结对作业——第二次作业
1.结对成员:
031502537 叶己峰
031502518 练斐弘
2.Github链接:
Github链接:https://github.com/fdggfdggyjf/SD_Match
作业地址:http://www.cnblogs.com/easteast/p/7604534.html
3.作业描述:
- 1、构造输入数据的生成程序,实现可定制的输入数据(输入数据是指input_data.txt)。在博客中举一个样例(贴出关键数据即可),并说明生成数据的所考虑因素。
- 2、需要为智能匹配算法确立几条分配或排序原则,比如兴趣优先、或活动时间优先、或其他等等,请你们结对讨论确定。
- 3、给出结果分析,分析自己的输出是否达到算法所达到的指标。关于相关指标条件,每个组感受应当不同,请把想法写在博客中。
- 4、代码需要遵循一定的规范,在博客中描述结对团队遵循的代码规范,并截取部分关键代码佐证说明。
- 5、本次结对项目实现使用程序语言不做具体限制,但需要能生成Windows平台的可执行文件。C/C++/C#编译后即可生成,其他语言可以使用打包工具把依赖打包上传,比如exe4j。但注意,本次没有重测机会,请确保你项目的所有依赖文件都上传到了Github中。为确保没有问题,最好在无相应语言环境的机器上克隆项目并进行测试。
- 6、代码提交在GitHub上,并给GitHub链接。
- 7、两个人发布独立博客,包含上述内容的描述,同时包含结对感受,以及两个人对彼此结对中的闪光点或建议的分享。项目的测试分数两人共享,博客的分数各自独立。博客可以有共享的架构设计图等,但不可雷同,否则视作抄袭。
- 8、助教将收集各组成员的程序,并基于一组特殊数据进行测试(该测试数据遵循下面的输入规范,该数据由助教根据真实场景讨论得出,作业评定时会给出,事先不对外公布)。测试结果基于全部同学的输出,助教将统计各组同学对于各个部门录取相关人员的频率,得出一组部门与成员的录取关系数据(该数据遵循下面的输出规范),并与各组同学的数据作对比,最终评判同学们的测试结果。
4.生成数据
在做这个生成程序之前,我们原本是计划全部采用随机生成,像学生学号、部门编号、空闲时间段、志愿申请都是用随机生成的,然后用一个string数组记下,然后符合条件的取出来用
但是在写生成编号和时间段时,发现一是这样会花费大量时间判断数据是否重复,重复的数据要丢弃重新生成;二是会有大量数据是不满足要求的。
最后再仔细观察作业输入实例,结合考虑因素,还是决定采用 枚举法 + 随机数rand() + bool数组
(1) 考虑因素:
- 数据要具有随机性;
- 数据要具有有效性,像部门志愿不能出现没有的部门
- 数据不能重复,像一个学生的兴趣标签不能有两个是一样
(2) 先枚举如下数据:
string all_tags[10] = {"reading","programming","film","English","music",
"dance","basketball","chess","running","swimming"};
string freeweek[7] = {"Mon.","Tues.","Wed.","Thurs.","Fri.","Sat.","Sun."};
string freetimes[8] = {"08:00~10:00","9:00~11:00","10:00~12:00","14:00~16~00","15:00~17:00",
"18:00~20:00","19:00~21:00","20:00~22:00"};
string all_department_no[20] = {"D001","D002", "D003", "D004", "D005", "D006","D007","D008", "D009", "D010",
"D011", "D012","D013","D014","D015","D016", "D017", "D018","D019","D020" };
(3) 使用如下条件来生成数据:
- 学生学号、部门编号:
- a) 按顺序生成,逐个递增加1,然后int型化为string型保存
- b) 学生以”031502xxx“格式,部门按”D0xx“格式
- c) 学生300人,部门20个
- 空闲时间、活动时间:
- a) 从枚举的日期和时间段获取,使用二维数组 bool time[x][y]来标记,分别表示日期和时间段
- b) 两小时为一个时间段,而且从8:00到22:00,中间还抛开午餐晚餐休息时间
- 部门志愿:
- a) 因为部门志愿有优先级,所以只能用原来的方式string数组记录
- b) 志愿个数是从0~5个(在评论中看到助教说最少会有一个志愿,但是特殊测试数据中会有志愿为空的情况,考虑之下还是把0也取上)
- 兴趣标签、部门标签:
- a) 每个学生和部门至少有两个以上的标签,不会超过10个
- b) 从枚举的标签中获取,用bool数组标记,避免数据重复
(4) 利弊分析:
使用枚举法 + 随机数 + bool数组方法无疑很好解决了生成数据无效和重复的问题,但是缺点也很明显,生成的数据很死板,和现实生活的会有较大误差。
(5) 生成的最好一组数据:
请戳我
5.数据建模及匹配程序的思路及实现方式
(1).整个程序模型
主要由三部分组成:生成数据程序、匹配算法程序、json格式输入输出程序
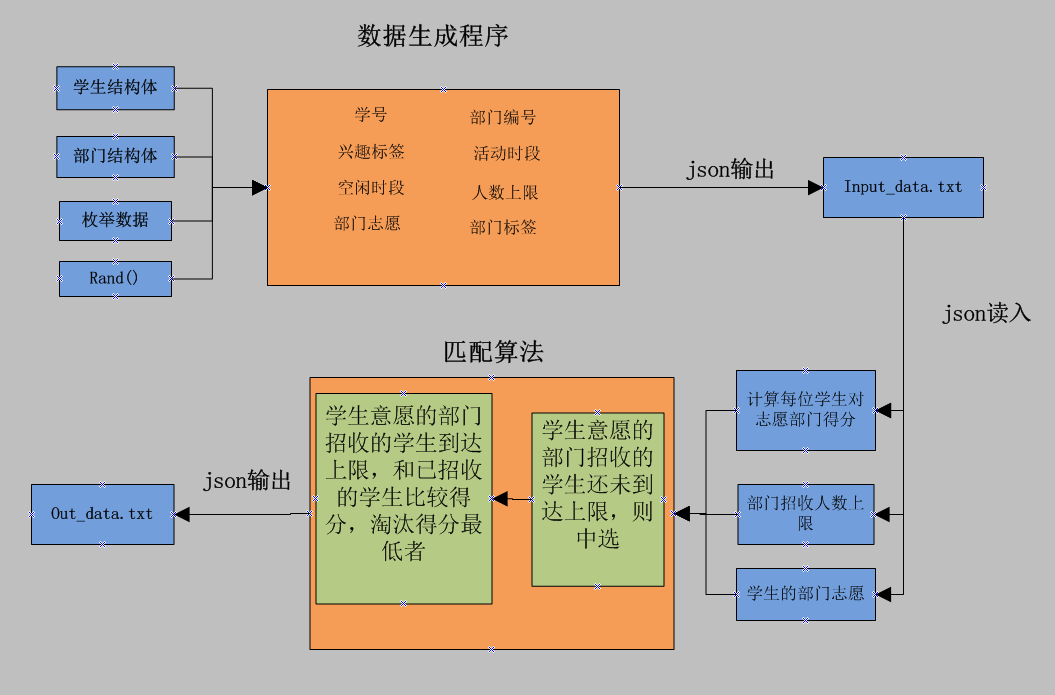
(2).数据模型
- 学生模型:
- 1)学号——按顺序生成
- 2)空闲时段——从枚举的日期和时间段中组合,用bool数组标记
- 3)空闲时段个数
- 4)兴趣标签——从枚举的兴趣标签中挑选,用bool数组标记
- 5)兴趣标签个数
- 6)部门意愿——从枚举的部门意愿中挑选,用string数组记录
- 7)部门意愿个数
- 8)加入的部门个数
- 9)在所意愿的部门中综合得分——计算方法在后面匹配算法中提到
- 部门模型:
- 1)部门编号——按顺序生成
- 2)招收学生数的上限
- 3)兴趣标签——从枚举的兴趣标签中挑选,用bool数组标记
- 4)兴趣标签个数
- 5)空闲时段——从枚举的日期和时间段中组合,用bool数组标记
- 6)空闲时段个数
(3).匹配程序的思路
-
- 先列出当初我们讨论的头脑风暴(注:由于我们算法能力不足,并没有完全解决所提出的问题)
- a) 基于学生在每个意愿部门上的得分来进行分配,显然更加简洁明了
- b) 计算学生对每个部门的相应得分要考虑: 这个部门在学生部门意愿优先度、 部门活动时间和学生空闲时间的重合度、部门标签和学生兴趣标签重合度、 当前学生已加入的部门个数(加入个数越多得分越低);
- c) 当学生因为得分最低而被淘汰时,其得分全都要重新计算;
- d) 当学生的一个空闲时间段和两个意愿部门的活动时间重叠时,则该时间段计算到意愿优先度高的部门;
- e) 当学生的部门意愿为空或者学生一个部门意愿都没中选,考虑把学生分配给部门意愿外的部门;
- f) 当学生的空闲时段和部门活动时段没有一个重合时,该学生的得分应该置0。
-
- 计算得分的规则:
部门意愿优先度得分:第一意愿部门得50分,第二意愿部门得30分,第三、四、五意愿部门得10,7,3分。站在学生角度上,第一个意愿部门应该在得分中占较大比重。
时间重叠度得分:用1小时来考虑,重叠1小时得40分,2小时得50分,3小时以上得55分,如果一次都没有分数置为0。学生必须得有时间来参加部门活动,所以时间重合度也应占较大比重,但同时学生也不要把太多时间用于部门,所以当时间重合超过3小时以上得分不变。
标签重合度得分:重合一个标签相符得10分,标签越多,就越和部门志趣相投,所以成正比;
-
- 实现方法:
该匹配算法目的为得到一个让学生和部门都尽量满意的分配方案。
首先从学生的第一意愿部门出发,如果该部门招收学生人数未到上限,那么就中选;如果招收学生人数已达上限,那就得分和已招收的学生中最低得分比较,高于最低得分就取代最低得分的那个同学,低于最低得分那该第一意愿就废弃。
同理,再从第二意愿出发... ...
使用这种方式可以确保部门招收的同学都是排名前列的,同时同学的每个意愿都经过考虑不会有遗漏。
- 实现方法:
-
4)结果分析:
大体上看,其结果还是满足预期的。但是就是未得到分配的学生有点多,这是因为我们算法是根据学生的部门意愿来进行分配的,一旦300个人都选择热门部门,就一定会有大量的人落选,要想解决这个问题就需要改进算法,实现想法 e)考虑把学生分配给部门意愿外的部门。希望后面能有时间把想法都实现了。
有学生申请的部门的申请列表中,将学生先按时间符合排序,再按标签符合排序,取所有可取的,且少于部员数量限制的学生,加入 matched 数组,否则再将申请列表剩下的学生按时间符合排序,取所有可取的,且少于部员数量限制的学生,加入 matched 数组。
6.代码规范
1.对代码的注释放在其上方或者右边:
2.变量命名使用驼峰式,而且使用下划线,力求让人见字知意
3.在代码缩进上规范使用4个空格
4.在每个函数头部上方都有相应注释,说明函数实现的功能
5.每个大括号一定要单独一行
//部门结构体
struct Department
{
string department_no; //部门编号(唯一确定值),字符
int member_limit; //各部门需要学生数的要求的上限,单个,数值,在[10,15]内;
int tags_num; //部门的特点标签个数
int tags[10]; //各部门的特点标签,多个(两个以上),字符;
int event_schedules_num; //各部门的常规活动时间段个数
int event_schedules[7][8]; //各部门的常规活动时间段,多个(两个以上),字符。
};
//常规活动时间段
dep[i].event_schedules_num = unsigned(rand()%6) + 2;
for(int j = 0; j < dep[i].event_schedules_num; j++)
{
int t1 = unsigned(rand()%7);
int t2 = unsigned(rand()%8);
if(dep[i].event_schedules[t1][t2]==1)
j--;
else
dep[i].event_schedules[t1][t2] = 1;
}
7.结对感受
本次作业完成进度超乎预料的慢,甚至到截止时间还有部分没有完成,分析其原因:其一是这次作业正值国庆假期,我和队友都回家了,然后在完成本次作业上线上的交流是不如面对面交流来的流畅,无法很好了解双方工作进度;其二是在家中无法像在校去投入更多精力去完成任务。
当然,通过这次作业也收获很多感受。不同于第一次结队作业,这次要求写代码,然后当两个人代码整合时,代码不规范的确是非常折磨人的;再然后是在用Jsoncpp读取、输出json格式上,花费大量时间去搞这个东西,一直出现错误,但是非常佩服我队友,在我放弃改用自己写代码模仿输出json格式时,他熬夜查资料去搞定了这个东西。