用。当我们把周边的环境稍微改一改的时候,这个系统还是可以一样的好,这个就是可靠性。我们可以举一反三、融会贯通,这是我们赋予智慧的一种定义。

第三个好处就是个性化。我们现在越来越多地强调个性化。我们在手机上看新闻、看视频、购物,手机为我们提供个性化的提醒,以后家里有了机器人,这些都是要为我们个人提供服务的,而且这个服务越个性化越好。
-
迁移学习的难点
说了这些之后,你可能要问为什么迁移学习今天还没有大规模地推广?这主要是因为迁移学习本身还是非常非常困难的?如图所示,这里涉及教育学的东西——Learning Transfer。

教育学里,如何把知识迁移到不同的场景,也是非常重要的。在教育学,这个理念已经有上百年的历史。比如我们衡量一个老师的好坏,我们往往可以不通过学生的期末考试,因为那只是靠特定的知识,学生有时候死记硬背也可以通过考试。一个更好的方法,是观察这个学生在上完这门课之后的表现,他有多大的能力能够把这门课的知识迁移到其他的课程里去。那个时候我们再回来说,这个老师的教学是好是坏,这个叫学习迁移。所以,再教育学里大家就在问,为什么学习迁移是如此的难?这个难点就在于如何发现共同点。
再回到刚才开车的例子,有多少人经历过从左边开车到右边开车这种苦恼的事情?对于我们人类来说,发现这种共性也是很困难的。好在迁移学习这个领域已经有了十多年的努力的结果。
-
迁移学习的实现方法
-
样本迁移(Instance-based Transfer Learning)
样本迁移即在数据集(源领域)中找到与目标领域相似的数据,把这个数据放大多倍,与目标领域的数据进行匹配。其特点是:需要对不同例子加权;需要用数据进行训练。一般就是对样本进行加权,给比较重要的样本较大的权重

原本源领域是鸟、牛、狗,目标领域为狗。我们发现源领域中的狗与目标领域有更多的相似数据,所以我们放大源领域中的狗为3张图片。
-
特征迁移(Feature-based Transfer Learning)
特征迁移是通过观察源领域图像与目标域图像之间的共同特征,然后利用观察所得的共同特征在不同层级的特征间进行自动迁移。在特征空间进行迁移,一般需要把源领域和目标领域的特征投影到同一个特征空间里进行。

-
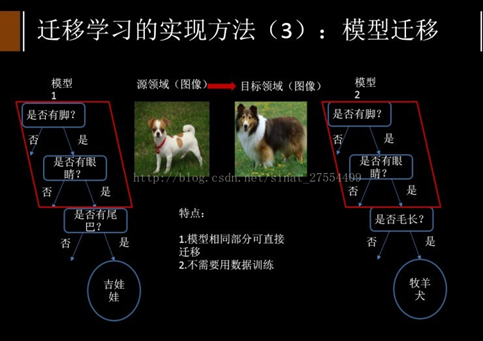
模型迁移(Model-based Transfer Learning)
模型迁移利用上千万的图象训练一个图象识别的系统,当我们遇到一个新的图象领域,就不用再去找几千万个图象来训练了,可以原来的图像识别系统迁移到新的领域,所以在新的领域只用几万张图片同样能够获取相同的效果。模型迁移的一个好处是我们可以区分,就是可以和深度学习结合起来,我们可以区分不同层次可迁移的度,相似度比较高的那些层次他们被迁移的可能性就大一些。
-
关系迁移(Relational Transfer Learning)
如社会网络,社交网络之间的迁移。

-
-
一个迁移学习的具体实现样例
在本例中,我们需要用深度学习技术对电影短评进行文本倾向性分析,例如"It was great,loved it."表示积极正面的评论,"It was really stupid."表示消极负面的评论。
假设现在可以得到的数据规模只有72条,其中62条没有经过预先的倾向性标记,用来预训练。8条经过了预先的倾向性标记,用来训练模型。2条也经过了预先的倾向性标记,用来测试模型。由于我们只有8条经过预先标记的训练数据,如果直接以这样的数据量对模型展开训练,无疑最终的测试准确率将非常低。(因为判断结果只有正面和负面两种,因此可以预见最终的测试准确率可能只有50%)
为了解决这个难题,我们引入迁移学习。即首先用62条未经标记的数据对模型展开通用的情感判断,然后在这一预训练的基础上对本例的特定问题展开分析,复用预训练模型中的部分层次,就可以将最终的测试准确率提升到100%。下面将从3个步骤展开分析。
-
步骤1
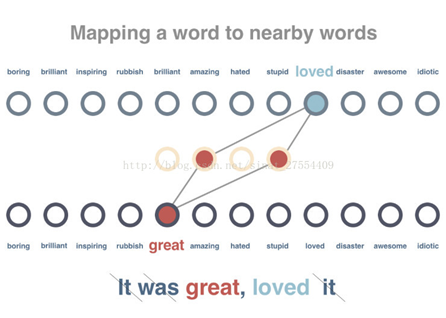
创建预训练模型来分析词与词之间的关系。这里我们通过分析未标记语句中的某一词汇,尝试预测出现在同一句子中的其他词汇。

-
步骤2
对模型展开训练,使得出现在类似上下文中的词汇获得类似的向量表示。在这一步骤中,62条待处理语句首先会被删除停用词,并被标记解释。之后,针对每个词汇,系统会尝试减小其向量表示与相关词汇的差别,并增加其与不相关词汇的差别。
-
步骤3
预测一个句子的文本倾向性。由于在此前的预训练模型中我们已经得到了针对所有词汇的向量表示,并且这些向量具有用数字表征的每个词汇的上下文属性,这将使得文本的倾向性分析变得更易于实现。

需要注意的是,这里并非直接使用10个已经被预先标记的句子,而是先将句子的向量设置为其所有词汇的平均值(在实际任务中,我们将使用类似时间递归神经网络LSTM的相关原理)。这样,经过平均化处理的句子向量将作为输入数据导入模型,而句子的正面或负面判定将作为结果输出。需要特别强调的是,这里我们在预训练模型和10个被预先标记的句子之间加入了一个隐藏层(hidden layer),用来适配文本倾向性分析这一特定场景。正如你所看到的,这里只用10个标记量就实现了100%的预测准确率。
当然,必须指出的是,这里展示的只是一个非常简单的模型示意,而且测试用例只有2条。但不可否认的一点是,由于迁移学习的引入,确实使得本例中的文本倾向性预测准确率从50%提升到了100%。
本例的完整代码详见如下链接:https://gist.github.com/prats226/9fffe8ba08e378e3d027610921c51a78
-
-
NanoNets工具
NanoNets是一个简单方便的基于云端实现的迁移学习工具,其内部包含了一组已经实现好的预训练模型,每个模型有数百万个训练好的参数。用户可以自己上传或通过网络搜索得到数据,NanoNets将自动根据待解问题选择最佳的预训练模型,并根据该模型建立一个NanoNets(纳米网络),并将之适配到用户的数据。NanoNets和预训练模型之间的关系结构如下所示。
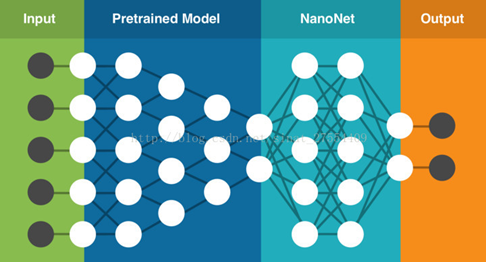
以蓝黑条纹还是白金条纹的连衣裙为例,用户只需要选择待分类的名称,然后自己上传或者网络搜索训练数据,之后NanoNets就会自动适配预训练模型,并生成用于测试的web页面和用于进一步开发的API接口。如下所示,图中为系统根据一张连衣裙图片给出的分析结果。

具体使用方法详见NanoNets官网
-
迁移学习的进展
-
结构和内容分离
如果我们面临一个机器学习问题,并想要发现不同问题之间的共性,那么我们可以把问题的结构和问题的内容剥离开。虽然这样的分离并不容易,但是一旦能够完成,那么系统举一反三的能力就非常强了。举个例子,大家可能认为写电影剧本是一个非常需要艺术,非常需要天才的工作。但是大家可能不知道,写电影剧本也可以变得像工厂一样。剧作家的诀窍就是把内容和结构剥离开,他们知道电影头 10 分钟该演什么,后 5 分钟又该演什么,在什么时候应该催人泪下,在什么时候让大家捧腹大笑,这些都是有结构的。
-
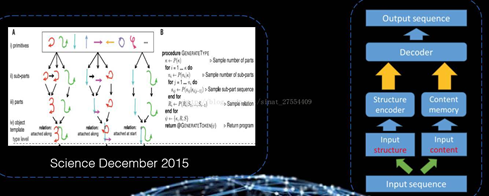
怎样让机器学习也具有这个能力呢?上图的左边是 2005 年《Science》的一篇文章,该论文在手写识别上把结构和手写的方式区分开,并发现了在学习结构的这一方面用一个例子就可以了,所以这也就是单个例学习。
右边是一项关于文本结构的研究,在大规模的文本上,如果我们能够把文本的结构和具体的内容用一个深度学习网络给区分开的话,那么学到结构这一部分的系统就很容易迁移到自然语言系统并处理不同的任务。比如说主题识别、自动文本摘要、自动写稿机器人等,这一部分真的比较有前景
-
多层次的特征学习
过去我们在学习方面太注重发现共性本身,但是却没有注意在不同层次之间发现共性。现在发现,如果我们把问题分到不同层次,有些层次就更容易帮助我们进行机器学习的迁移。

如上图图像识别任务中,如果我们在一个领域已经用了上千万的数据训练好了一个八层的深度学习模型,但现在如果我们改变了该分类任务的类别,那么传统的机器学习就必须重新进行训练。但是现在用了这种层次型的迁移学习,我们会发现,不同的层次具有不同的迁移能力,这样对于不同的层次的迁移能力就有了一个定量的估计。所以,当我们需要处理新任务时,就可以把某些区域或某些层次给固定住,把其他的区域用小数据来做训练,这样就能够达到迁移学习的效果。
在语音任务当中,假设我们已经训练出一个播音员的语音模型,那么我们如果把它迁移到一种带口音的语音中呢?我们其实也可以用这种层次化的迁移,因为如果我们发现一些共性的、内在的层次是语音共同的模式,那么我们就可以把它迁移过来,再使用小数据就能训练方言了。
同时如上图所示,我们对于结构也可以像工程师一样,进行各种各样的变换,比如说我们可以在图像、文字之间发现他们语义的共性。同时如果我们可以用一个多模态的深度学习网络把内部语义学出来,这样就可以在文字和图像之间自由的迁移。所以这种多层的迁移,确实带来很多的便利。
-
从一步到位的迁移学习到多步、传递式的迁移学习
过去的迁移学习,往往是我也有一个领域已经做好了模型,而目标是把它迁移到一个新的领域。这种从旧领域迁移到新领域,从一个多数据的领域迁移到少数据的领域,这种称之为单步迁移。但是我们现在发现,很多场景是需要我们分阶段进行的,这就像过河,需要踩一些石头一步步过去。
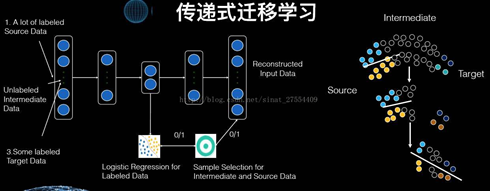
采用这个思想,我们也可以进行多步传导式的迁移。比如说我们可以构建一个深度网络,而这个网络的中间层就既能照顾目标这个问题领域,又能照顾原来的领域。同时如果我们有一些中间领域,那么其可以把原领域和目标领域一步步的衔接起来,A 和 B、B 和 C、C 和 D。这样我们就可以定义两个目标函数,左下角目标函数的任务就是分类,并且分类分得越准越好,右下角第二个目标函数需要区分在中间领域到底抽取哪些样本和特征,使得其对最后的优化函数是有用的。当这两个目标函数一同工作时,一个优化了最后的目标,而另一个则选择了样本。如此迭代,逐渐就如同右边那个图一样,原领域的数据就从多步迁移到目标领域去了。
最近斯坦福大学有一个实际的例子,他们利用这种多步迁移方法,并通过卫星图像来分析非洲大陆的贫穷状况。从白天到晚上的卫星图像是第一步迁移,从晚上的图像、灯光到这个地方发达程度是第二步迁移。因此我们通过这两步的迁移成功地建立了一个模型,即通过卫星图像分析地方的贫困状况。
-
学习如何迁移
这 20 年当中我们积累了大量的知识,并且有很多种迁移学习的算法,但现在我们常常遇到一个新的机器学习问题却不知道到底该用哪个算法。其实,既然有了这么多的算法和文章,那么我们可以把这些经验总结起来训练一个新的算法。而这个算法的老师就是所有这些机器学习算法、文章、经历和数据。所以,这种学习如何迁移,就好像我们常说的学习如何学习,这个才是学习的最高境界,也就是学习方法的获取。
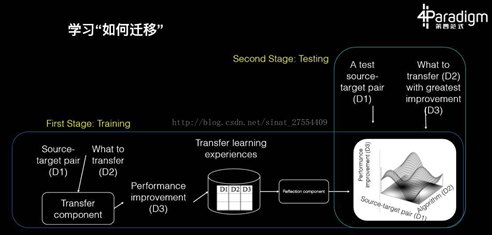
有人就在做这样的研究,最后学出的效果就是在给定任何一个迁移学习问题,系统可以自动在过去所有我们尝试过的算法里面,利用经验找到最合适的算法,其可以是基于特征的、基于多层网络的、基于样本的或者是基于某种混合。
-
迁移学习作为元学习
第五个进展,把迁移学习本身作为一个元学习(Meta Learning)的方法,赋予到不同学习的方式上。假设以前我们有一个机器学习的问题或者是模型,现在你只要在上面套一个迁移学习的罩子,它就可以变成一个迁移学习的模型了。这种套一个罩子的办法怎样才能够实现呢?现在就在强化学习和深度学习上做这样的实验,假设你已经有一个深度学习模型和一个强化学习模型,那么我们在上面做一个「外套」,能够把它成功变成一个迁移学习模型。

举个例子,假设存在个性化的人机对话系统,而我们做了一个任务型的对话系统,它是可以帮助我们做通用型的对话。但是如何能够把这个系统变成一个个人的、个性化的系统呢?我们既用深度学习、RNN,又用强化学习和所谓的 POMDP 来做了一个通用型的任务学习系统。现在我们就可以通过几个个性化的例子而得到个性化的选择。
-
数据生成式迁移学习
下面进入到最后一个进展,即数据生成式的迁移学习。我们最近听到比较多的是生成式对抗网络,这个词听起来有点复杂,但是这个图就是最好的解释。对于生成式对抗网络来说,图灵测试外面的裁判是学生,里面的那个机器也是学生,他们两个人的目的是在对抗中共同成长,在问问题当中,假设提问者发现一个是机器了,那么就告诉机器你还不够真,还需要提高自己。而如果机器发现它把人骗过了,那么它可以去告诉外面这个裁判,它还不够精明,还需要提高自己。这样两方不断互相刺激,形成一种对抗,这个是一种共同学习的特点。

所以,这种生成式对抗网络的一个特点,通过小数据可以生成很多模拟数据,通过模拟数据又来判定它是真的还是假的,用以刺激生成式模型的成长。这个就好象是计算机和人之间的博弈,下图左边展示的是一棵博弈树。
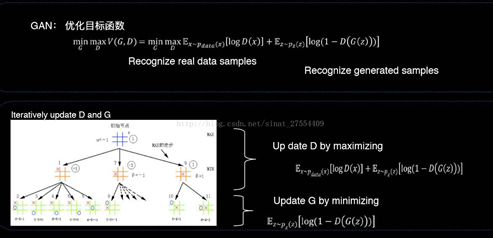
我们可以用这个方法来做迁移学习,这里举的一个例子是最近的一项工作,我们用判别式模型来区分数字到底是来自于源数据还是目标数据。我们让生成式模型不断模拟新的领域,使得到最后我们能够产生出一大堆新数据,它的数据就是和真实的数据非常的一致。通过这个办法,一个判别器区分领域,另外一个生成器在生成数据,我们就可以通过小数据产生更多的数据,在新的领域就可以实现迁移学习的目的。
最后我要说,我们在深度学习上已经有了很大的成就,我们今天也在努力进行各种强化学习的尝试(比如说 AlphaGo),但是我认为机器学习的明天是在小数据、个性化、可靠性上面,那就是迁移学习,这是我们的明天。
本文学习自https://blog.csdn.net/sinat_27554409/article/details/72848267,如有冒犯,请留言告知我删帖!