本篇写的demo是爬取军事网站,因为我是军事迷嘿嘿。
你们运行一下就好了,不要乱爬,爬虫是有爬取礼仪的,如果你爬取频率过高就是不礼貌的,会被封ip的。
先上文档:PHP蜘蛛爬虫开发文档 代码中不明白的可以进去搜索。
在demo目录中新建demo.php
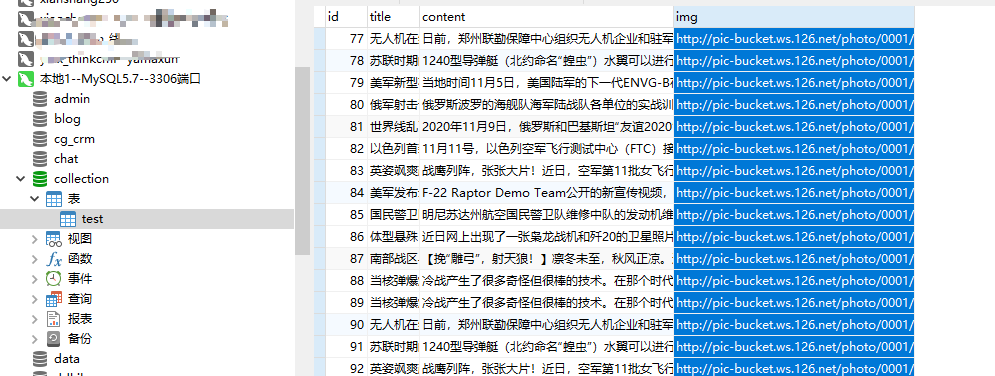
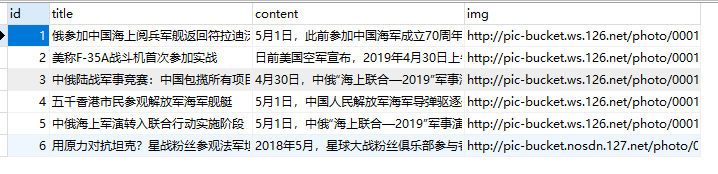
<?php require_once __DIR__ . '/../autoloader.php'; use phpspidercorephpspider; /* Do NOT delete this comment */ /* 不要删除这段注释 */ $configs = array( 'name' => '军事', // 给你的爬虫起一个名字 'log_show' => false, // 是否显示日志 'tasknum' => 1, // 开启多少个进程爬取 // 数据库配置 'db_config' => array( 'host' => '127.0.0.1', 'port' => 3306, 'user' => 'root', 'pass' => 'root', 'name' => 'collection', ), // 数据库表,表需要已存在,collection库,test表 'export' => array( 'type' => 'db', 'table' => 'test', ), // 爬取的域名列表 'domains' => array( 'war.163.com' ), // 抓取的起点 'scan_urls' => array( 'http://war.163.com' ), // 列表页实例,你要爬取的列表,也就是分页 'list_url_regexes' => array( "http://war.163.com" ), // 内容页实例,文章的内容页 // d+ 指的是变量,就是可变的参数 'content_url_regexes' => array( "http://war.163.com/photoview/4T8E0001/d+", ), // 失败重新爬取次数 'max_try' => 5, // 爬取规则配置 'fields' => array( array( 'name' => "title", // 数据库字段名 'selector' => "//div[@class='headline']/h1", // 规则,表示:headline类里的h1标签 'required' => true, // 如果为空,整条数据丢弃 ), array( 'name' => "content", 'selector' => "//div[@class='overview']/p", 'required' => true, ), array( 'name' => "img", 'selector' => "//img[@class='firstPreload']", 'required' => true, ), ), ); $spider = new phpspider($configs); $spider->start();
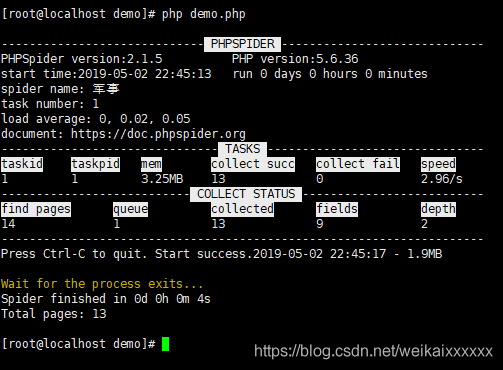
运行
# php demo.php
运行个几秒ctrl+c停止。
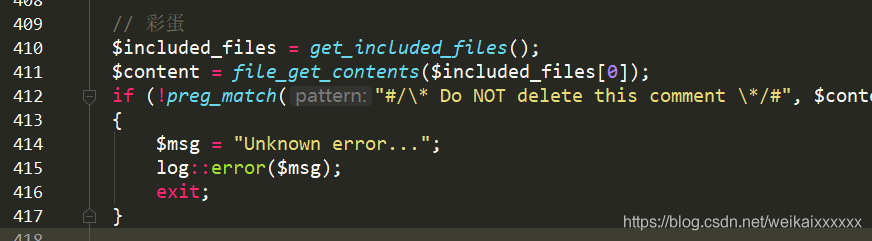
如果你运行出现了这个错误
那是因为你把那俩行注释给删了,作者真是闲的蛋疼。
如果你想去掉那注释,就去掉phpspider.php这判断的代码
说了这么多,你是不是想问:那我咋改成我要爬取的站点呢?
1、打开你要爬取的站点,然后按F12。。
例如,本篇的地址为:https://war.163.com/ ,也就是list_url_regexes字段的地址
这个地址就是content_url_regexes字段中的,d+就是文章的变量,是一个会变的值,通常是id。
2、再按F12,进入文章内容页。
http://war.163.com/photoview/4T8E0001/2301433.html#p=EE5Q9HE94T8E0001NOS
3、再次F12
此时的类名就是fields字段中的title数组,也就是我们要爬取的标题,表示:headline类里的h1标签的文本。内容与图片都是一样的操作方法。你还可以选择更多。
做php开发,你是知道模版这个玩意的,就是内容页,是不会变化的,即使是列表分页也是同一个模版。所以,这些标签什么的都是不会变的。这就使得只需要配置分页的地址+文章地址就ok了。
转载:https://blog.csdn.net/weikaixxxxxx/article/details/89763488
---------------------------------------------------------------------------------------------------------------
spider.php
<?php /** * Created by : PhpStorm * User: yh * Date: 2020/11/14 * Time: 10:42 */ require 'vendor/autoload.php'; use phpspidercorephpspider; /* Do NOT delete this comment */ /* 不要删除这段注释 */ $configs = array( 'name' => '军事', // 给你的爬虫起一个名字 'log_show' => false, // 是否显示日志 'tasknum' => 1, // 开启多少个进程爬取 // 数据库配置 'db_config' => array( 'host' => '127.0.0.1', 'port' => 3306, 'user' => 'root', 'pass' => 'root', 'name' => 'collection', ), // 数据库表,表需要已存在,collection库,test表 'export' => array( 'type' => 'db', 'table' => 'test', ), // 爬取的域名列表 'domains' => array( 'war.163.com' ), // 抓取的起点 'scan_urls' => array( 'https://war.163.com' ), // 列表页实例,你要爬取的列表,也就是分页 'list_url_regexes' => array( "https://war.163.com" ), // 内容页实例,文章的内容页 // d+ 指的是变量,就是可变的参数 'content_url_regexes' => array( "https://war.163.com/photoview/4T8E0001/d+", ), // 失败重新爬取次数 'max_try' => 5, // 爬取规则配置 'fields' => array( array( 'name' => "title", // 数据库字段名 'selector' => "//div[@class='headline']/h1", // 规则,表示:headline类里的h1标签 'required' => true, // 如果为空,整条数据丢弃 ), array( 'name' => "content", 'selector' => "//div[@class='overview']/p", 'required' => true, ), array( 'name' => "img", 'selector' => "//img[@class='firstPreload']", 'required' => true, ), ), ); $spider = new phpspider($configs); $spider->start();