在windows电脑里面搭建的一个简单的HDFS(Hadoop 分布式文件系统)
用了三个服务器:IP地址分别为:
192.168.233.3 HDFS的名称节点:NameNode
192.168.233.4 HDFS的数据节点:DataNode 和 HDFS的第二名称节点 SecondearyNameNode
192.168.233.5 HDFS的数据节点:DataNode
其中192.168.233.3中的NameNode是用来存放元数据的(文件的大小、文件的拥有者、文件的权限等等)
192.168.233.4和192.168.233.5中的DataNode是用来存放文件内容的(存放的文件会被切分成多个数据块,然后存放在不同的DataNode中)
(1)上传HDFS相关的jar包,这里应用的是hadoop-1.2.0.tar.gz
下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-1.2.0/hadoop-1.2.0.tar.gz
(2)解压:tar -zvxf hadoop-1.2.0.tar.gz
(3)创建快捷方式:

(4)修改配置文件:
来源配置信息:http://hadoop.apache.org/docs/r1.2.1/single_node_setup.html
在下载的解压的包中有docs/core-default.html里面有详细的介绍各个参数配置有什么具体意思
/home/hadoop-1.2/conf/core-site.xml
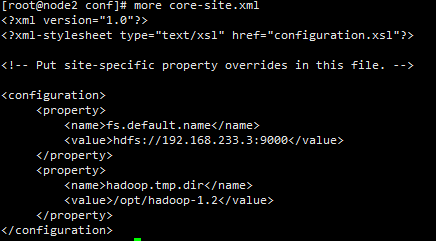
fs.default.name:这个是客户端进行访问的ip地址和端口号,但是浏览器采用的是http协议,所以浏览器访问的端口号是50070,这个地址就是NameNode的地址
hadoop.tmp.dir:后续的DataNode都是基于这个地址,此参数默认的是linux的tmp目录,这里必须要配置,否则,服务器重启的时候,tmp文件夹会清空,会导致上传的文件丢失。这个/opt/hadoop-1.2目录不需要手动创建,在NameNode初始化的时候,NameNode会自己创建
/home/hadoop-1.2/conf/hdfs-site.xml
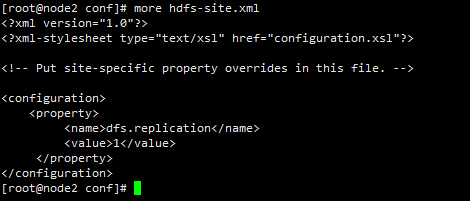
dfs.replication这是DataNode中的block数据块的副本数量,因为是NameNode本台服务器的副本数,所以设置为1,如果不设置的话,默认是3,就是说DataNode中的block数据块的所有副本都在NameNode这台服务器上,这样的话,一旦服务器硬盘损坏的话,数据就会无法找回,所以必须要放在不同的服务器上。
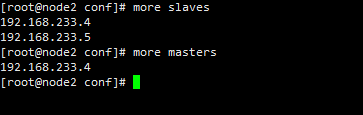
于此同时需要配置其它DataNode中的block 的IP地址,在如下配置文件中添加。其中的masters配置的IP地址是secondNameNode 的地址,只要和NameNode不是同一IP地址就行,如果和NameNode地址一致,一旦NameNode出现问题,那么NameNode存储的所有信息就会丢失,而配置了SecondNameNode后,可以恢复部分数据。
(5)ssh 设置免密码登录,就是各个DataNode和NameNode之间进行信息通讯,不需要进行密码连接。主要是在启动NameNode节点的时候,直接就可以启动其它的DataNode节点,为了方便在一台服务器上启动其它的服务器,比如在192.168.233.3服务器上写一个shell脚本,来启动其它服务器上的节点。
执行如下命令:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
就会创建一个公钥和一个私钥,如图:
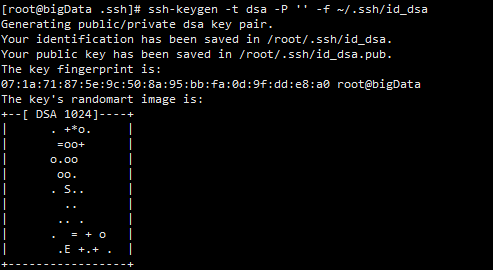
在/root/.ssh目录下会有两文件产生:id_dsa文件和id_dsa.pub文件
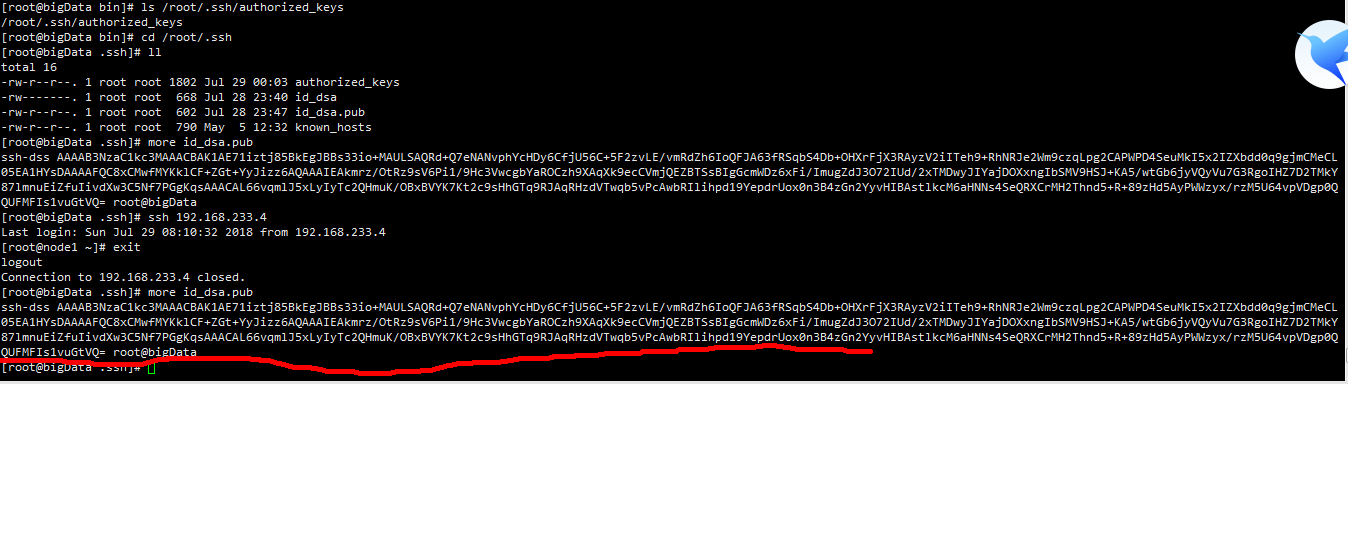
这个是192.168.233.3服务器产生的,上面画红线部分是id_dsa.pub文件的内容,如果要ssh 192.168.233.4服务器的话,需要将id_dsa.pub文件的内容复制的233.4服务器上的/root/.ssh/authorized_keys文件中,先将id_dsa.pub文件复制到233.4服务器上,执行如下命令:
scp id_dsa.pub root@192.168.233.4:/tmp
然后切换到233.4服务器上去,执行如下命令:
cat /tmp/id_dsa.pub >> /root/.ssh/authorized_keys
将id_dsa.pub文件的内容复制到需要登录的服务器上,并且将内容添加到目标服务器上的/root/.ssh/authorized_keys文件中。可以执行如下命令:
scp id_dsa.pub root@192.168.233.4:/tmp:将id_dsa.pub文件远程复制到233.4服务器的tmp文件中,然后再登录到233.4服务器上,执行如下命令:
cat /tmp/id_dsa.pub >> /root/.ssh/authorized_keys:将id_dsa.pub文件内容追加到authorized_keys文件中。
注意:将id_dsa.pub文件内容复制到远程服务器上的authorized_keys文件夹中,不要手动复制,这样不会生效,需要使用命令cat id_dsa.pub >> authorized_keys
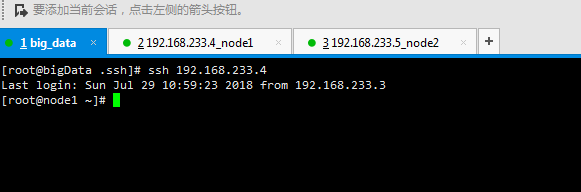
接下来就可以免密登录了,如图:
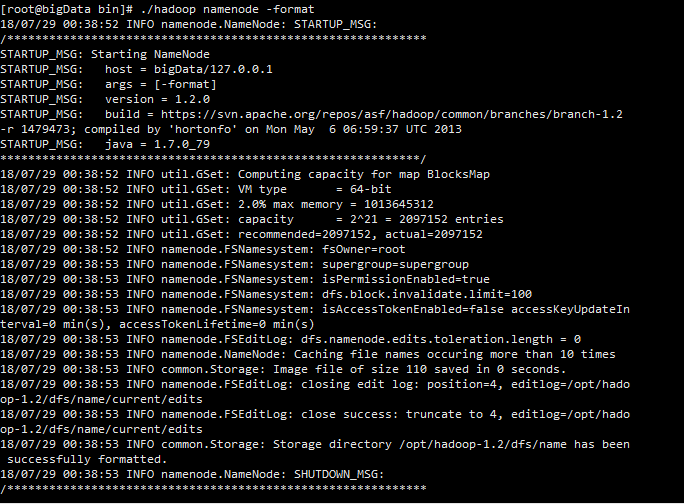
(6)初始化hdfs:
在Hadoop的bin目录下执行如下命令:./hadoop namenode –format
此命令的作用是使得之前配置的core-size.xml内容生效和hdfs-size.xml内容生效
(7)在hadoop的dfs启动的配置文件中配置JAVA_HOME路径,修改如下的配置文件:
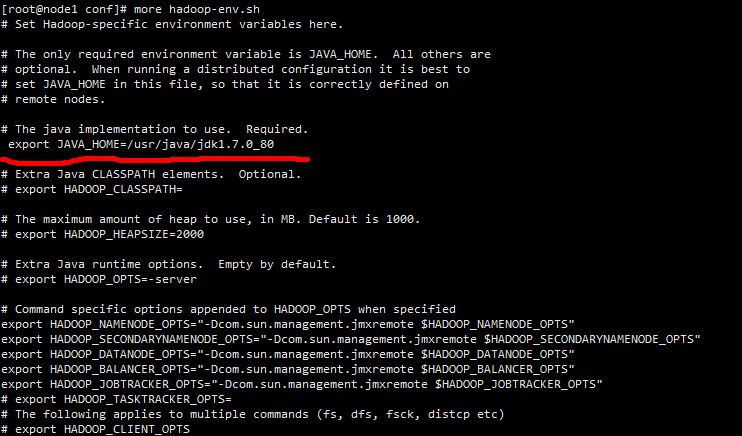
上面的export JAVA_HOME必须要打开,并且要和安装的jdk配置的路径保持一致
怎么样查看安装的jdk,在如下的目录下:
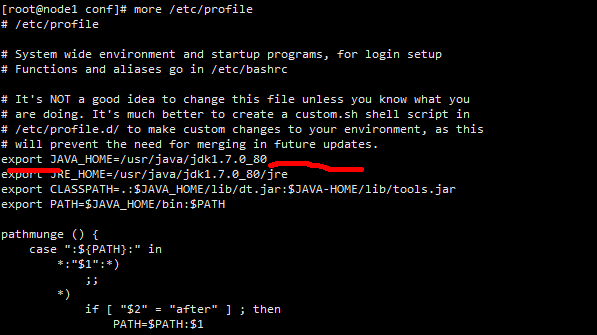
这就是安装的全局变量JAVA_HOME,要和hadoop 的conf文件夹里面的hadoop-env.sh配置JAVA_HOME保持一致。修改完之后要保证其他的dataNode上的配置文件保持一致。
(8)将conf下的所有文件复制到其它的dataNode 上去。
先切换到conf目录再执行如下命令:
scp ./* root@192.168.233.4:/root/hadoop-1.2.0/conf
scp ./* root@192.168.233.5:/root/hadoop-1.2.0/conf
(9)启动hdfs(特别要注意的是,要将服务器的防火墙进行关闭,否则启动DataNode的时候会失败!!)
Service iptables stop 关闭防火墙

可以通过jps命令查看NameNode是否启动成功
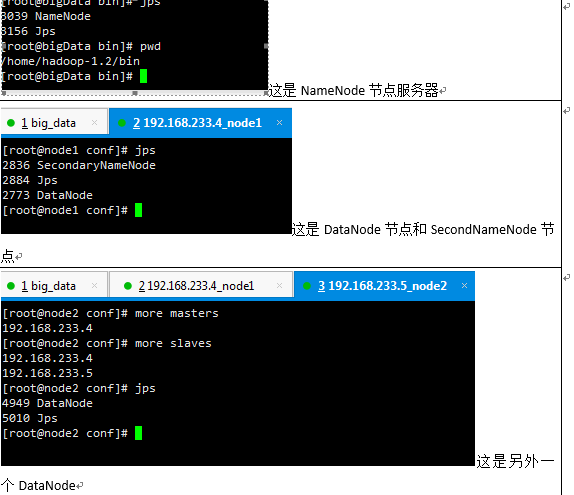
(11)停止命令:./stop-dfs.sh
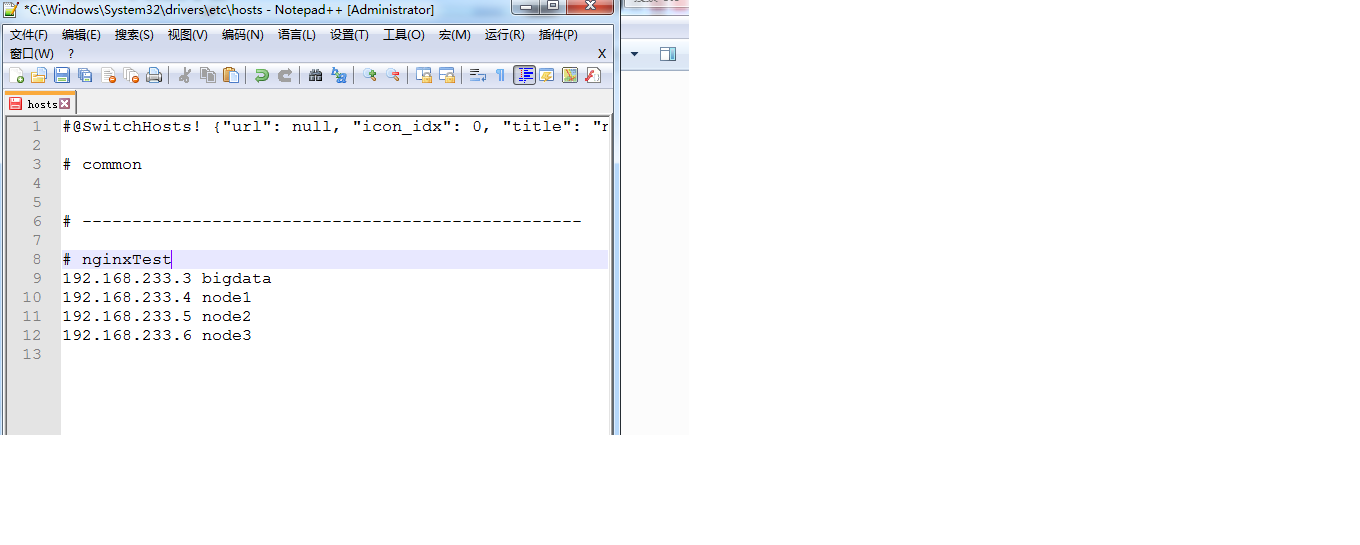
(12)在windows下面进行域名解析:找到C:WindowsSystem32driversetchosts文件,加入如下的内容,就可以在浏览器进行访问了
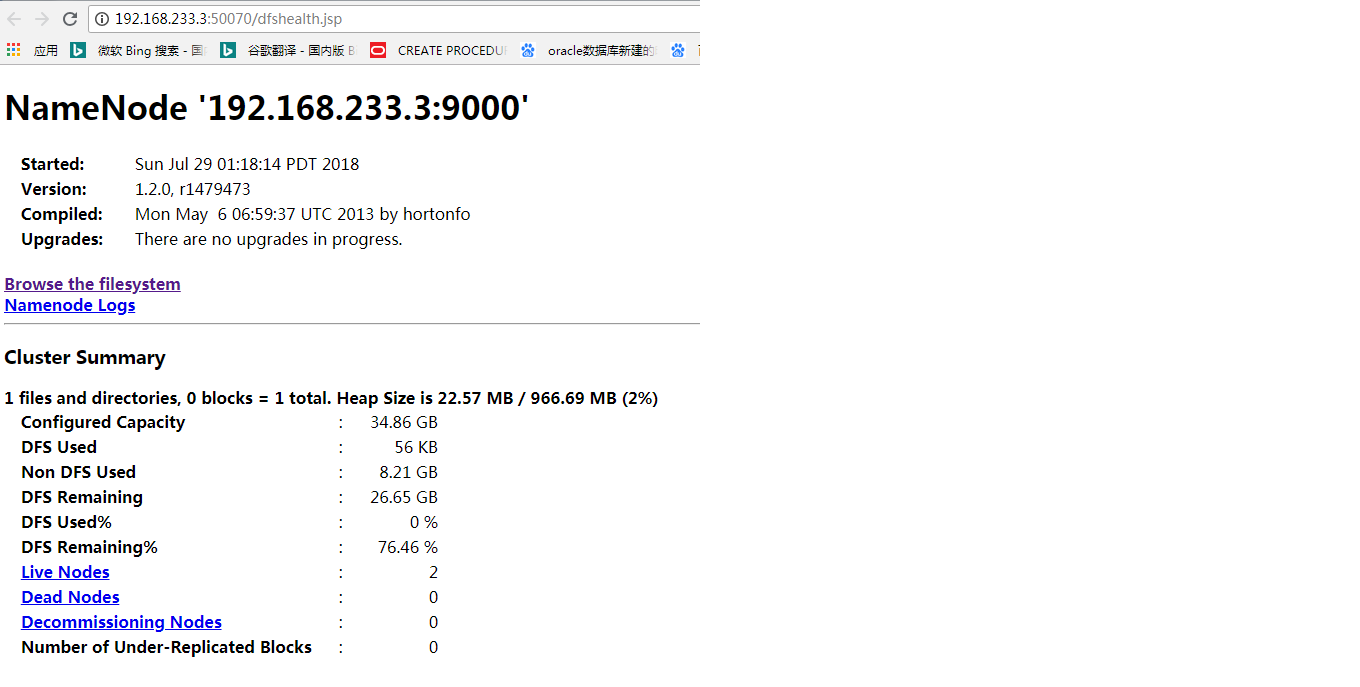
(13)在浏览器访问的地址为:(不知道为什么上面的域名解析没有生效,所以下面我直接用的IP地址访问的)
http://192.168.233.3:50070/dfshealth.jsp
初次写博客,写的不好,写的不详细,请见谅!