一、re
1、重复匹配
(1).:匹配换行符以外的任意一个字符 # print(re.findall('a.c','abc a1c aac asd aaaaac a*c a+c abasd')) #['abc','a1c','aac','aac','a*c','a+c'] # a.c # print(re.findall('a.c','abc a1c aac a c asd aaaaac a*c a+c abasd',re.DOTALL))

(2)[]:匹配一个字符,该字符属于中括号内指定的字符
# print(re.findall('a..c','abc a1 c aac asd aaaaac a *c a+c abasd ='))
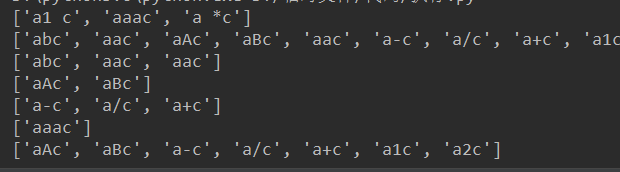
# print(re.findall('a.c','abc a1 c aac aAc aBc asd aaaaac a-c a/c a *c a+c abasd = a1c a2c'))
# print(re.findall('a[a-z]c','abc a1 c aac aAc aBc asd aaaaac a-c a/c a *c a+c abasd = a1c a2c'))
# print(re.findall('a[A-Z]c','abc a1 c aac aAc aBc asd aaaaac a-c a/c a *c a+c abasd = a1c a2c'))
# print(re.findall('a[-+*/]c','abc a1 c aac aAc aBc asd aaaaac a-c a/c a *c a+c abasd = a1c a2c'))
# print(re.findall('a[a-z][a-z]c','abc a1 c aac aAc aBc asd aaaaac a-c a/c a *c a+c abasd = a1c a2c'))
# print(re.findall('a[^a-z]c','abc a1 c aac aAc aBc asd aaaaac a-c a/c a *c a+c abasd = a1c a2c'))
(3)# *: 必须与其他字符连用,代表左侧最近的第一个字符出现0次或者无穷次
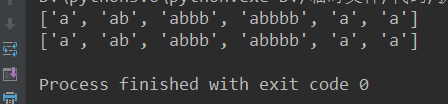
# print(re.findall('ab*','a ab abbb abbbb a1bbbb a-123'))
# ab*
#['a','ab','abbb','abbbb','a','a']
# print(re.findall('ab{0,}','a ab abbb abbbb a1bbbb a-123'))
(4)# ?: 必须与其他字符连用,代表左侧最近的第一个的字符出现0次或者1次
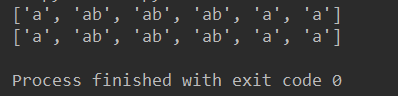
# print(re.findall('ab?','a ab abbb abbbb a1bbbb a-123'))
# ab?
#['a','ab','ab','ab','a','a']
# print(re.findall('ab{0,1}','a ab abbb abbbb a1bbbb a-123'))
(5)# +: 必须与其他字符连用,代表左侧的字符出现1次或者无穷次
# print(re.findall('ab+','a ab abbb abbbb a1bbbb a-123'))
# ab+
# ['ab','abbb','abbbb']
# print(re.findall('ab{1,}','a ab abbb abbbb a1bbbb a-123'))

(6)# {n,m}: 必须与其他字符连用
# print(re.findall('ab{1,3}','a ab abbb abbbb a1bbbb a-123'))
# ab{1,3}
# ['ab','abbb','abbb']
2、
(1).*:贪婪匹配
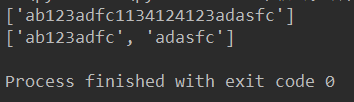
# print(re.findall('a.*c','ab123adfc1134124123adasfc123123'))
(2) .*?:非贪婪匹配
# print(re.findall('a.*?c','ab123adfc1134124123adasfc123123')
(3)():分组 不影响匹配,但只会取()内的内容,如果都要取(?: )
# print(re.findall('expression="(.*?)"','expression="1+2+3/4*5" egon="beautiful"'))
# expression=".*?"
# print(re.findall('href="(.*?)"','<p>段落</p><a href="https://www.sb.com">点我啊
(4)|竖杠 表示左边或者右边
print(re.findall('a|b','ab123abasdfaf')) # a|b #取companies 或 company # print(re.findall('compan(?:ies|y)','Too many companies have gone bankrupt, and the next one is my company'))
PS:
正则表达式匹配反斜杠"",为什么是"\\"或是 r"\"呢?
因为在正则表达式中为特殊符号,为了取消它在正则表达式中的特殊意义需要加一个就变成了\,但是问题又来了,也是字符串中的特殊字符,所以又要分别对两个取消其特殊意义,即为\\。Python中有一个原始字符串操作符,用于那些字符串中出现特殊字符,在原始字符串中,没有转义字符和不能打印的字符。这样就可以取消了在字符串中的转义功能,即r"\"。
3.re、search()从左到右匹配,找到一个就结束
print(re.findall('ale(x)','alex is SB,alex is bigSB')) print(re.search('alex','alex is SB,alex is bigSB')) print(re.search('ale(x)','alex is SB,alex is bigSB').group()) print(re.search('abcdefg','alex is SB,alex is bigSB'))
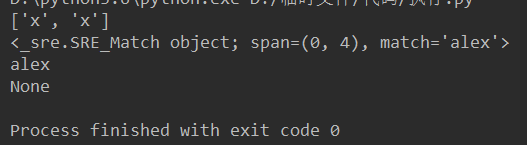
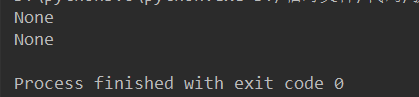
4、re.match() 只能从头开始匹配,第一个不是就返回None
print(re.search('^alex','123alex is SB,alex is bigSB')) # print(re.match('alex','123alex is SB,alex is bigSB'))
5、re.split()切割
# l='egon:18:male'.split(':') # print(l) # l1=re.split('[ :/-]','a-b/c egon:18:male xxx') # print(l1)

6、re.sub()替代
re.sub(‘原‘,‘新’,‘内容’,次数)次数可不写,默认全部替换
print(re.sub('[a-z]+xx','yxp','lxx is good,sb is lllxx wxx is good cxx is good')

7、re.compile()预存一个正则表达式可以重复使用
# pattern=re.compile('alex') # print(pattern.findall('alex is SB,alex is bigSB')) # print(pattern.search('alex is SB,alex is bigSB'))
二、subprocess
1、定义:子进程模块
一个正在运行的程序称之为进程,一个进程 开启了另一个进程 这个被开启的进程叫做子进程
2、使用
import subprocess obj=subprocess.Popen('tasklist',shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE) 创建一个子进程,通过管道将原进程和子进程联系 stdout_res=obj.stdout.read() print(stdout_res.decode('gbk')) 终端默认是gbk,所以要用gbk解码 stderr_res=obj.stderr.read() print(stderr_res.decode('gbk'))