1、定义
(1)、串
串(String)是零个或多个字符组成的有限序列。一般记为:
S="a1a2……an"
其中:
a、S是串名;
b、双引号括起的字符序列是串值;
c、ai(1≤i≤n)可以是字母、数字或其它字符;
d、串中所包含的字符个数称为该串的长度。
注意:
将串值括起来的双引号本身不属于串,它的作用是避免串与常数或与标识符混淆。
【例】"123"是数字字符串,它不同于整常数123
【例】"xl"是长度为2的字符串,而xl通常表示一个标识符。
(2)、空串和空白串
长度为零的串称为空串(Empty String),它不包含任何字符。
仅由一个或多个空格组成的串称为空白串(Blank String)。
注意:
空串和空白串的不同。
【例】″ ″和″″分别表示长度为1的空白串和长度为0的空串。
(3)、子串和主串
串中任意个连续字符组成的子序列称为该串的子串。包含子串的串相应地称为主串。
通常将子串在主串中首次出现时,该子串首字符对应的主串中的序号定义为子串在主串中的序号(或位置)。
【例】设A和B分别为
A="This is a string"
B="is"
则B是A的子串,B在A中出现了两次。其中首次出现对应的主串位置是3。因此称B在A中的序号(或位置)是3。
注意:
a、空串是任意串的子串;
b、任意串是其自身的子串。
(4)、串变量和串常量
通常在程序中使用的串可分为:串变量和串常量。
a、串变量
串变量和其它类型的变量一样,其取值是可以改变的。
b、串常量
串常量和整常数、实常数一样,在程序中只能被引用但不能改变其值。即只能读不能写。
① 串常量由直接量来表示的:
【例】Error("overflow")中"overflow"是直接量。
② 串常量命名
有的语言允许对串常量命名,以使程序易读、易写。
【例】C++中,可定义串常量path
const char path[]="dir/bin/appl";
2、基本运算
对于串的基本运算,很多高级语言均提供了相应的运算符或标准的库函数来实现。
为叙述方便,先定义几个相关的变量:
char s1[20]="dir/bin/appl",s2[20]="file.asm",s3[30],*p; int result;
下面以C语言中串运算介绍串的基本运算 :
(1)、求串长
int strlen(char *s);//求串s的长度
【例】
printf("%d",strlen(s1)); //输出s1的串长12
(2)、串复制
char *strcpy(char *to,*from);//将from串复制到to串中,并返回to开始处指针
//注意:这里是把第二个参数复制给第一个参数,不要误以为第一个参数赋值给第二个参数
【例】
strcpy(s3,s1); //s3="dir/bin/appl",s1串不变
char *strcat(char *to,char *from);//将from串复制到to串的末尾,并返回to串开始处的指针
【例】
strcat(s3,"/"); //s3="dir/bin/appl/" strcat(s3,s2); //s3="dir/bin/appl/file.asm"
(4)、串比较
int strcmp(char *s1,char *s2);//比较s1和s2的大小,当s1<s2、s1>s2和s1=s2时,分别返回小于0、大于0和等于0的值
【例】
result=strcmp("baker","Baker"); //result>0
result=strcmp("12","12"); //result=0
result=strcmp("Joe","joseph") //result<0
(5)、字符定位
char *strchr(char *s,char c);//找c在字符串s中第一次出现的位置,若找到,则返回该位置,否则返回NULL
【例】
p=strchr(s2,'.'); //p指向"file"之后的位置 if(p) strcpy(p,".cpp"); //s2="file.cpp"
注意:
① 上述操作是最基本的,其中后 4个操作还有变种形式:strncpy,strncath和strnchr。
② 其它的串操作见C的<string.h>。在不同的高级语言中,对串运算的种类及符号都不尽相同
③ 其余的串操作一般可由这些基本操作组合而成
【例】求子串的操作可如下实现:
void substr(char *sub,char *s,int pos,int len){
//s和sub是字符数组,用sub返回串s的第pos个字符起长度为len的子串
//其中0<=pos<=strlen(s)-1,且数组sub至少可容纳len+1个字符。
if (pos<0||pos>strlen(s)-1||len<0)
Error("parameter error!");
strncpy(sub,&s[pos],len);//从s[pos]起复制至多len个字符到sub
}//substr
拓展:字符串的增删改查
(1)、插入字符串
insert() 函数可以在 string 字符串中指定的位置插入另一个字符串,它的一种原型为:
string& insert (size_t pos, const string& str);
pos表示要插入的位置,也就是下标;str 表示要插入的字符串,它可以是 string 变量,也可以是C风格的字符串。
请看下面的代码:
#include <iostream>
#include <string>
using namespace std;
int main(){
string s1, s2, s3;
s1 = s2 = "1234567890";
s3 = "aaa";
s1.insert(5, s3);
cout<< s1 <<endl;
s2.insert(5, "bbb");
cout<< s2 <<endl;
return 0;
}
运行结果:
12345aaa67890 12345bbb67890
insert() 函数的第一个参数有越界的可能,如果越界,则会产生运行时异常,应该知道如何捕获这个异常。
更多 insert() 函数的原型和用法请参考:http://www.cplusplus.com/reference/string/string/insert/
(2)、删除字符串
erase() 函数可以删除 string 变量中的一个子字符串。它的一种原型为:
string& erase (size_t pos = 0, size_t len = npos);
pos 表示要删除的子字符串的起始下标,len 表示要删除子字符串的长度。如果不指明 len 的话,那么直接删除从 pos 到字符串结束处的所有字符(此时 len = str.length - pos)。
请看下面的代码:
#include <iostream>
#include <string>
using namespace std;
int main(){
string s1, s2, s3;
s1 = s2 = s3 = "1234567890";
s2.erase(5);
s3.erase(5, 3);
cout<< s1 <<endl;
cout<< s2 <<endl;
cout<< s3 <<endl;
return 0;
}
运行结果:
1234567890 12345 1234590
有读者担心,在 pos 参数没有越界的情况下, len 参数也可能会导致要删除的子字符串越界。但实际上这种情况不会发生,erase() 函数会从以下两个值中取出最小的一个作为待删除子字符串的长度:
len 的值; 字符串长度减去 pos 的值。
说得简单一些,待删除字符串最多只能删除到字符串结尾。
(3)、提取子字符串
substr() 函数用于从 string 字符串中提取子字符串,它的原型为:
string substr (size_t pos = 0, size_t len = npos) const;
pos 为要提取的子字符串的起始下标,len 为要提取的子字符串的长度。
请看下面的代码:
#include <iostream>
#include <string>
using namespace std;
int main(){
string s1 = "first second third";
string s2;
s2 = s1.substr(6, 6);
cout<< s1 <<endl;
cout<< s2 <<endl;
return 0;
}
运行结果:
first second third second
系统对 substr() 参数的处理和 erase() 类似:
如果 pos 越界,会抛出异常; 如果 len 越界,会提取从 pos 到字符串结尾处的所有字符。
(4)、字符串查找
string 类提供了几个与字符串查找有关的函数,如下所示。
a、find() 函数
find() 函数用于在 string 字符串中查找子字符串出现的位置,它其中的两种原型为:
size_t find (const string& str, size_t pos = 0) const; size_t find (const char* s, size_t pos = 0) const;
第一个参数为待查找的子字符串,它可以是 string 变量,也可以是C风格的字符串。第二个参数为开始查找的位置(下标);如果不指明,则从第0个字符开始查找。
请看下面的代码:
#include <iostream>
#include <string>
using namespace std;
int main(){
string s1 = "first second third";
string s2 = "second";
int index = s1.find(s2,5);
if(index < s1.length())
cout<<"Found at index : "<< index <<endl;
else
cout<<"Not found"<<endl;
return 0;
}
运行结果:
Found at index : 6
find() 函数最终返回的是子字符串第一次出现在字符串中的起始下标。本例最终是在下标6处找到了 s2 字符串。如果没有查找到子字符串,那么会返回一个无穷大值 4294967295。
b、rfind() 函数
rfind() 和 find() 很类似,同样是在字符串中查找子字符串,不同的是 find() 函数从第二个参数开始往后查找,而 rfind() 函数则最多查找到第二个参数处,如果到了第二个参数所指定的下标还没有找到子字符串,则返回一个无穷大值4294967295。
请看下面的例子:
#include <iostream>
#include <string>
using namespace std;
int main(){
string s1 = "first second third";
string s2 = "second";
int index = s1.rfind(s2,6);
if(index < s1.length())
cout<<"Found at index : "<< index <<endl;
else
cout<<"Not found"<<endl;
return 0;
}
运行结果:
Found at index : 6
c、find_first_of() 函数
find_first_of() 函数用于查找子字符串和字符串共同具有的字符在字符串中首次出现的位置。请看下面的代码:
#include <iostream>
#include <string>
using namespace std;
int main(){
string s1 = "first second second third";
string s2 = "asecond";
int index = s1.find_first_of(s2);
if(index < s1.length())
cout<<"Found at index : "<< index <<endl;
else
cout<<"Not found"<<endl;
return 0;
}
运行结果:
Found at index : 3
本例中 s1 和 s2 共同具有的字符是 's',该字符在 s1 中首次出现的下标是3,故查找结果返回3。
3、顺序存储结构
(1) 、顺序串
串的顺序存储结构简称为顺序串。
与顺序表类似,顺序串是用一组地址连续的存储单元来存储串中的字符序列。因此可用高级语言的字符数组来实现,按其存储分配的不同可将顺序串分为如下两类:
a、静态存储分配的顺序串
b、动态存储分配的顺序串
(2)、静态存储分配的顺序串
a、直接使用定长的字符数组来定义
该种方法顺序串的具体描述:
#define MaxStrSize 256 //该值依赖于应用,由用户定义
typedef char SeqString[MaxStrSize]; //SeqString是顺序串类型
SeqString S; //S是一个可容纳255个字符的顺序串
注意:
① 串值空间的大小在编译时刻就已确定,是静态的。难以适应插入、链接等操作
② 直接使用定长的字符数组存放串内容外,一般可使用一个不会出现在串中的特殊字符放在串值的末尾来表示串的结束。所以串空间最大值为MaxStrSize时,最多只能放MaxStrSize-1个字符。
【例】C语言中以字符'�'表示串值的终结。
b、类似顺序表的定义
直接使用定长的字符数组存放串内容外,可用一个整数来表示串的长度。此时顺序串的类型定义完全和顺序表类似:
typedef struct{
char ch[MaxStrSize]; //可容纳256个字符,并依次存储在ch[0..n]中
int length;
}SeqString;
SeqString s;
注意:
① 串的长度减1的位置就是串值的最后一个字符的位置;
② 这种表示的优点是涉及串长的操作速度快。
(3)、动态存储分配的顺序串
顺序串的字符数组空间可使用C语言的malloc和free等动态存储管理函数,来根据实际需要动态地分配和释放。
这样定义的顺序串类型亦有两种形式。
a、较简单的定义
typedef char *string; //C中的串库<string.h>相当于使用此类型定义串
b、复杂定义
typedef struct{
char *ch;//若串非空,则按实际的串长分配存储区,否则ch为NULL,这里的ch是char类型的指针,只是一个首地址
int length;
}HString;
HString *s;
4、链式存储结构
(1)、链串
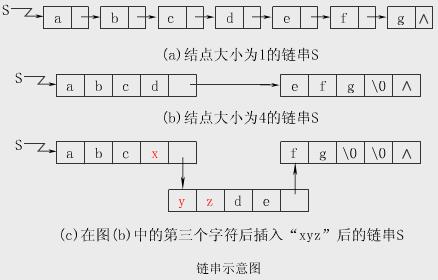
用单链表方式存储串值,串的这种链式存储结构简称为链串。
(2)、链串的结构类型定义
typedef struct node{
char data;
struct node *next;
}LinkStrNode; //结点类型
typedef LinkStrNode *LinkString; //LinkString为链串类型
LinkString S; //S是链串的头指针(只定义了一个LinkString类型的存储结构还不够,必须给出头指针,这样才会知道起始的位置)
注意:
① 链串和单链表的差异仅在于其结点数据域为单个字符:
② 一个链串由头指针唯一确定。
(3)、链串的结点大小
通常,将结点数据域存放的字符个数定义为结点的大小。结点的大小的值越大,存储密度越高。
a、结点大小为1的链串
【例】串值为"abcdef"的结点大小为1的链串S如下图所示。

这种结构便于进行插入和删除运算,但存储空间利用率太低。
b、结点大小>1的链串
【例】串值为"abcdef"的结点大小为4的链串S如下图所示。

注意:
① 为了提高存储密度,可使每个结点存放多个字符。
② 当结点大小大于1时,串的长度不一定正好是结点大小的整数倍,因此要用特殊字符来填充最后一个结点,以表示串的终结。
③ 虽然提高结点的大小使得存储密度增大,但是做插入、删除运算时,可能会引起大量字符的移动,给运算带来不便。
【例】上图中,在S的第3个字符后插入“xyz”时,要移动原来S中后面4个字符的位置,结果见下图。

5、串运算的实现
串是特殊的线性表,故顺序串和链串上实现的运算分别与顺序表和单链表上进行的操作类似。
C语言的串库<string.h>里提供了丰富的串函数来实现各种基本运算,因此我们对各种串运算的实现不作讨论。
(1)、子串定位
子串定位运算类似于串的基本运算中的字符定位运算。只不过是找子串而不是找字符在主串中首次出现的位置。此运算的应用非常广泛。
【例】在文本编辑中,我们经常要查找某一特定单词在文本中出现的位置。解此问题的有效算法能极大地提高文本编辑程序的响应性能。
子串定位运算又称串的模式匹配或串匹配。
(2)、目标(串)和模式(串)
在串匹配中,一般将主串称为目标(串),子串称为模式(串)。
假设T 为目标串,P为模式串,且不妨设:
T="t0t1t2…tn-1"
P="p0p1p2…pm-1"(0<m≤n)
(3)、串匹配
串匹配就是对于合法的位置(又称合法的位移)0≤i≤n-m,依次将目标串中的子串"titi+1…ti+m-1"和模式串"p0p1p2…pm-1"进行比较:
①若"titi+1…ti+m-1"="p0p1p2…pm-1",则称从位置i开始的匹配成功,或称i为有效位移。 ②若"titi+1…ti+m-1"≠"p0p1p2…pm-1",则称从位置i开始的匹配失败,或称i为无效位移。
因此,串匹配问题可简化为找出某给定模式串P在给定目标串T中首次出现的有效位移。
注意:
有些应用中要求求出P在T中所有出现的有效位移。
(4)、顺序串上的子串定位运算
a、朴素的串匹配算法的基本思想
即用一个循环来依次检查n-m+1个合法的位移i(0≤i≤n-m)是否为有效位移。
b、顺序串上的串匹配算法
以下以第二种定长的顺序串类型作为存储结构。给出串匹配的算法:
#define MaxStrSize 256 //该值依赖于应用,由用户定义
typedef struct{
char ch[MaxStrSize]; //可容纳256个字符,并依次存储在ch[0..n]中
int length;
}SeqString;
int Naive StrMatch(SeqString T,SeqString P)
{//找模式P在目标T中首次出现的位置,成功返回第1个有效位移,否则返回-1
int i,j,k;
int m=P.length; //模式串长度
int n=T.length; //目标串长度
for(i=0;i<=n-m;i++){ //0<=i<=n-m是合法的位移
j=0;k=i; //下面用while循环判定i是否为有效位移
while(j<m&&T.ch[k]==P.ch[j]{
k++;j++;
}
if(j==m) //既T[i..i+m-1]=P[0..m-1]
return i; //i为有效位移,否则查找下一个位移
}//endfor
return -1; //找不到有效位移,匹配失败
}//NaiveStrMatch
c、算法分析
① 最坏时间复杂度
该算法最坏情况下的时间复杂度为O((n-m+1)m)。
分析:当目标串和模式串分别是"an-1b"和"am-1b"时,对所有n-m+1个合法的位移,均要比较m个字符才能确定该位移是否为有效位移,因此所需比较字符的总次数为(n-m+1)m。
② 模式匹配算法的改进
朴素的串匹配算法虽然简单,但效率低。其原因是在检查位移i是否为有效位移时,没有利用检查位移i-1,i,…,0时的部分匹配结果。
若利用部分匹配结果,模式串右滑动的距离就不会是每次一位,而是每次使其向右滑动得尽可能远。这样可使串匹配算法的最坏时间控制在O(m+n)数量级上。
(5)、链串上的子串定位运算
用结点大小为1的单链表做串的存储结构时,实现朴素的串匹配算法很简单。只是现在的位移shift是结点地址而非整数,且单链表中没有存储长度信息。若匹配成功,则返回有效位移所指的结点地址,否则返回指针。具体算法如下:
LinkStrNode *LinkStrMatch(LinkString T,LinkString P)
{
//在链串上求模式P在目标T首次出现的位置
LinkStrNode * shift,*t,*p;
shift=T; //shift表示位移
t=shift;p=P;
while(t&&p)
{
if(t->data==p->data)
{ //继续比较后续结点中字符
t=t->next;
p=p->next;
}
else
{ //已确定shift为无效位移
shift=shift->next; //模式右移,继续判定shift是否为有效位移
t=shift;
p=P;
}
}//endwhile
if(p==NULL)
return shift; //匹配成功
else
return NULL; //匹配失败
}
该算法的时间复杂度与顺序表上朴素的串匹配算法相同。