系列译文: http://ifeve.com/disruptor/
当有多个消费者时,(按Disruptor的设计)每个消费者各自控制自己的指针,依次读取每个Slot(也就是每个消费者都会读取到所有的产品),这时只需要保证生产者指针不会超过最慢的消费者(超过最后一个消费者“一圈”)即可,也不需要锁。
重复消费http://blog.csdn.net/zero__007/article/details/49684363
Disruptor多个消费者不重复处理生产者发送的消息的demo
Disruptor多个消费者独立处理生产者消息的简单demo
http://abc08010051.iteye.com/blog/2246976
http://www.360doc.com/content/15/0330/20/11962419_459384128.shtml
- EventProcessor
EventProcessor 持有特定消费者(Consumer)的 Sequence,并提供用于调用事件处理实现的事件循环(Event Loop)。 - EventHandler
Disruptor 定义的事件处理接口,由用户实现,用于处理事件,是 Consumer 的真正实现。
Disruptor 极速体验
https://www.cnblogs.com/haiq/p/4112689.html
并发框架Disruptor浅析
1、引言
Disruptor是一个开源的Java框架,它被设计用于在生产者—消费者(producer-consumer problem,简称PCP)问题上获得尽量高的吞吐量(TPS)和尽量低的延迟。Disruptor是LMAX在线交易平台的关键组成部分,LMAX平台使用该框架对订单处理速度能达到600万TPS,除金融领域之外,其他一般的应用中都可以用到Disruptor,它可以带来显著的性能提升。其实Disruptor与其说是一个框架,不如说是一种设计思路,这个设计思路对于存在“并发、缓冲区、生产者—消费者模型、事务处理”这些元素的程序来说,Disruptor提出了一种大幅提升性能(TPS)的方案。
现在有很多人写过关于Disruptor文章,但是我还是想写这篇浅析,毕竟不同人的理解是不同的,希望没接触过它的人能通过本文对Disruptor有个初步的了解,本文后面给出了一些相关链接供参考。
2、什么是Disruptor?为什么速度更快?
简单的说,Disruptor是一个高性能的Buffer,并提供了使用这个Buffer的框架。为什么说是它性能更好呢?这得从PCP和传统解决办法的缺点开始说起。
我们知道,PCP又称Bounded-Buffer问题,其核心就是保证对一个Buffer的存取操作在多线程环境下不会出错。使用Java中的ArrayBlockingQueue和LinkedBlockingQueue类能轻松的完成PCP模型,这对于一般程序已经没问题了,但是对于并发度高、TPS要求较大的系统则不然。(kafka通过 底层,和 增加 partition(分区)实现)
*BlockingQueue使用的是package java.util.concurrent.locks中实现的锁,当多个线程(例如生产者)同时写入Queue时,锁的争抢会导致只有一个生产者可以执行,其他线程都中断了,也就是线程的状态从RUNNING切换到BLOCKED,直到某个生产者线程使用完Buffer后释放锁,其他线程状态才从BLOCKED切换到RUNNABLE,然后时间片到其他线程后再进行锁的争抢。上述过程中,一般来说生产者存放一个数据到Buffer中所需时间是非常短的,操作系统切换线程上下文的速度也是非常快的,但是当线程数量增多后,OS切换线程所带来的开销逐渐增多,锁的反复申请和释放成为性能瓶颈。*BlockingQueue除了使用锁带来的性能损失外,还可能因为线程争抢的顺序问题造成性能再次损失:实际使用中发现线程的调度顺序并不理想,可能出现短时间内OS频繁调度出生产者或消费者的情况,这样造成缓冲区可能短时间内被填满或被清空的极端情况。(理想情况应该是缓冲区长度适中,生产和消费速度基本一致)
对于上面的问题Disruptor的解决方案是:不用锁。

Disruptor使用一个Ring Buffer存放生产者的“产品”,环形缓冲区实际上还是一段连续内存,之所以称作环形是因为它对数据存放位置的处理,生产者和消费者各有一个指针(数组下标),消费者的指针指向下一个要读取的Slot,生产者指针指向下一个要放入的Slot,消费或生产后,各自的指针值p = (p +1) % n,n是缓冲区长度,这样指针在缓冲区上反复游走,故可以将缓冲区看成环状。(如右图)(Ring Buffer并非Disruptor原创,Linux内核中就有环形缓冲区的实现。)使用Ring Buffer时:
①当生产者和消费者都只有一个时,由于两个线程分别操作不同的指针,所以不需要锁。
②当有多个消费者时,(按Disruptor的设计)每个消费者各自控制自己的指针,依次读取每个Slot(也就是每个消费者都会读取到所有的产品),这时只需要保证生产者指针不会超过最慢的消费者(超过最后一个消费者“一圈”)即可,也不需要锁。
③当有多个生产者时,多个线程共用一个写指针,此处需要考虑多线程问题,例如两个生产者线程同时写数据,当前写指针=0,运行后其中一个线程应获得缓冲区0号Slot,另一个应该获得1号,写指针=2。对于这种情况,Disruptor使用CAS来保证多线程安全。
CAS(Compare and Swap/Set)是现在CPU普遍支持的一种指令(例如cmpxchg系类指令),CAS操作包含3个操作数:CAS(A,B,C),其功能是:取地址A的值与B比较,如果相同,则将C赋值到地址A。CAS特点是它是由硬件实现的极轻量级指令,同时CPU也保证此操作的原子性。在考虑线程间同步问题时,可以使用Unsafe类的boolean compareAndSwapInt(java.lang.Object arg0, long arg1, int arg2, int arg3);系列方法,对于一个int变量(例如,Ring Buffer的写指针),使用CAS可以避免多线程访问带来的混乱,当compareAndSwap方法true时表明CAS操作成功赋值,返回false则表明地址A处的值并不等于B,此时重新试一遍即可,使用CAS移动写指针的逻辑如下:

1 //写指针向后移动n
2 public long next(int n)
3 {
4 //......
5 long current,next;
6 do
7 {
8 //此处先将写指针的当前值备份一下
9 current = pointer.get();
10 //预计写指针将要移动到的位置
11 next = current + n;
12 //......省略:确保从current到current+n的Slot已经被消费者读完......
13 //*原子操作*如果当前写指针和刚才一样(说明9-12行的计算有效),那么移动写指针
14 if ( pointer.comapreAndSet(current,next) )
15 break;
16 }while ( true )//如果CAS失败或者还不能移动写指针,则不断尝试
17 return next;
18 }
OK,我们现在有了一个使用CAS的Ring Buffer,这比用锁快上不少,但CAS的效率并没有想象的那么快,根据链接[2]pdf中评测:和单一线程无锁执行某简单任务相比,使用锁的时间比无锁高出2个数量级,CAS也高出了一个数量级。那么Disruptor还有什么提高性能的地方呢?下面列举一下除了无锁编程外的其他性能优化点。
①缓存行填充(Cache Line Padding):CPU缓存常以64bytes作为一个缓存行大小,缓存由若干个缓存行组成,缓存写回主存或主存写入缓存均是以行为单位,此外每个CPU核心都有自己的缓存(但是若某个核心对某缓存行做出修改,其他拥有同样缓存的核心需要进行同步),生产者和消费者的指针用long型表示,假设现在只有一个生产者和一个消费者,那么双方的指针间没有什么直接联系,只要不“挨着”,应该可以各改各的指针。OK前面说有点乱,下面问题来了:如果生产者和消费者的指针(加起来共16bytes)出现在同一个缓存行中会怎么样?例如CPU核心A运行的消费者修改了一下自己的指针值(P1),那么其他核心中所有缓存了P1的缓存行都将失效,并从主存重新调配。这样做的缺点显而易见,但是CPU和编译器并未聪明到避免这个问题,所以需要缓存行填充。虽然问题产生的原因很绕,但是解决方案却非常简单:对于一个long型的缓冲区指针,用一个长度为8的long型数组代替。如此一来,一个缓存行被这个数组填充满,线程对各自指针的修改不会干扰到他人。
②避免GC:写Java程序的时候,很多人习惯随手new各种对象,虽然Java的GC会负责回收,但是系统在高压力情况下频繁的new必定导致更频繁的GC,Disruptor避免这个问题的策略是:提前分配。在创建RingBuffer实例时,参数中要求给出缓冲区元素类型的Factory,创建实例时,Ring Buffer会首先将整个缓冲区填满为Factory所产生的实例,后面生产者生产时,不再用传统做法(顺手new一个实例出来然后add到buffer中),而是获得之前已经new好的实例,然后设置其中的值。举个形象的例子就是,若缓冲区是个放很多纸片的地方,纸片上记录着信息,以前的做法是:每次加入缓冲区时,都从系统那现准备一张纸片,然后再写好纸片放进缓冲区,消费完就随手扔掉。现在的做法是:实现准备好所有的纸片,想放入时只需要擦掉原来的信息写上新的即可。
③成批操作(Batch):Ring Buffer的核心操作是生产和消费,如果能减少这两个操作的次数,性能必然相应地提高。Disruptor中使用成批操作来减少生产和消费的次数,下面具体说一下Disruptor的生产和消费过程中如何体现Batch的。向RingBuffer生产东西的时候,需要经过2个阶段:阶段一为申请空间,申请后生产者获得了一个指针范围[low,high],然后再对缓冲区中[low,high]这段的所有对象进行setValue(见优化点②),阶段2为发布(像这样ringBuffer.publish(low,high);)。阶段1结束后,其他生产者再申请的话,会得到另一段缓冲区。阶段2结束后,之前申请的这一段数据就可以被消费者读到。Disruptor推荐成批生产、成批发布,减少生产时的同步带来的性能损失。从RingBuffer消费东西的时候也需要两个阶段,阶段一为等待生产者的(写)指针值超过指定值(N,即N之前的数据已经生产过了),阶段一执行完后,消费者会得到一个指针值(R),表示Ring Buffer中下标R之前的值是可以读的。阶段2就是具体读取(略)。阶段一返回值R很有可能大于N,此时消费者应该进行成批读取操作,将[R,N]范围内的数据全部处理。
④LMAX架构:(注:指的是LMAX公司在做他们的交易平台时使用的一些设计思想的集合,严格讲是LMAX架构包含Disruptor,并非其中的一部分,但是Disruptor的设计中或多或少体现了这些思想,所以在这还是要提一下,关于LMAX架构应该可以写很多,但限于个人水平,在这只能简单说说。另外,这个架构是以及极端追求性能的产物,不一定适合大众。)如下图所示LMAX架构分为三个部分,输入/输出Disruptor,和中间核心的业务逻辑处理器。所有的信息输入进入Input Disruptor,被业务逻辑处理器读取后送入Output Disruptor,最后输出到其他地方。
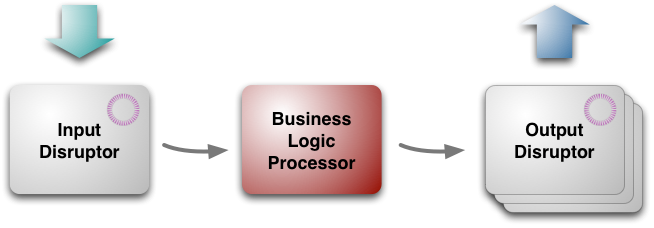
对于一般由表现层+业务层+持久层组成的Web系统,LMAX架构指的是业务层,它有如下几个特点:
a)业务逻辑处理器(简称BLP)完全的In-Memory:如上图,业务逻辑处理器是处理所有业务逻辑的地方,Input Disruptor把输入(例如订单数据、用户操作)以消息的形式(称作Message或者Event都可以)发到BLP,BLP进行响应。一般系统中我们可能会多线程执行一些业务逻辑代码,然后这些代码最终生成一些SQL语句,然后这些语句再去查数据库,数据库可能在其他主机,数据库查询结果可能直接用了内存中的缓存,最坏情况是数据库从磁盘中读取了想要的数据,最后再返回给业务逻辑代码。这个过程有很多的时间浪费:首先,多线程访问持久层会涉及到同步问题(锁,有是这货)。其次,生成*QL语句、查询数据库的耗时也是非常大的。最后,最坏情况下还要进行一大串磁盘IO和内存IO才能取到数据。LMAX对此的解决方案是:把能用到的所有数据全部装入内存,只有到极少数或周期性需要同步、持久化的时候再访问数据库。(这听起来有点疯狂,但是仔细想想这些业务真的需要那么大空间吗?)这么做的好处也是显而易见,减少了网络、磁盘的IO后In-Memory系统上的大部分业务逻辑全都变成一些加减乘除运算了。
b)异步-事件驱动:经过a)的修改,如果还存在一些业务逻辑处理过程是需要长时间才能完成的,那么就把它作为一个事件,再抛给其他组件(可能还是Disruptor)等待。业务逻辑处理器需要时刻保持最快速度、最高效率,它不能等待任何事情。
c)每个业务逻辑处理器是单线程的:你没有听错。其实有了a)b)作为前提,会发现多线程所带来的业务层面同步问题将会极大限制BLP效率、增大BLP的复杂度,和BLP的设计(Keep it simple, stupid.)相悖,如果实在想多线程,可以参照d)。
d)使用多级业务逻辑处理器:有些像管道模式,上图的3块结构可以以多种方式组合,一个BLP可以将输出送往多个Output Disruptor,而这些Disruptor可能是另一些3块结构的Input Disruptor,即有些BLP是起到分发作用的,另一些是进行具体业务逻辑计算的。每个BLP对应一个线程,整个架构可能比上图复杂很多。
3、Hello Disruptor
Disruptor最初是由Java实现的,现在也有C/Cpp和.Net版本,Java版最全更新最快,代码注释较多比较好懂。说了这么多,本节先给出一个测试例子,展示Disruptor的基本用法,例子中用LinkedBlockingQueue和Disruptor分别实现了单一生产者+单一消费者存取简单对象的测试,统计了一下双方消耗的时间,仅供参考。
 测试代码
测试代码//简单对象:缓冲区中的元素,里面只有一个value,提供setValue private class TestObj { public long value; public TestObj(long value) { this.value = value; } public void setValue(long value) { this.value = value; } } public class Test { //待生产的对象个数 final long objCount = 1000000; final long bufSize;//缓冲区大小 { bufSize = getRingBufferSize(objCount); } //获取RingBuffer的缓冲区大小(2的幂次!加速计算) static long getRingBufferSize(long num) { long s = 2; while ( s < num ) { s <<= 1; } return s; } //使用LinkedBlockingQueue测试 public void testBlocingQueue() throws Exception { final LinkedBlockingQueue<TestObj> queue = new LinkedBlockingQueue<TestObj>(); Thread producer = new Thread(new Runnable() {//生产者 @Override public void run() { try{ for ( long i=1;i<=objCount;i++ ) { queue.put(new TestObj(i));//生产 } }catch ( InterruptedException e ){ } } }); Thread consumer = new Thread(new Runnable() {//消费者 @Override public void run() { try{ TestObj readObj = null; for ( long i=1;i<=objCount;i++ ) { readObj = queue.take();//消费 //DoSomethingAbout(readObj); } }catch ( InterruptedException e ){ } } }); long timeStart = System.currentTimeMillis();//统计时间 producer.start(); consumer.start(); consumer.join(); producer.join(); long timeEnd = System.currentTimeMillis(); DecimalFormat df = (DecimalFormat) DecimalFormat.getInstance(); System.out.println((timeEnd - timeStart) + "/" + df.format(objCount) + " = " + df.format(objCount/(timeEnd - timeStart)*1000) ); } //使用RingBuffer测试 public void testRingBuffer() throws Exception { //创建一个单生产者的RingBuffer,EventFactory是填充缓冲区的对象工厂 // YieldingWaitStrategy等"等待策略"指出消费者等待数据变得可用前的策略 final RingBuffer<TestObj> ringBuffer = RingBuffer.createSingleProducer(new EventFactory<TestObj>() { @Override public TestObj newInstance() { return new TestObj(0); } } , (int)bufSize, new YieldingWaitStrategy()); //创建消费者指针 final SequenceBarrier barrier = ringBuffer.newBarrier(); Thread producer = new Thread(new Runnable() {//生产者 @Override public void run() { for ( long i=1;i<=objCount;i++ ) { long index = ringBuffer.next();//申请下一个缓冲区Slot ringBuffer.get(index).setValue(i);//对申请到的Slot赋值 ringBuffer.publish(index);//发布,然后消费者可以读到 } } }); Thread consumer = new Thread(new Runnable() {//消费者 @Override public void run() { TestObj readObj = null; int readCount = 0; long readIndex = Sequencer.INITIAL_CURSOR_VALUE; while ( readCount < objCount )//读取objCount个元素后结束 { try{ long nextIndex = readIndex + 1;//当前读取到的指针+1,即下一个该读的位置 long availableIndex = barrier.waitFor(nextIndex);//等待直到上面的位置可读取 while ( nextIndex <= availableIndex )//从下一个可读位置到目前能读到的位置(Batch!) { readObj = ringBuffer.get(nextIndex);//获得Buffer中的对象 //DoSomethingAbout(readObj); readCount++; nextIndex ++; } readIndex = availableIndex;//刷新当前读取到的位置 }catch ( Exception ex) { ex.printStackTrace(); } } } }); long timeStart = System.currentTimeMillis();//统计时间 producer.start(); consumer.start(); consumer.join(); producer.join(); long timeEnd = System.currentTimeMillis(); DecimalFormat df = (DecimalFormat) DecimalFormat.getInstance(); System.out.println((timeEnd - timeStart) + "/" + df.format(objCount) + " = " + df.format(objCount/(timeEnd - timeStart)*1000) ); } public static void main(String[] args) throws Exception { Test ins = new Test(); //执行测试 ins.testBlocingQueue(); ins.testRingBuffer(); } } 测试代码
测试结果:
319/1,000,000 = 3,134,000 //使用LinkedBlockingQueue在319毫秒内存取100万个简单对象,每秒钟能执行313万个
46/1,000,000 = 21,739,000 //使用Disruptor在46毫秒内存取100万个简单对象,每秒钟能执行2173万个
平均下来使用Disruptor速度能提高7倍。(不同电脑、应用环境下结果可能不一致)
4、随想:Disruptor、完成端口与Mechanical Sympathy
When pushing performance like this, it starts to become important to take account of the way modern hardware is constructed.
“当对性能的追求达到这样的程度,以致对现代硬件构成的理解变得越来越重要。”这句话恰当地形容了Disruptor/LMAX在对性能方面的追求和失败。咦,失败?为什么会这么说呢?Disruptor当然是一个优秀的框架,我说的失败指的是在开发它的过程中,LMAX曽试图提高并发程序效率,优化、使用锁或借助其他模型,但是这些尝试最终失败了——然后他们构建了Disruptor。再提问:一个Java程序员在尝试提高他的程序性能的时候,需要了解很多硬件知识吗?我想很多人都会回答“不需要”,构建Disruptor的过程中,最初开发人员对这个问题的回答可能也是“不需要”,但是尝试失败后他们决定另辟蹊径。总的看下Disruptor的设计:锁到CAS、缓冲行填充、避免GC等,我感觉这些设计都在刻意“迁就”或者“依赖”硬件设计,这些设计更像是一种“(ugly)hack”(毫无疑问,Disruptor还是目前最优秀的方案之一)。
Disruptor我想到了完成端口,完成端口据说能是Windows上最快的并发网络“框架”:你只要通过API告诉Windows你想recv哪些socket,然后各个recv操作在内核层面上执行并加入到某个队列中,最后再使用Worker线程进行处理,大部分工作Windows都为你做好了,不使用锁也没有上下文切换和大量线程,是不是和Disruptor异曲同工呢?完成端口和Disruptor在追求性能时,都避免使用并行、锁、多线程等概念,这些概念的出现自有它们的原因,这里不用多说,但是为了性能(考虑到硬件)却不能充分使用它们,说明在处理并发、并行问题上,硬件和软件的发展存在不协调,可能冯氏计算机还是适合单“线程”顺序处理信息吧。关于这种不协调,我认为应该是硬件应该会逐步适应软件,但也有人提出了有意思的Mechanical Sympathy(链接[6]),至于未来会如何发展就不是这篇blog能讨论的了:) 。
(完)
链接:
[1]Disruptor介绍译文:http://ifeve.com/disruptor/
原文https://code.google.com/p/disruptor/wiki/BlogsAndArticles
[2]Disruptor的GitHub:http://lmax-exchange.github.io/disruptor/
其中http://lmax-exchange.github.io/disruptor/files/Disruptor-1.0.pdf这篇PDF对Disruptor作了很好的阐述。
[3]完成端口:http://blog.csdn.net/piggyxp/article/details/6922277
[4]致敬disruptor:CAS实现高效(伪)无锁阻塞队列实践:http://www.majin163.com/2014/03/24/cas_queue/
[5]Disruptor 源码分析:http://huangyunbin.iteye.com/blog/1944232
[6]Mechanical Sympathy:http://mechanical-sympathy.blogspot.com/
----------------------------------(我是分割线)----------------------------------
PS1: 转载请注明作者。
PS2: 下载:Disruptor介绍PPT
PS3:这是我第5个博客(不过前4个都不是技术blog,笑),以后我会尽量贴一些遇到的问题和思考到这里,水平有限,欢迎各位指出不足!


http://ifeve.com/dissecting-disruptor-whats-so-special/
正如名字所说的一样,它是一个环(首尾相接的环),你可以把它用做在不同上下文(线程)间传递数据的buffer。
如何使用Disruptor(二)如何从Ringbuffer读取
http://ifeve.com/dissecting_the_disruptor_how_doi_read_from_the_ring_buffer/
看国外的很多介绍资料,以及官方资料,还有坛主翻译的关于disruptor资料都有一个图,就是将日志/序列化/等等各种event塞到了一个ringbuffer里边,我现在困惑的就是这点,一个ringbuffer是否应该放多个topic或者多个类型的event。
例如我现在的流程有两个:1 核心业务流程处理 (短小快速,并发量高) 2. 业务流程之后的日志处理
因为日志通常采用log4j等记录,同类型事件多线程是无意义的。为了记录日志不影响核心流程的处理速度,往往会把日志丢到另外一个异步环境处理,我以前用队列解耦就是这么干的,但是看了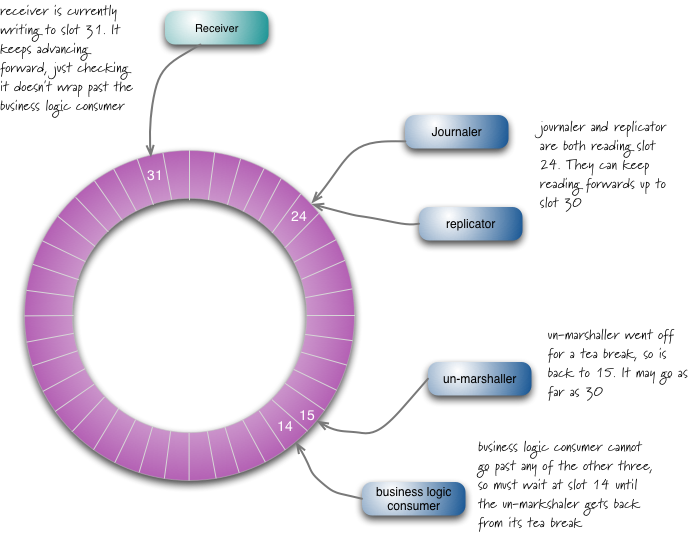
这个图,你会发现里边有几种事件,里边也包括了日志event,这样做还能做到通过解耦来平衡环节压力吗?
我看了disruptor的processor风格,一个是workpool,就是均衡负载,多个handler同质化,同一个时间只会被一个handler处理,另外一个风格就是并发分支,同一个事件,所有的handler都有机会处理。
如果使用均衡负载,handler根据event类型走处理分支,日志event可能会吃掉所有的handler线程池资源,那就跟ringbuffer的目的背道而驰了,相当于没用,直接用线程池是一样的效果。
还是用不同的barrier?
我是不是有什么地方理解错了?还请各位理解disruptor的大侠给予指点^_^。
另外看这幅图:
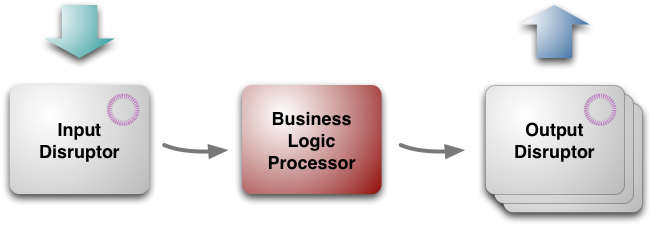
这个又是多个disruptor了,呵呵,除了分布式造成了这种割裂以外,如果输入和输出/业务处理都在一台主机上,是否就会使用同一个disruptor了?呵呵。
disruptor解决的thread之间的数据共享,如果按照这种角度出发,程序的分布式与否不应该成为disruptor的个数的依据。
[该贴被kuaiyuelaogong于2012-03-26 15:31修改过]