纸上得来终觉浅,绝知此事要躬行。
表
索引组织表
在InnoDB存储引擎中,表都是根据主键顺序组织存放的,这种存储存储方式的表称为索引组织表。在每张表都有一个主键(Primary Key),如果在创建表时没有显式的定义组件,通常有以下两个方式:
- 判断是否有非空的唯一索引,则设置为主键
- 以上不存在,
InnoDB存储引擎默认创建6个字节大小的DB_ROW_ID字段包含一个行ID,该ID在插入新行时会单调增加
注意:若存在多个非空唯一索引时,InnoDB存储引擎会选择创建表时第一个定义的非空唯一索引为主键
通过_rowid查看主键值:
mysql> select *,_rowid from t_dept;
+----+----------+-----------+--------+
| id | deptName | address | _rowid |
+----+----------+-----------+--------+
| 2 | 丐帮 | 洛阳 | 2 |
| 1 | 华山 | 华山 | 1 |
| 6 | 少林 | 少林寺 | 6 |
| 3 | 峨眉 | 峨眉山 | 3 |
| 5 | 明教 | 光明顶 | 5 |
| 4 | 武当 | 武当山 | 4 |
+----+----------+-----------+--------+
6 rows in set (0.00 sec)
--发现主键值就是id值,也就是说当前表的主键就是id
InnoDB逻辑存储
从InnoDB存储引擎的逻辑存储结构看,所有的数据都被逻辑的存放到一个空间中,称为表空间。表空间又由段(Segment)、区(extent)、页(page)组成。大致结构如下图:
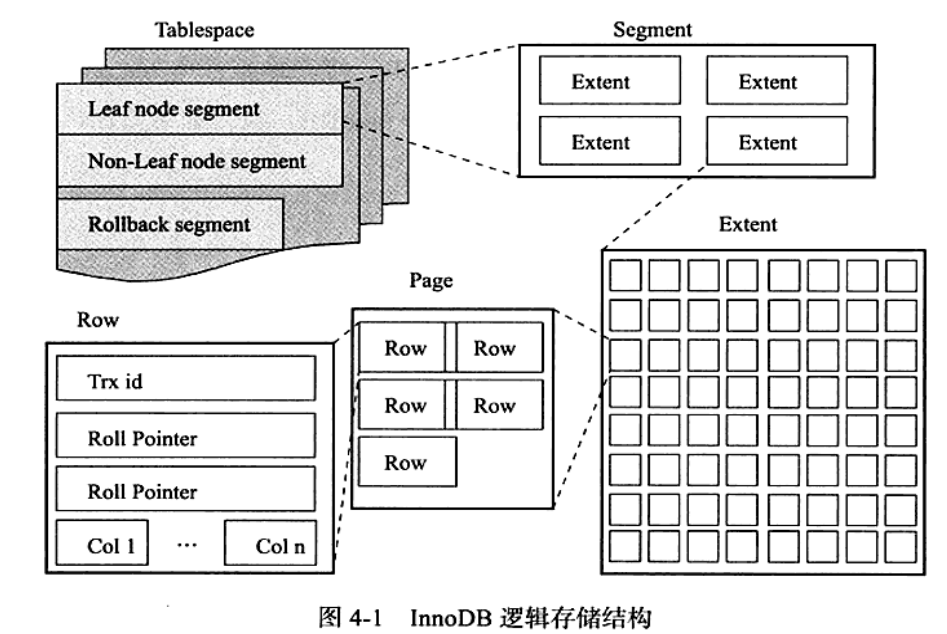
表空间
表空间可以看做是InnoDB存储引擎逻辑结构的最高层,所有的数据都存放在表空间当中。在默认情况下InnoDB有一个共享表空间ibdata1(可以在磁盘目录查看),即所有数据都存放在这个表空间。
但是如果用户启用了参数innodb_file_per_table,则每张表的数据单独放在一个表空间。
mysql> show variables like 'innodb_file_per_table';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_file_per_table | ON |
+-----------------------+-------+
1 row in set (0.03 sec)
注意:每张表的表空间只会存放数据、索引、插入缓存Bitmap页,其他数据,如:回滚(undo)信息、插入缓存索引页、系统事务信息、二次写缓冲(Double write buffer)还是会存放原来的共享表空间。
段
表空间有各个段组成,常见的段:数据段、索引段、回滚段等。其中索引段就是B+树的非索引节点。
区
区是由连续的页组成的空间,任何情况区的大小为1M。为了保证区中页的连续性,InnoDB存储引擎一次从磁盘申请4~5个区。InnoDB默认存储引擎页大小为16KB,即一个区中一共64个连续的页。
页
在InnoDB存储引擎,默认每个页的大小为16KB,常见的页类型有:
- 数据页(B-tree Node)
- undo页(undo log Page)
- 系统页 (System Page)
- 事务数据页(Transaction system Page)
- 插入缓冲位图页(Insert Buffer Bitmap)
- 插入缓冲空闲列表页(Insert Buffer Free List)
- 未压缩的二进制大对象页(Uncompressed BLOB Page)
- 压缩的二进制大对象页(compressed BLOB Page)
行
InnoDB存储引擎是面向列,也就是按行进行存放,每个页中最多存放16KB/2-200行,即7992行。
行格式
- Dynamic
- Compact
- Redundant
- Compressed
指定行格式:
CREATE TABLE 表名 (列的信息) ROW_FORMAT=行格式名称
--eg: create table user(id int ,name varchar(20)) ROW_FORMAT=Redundant;
ALTER TABLE 表名 ROW_FORMAT=行格式名称
-- eg: alter table user row_format=Dynamic;
PS:想要了解更多细节,可在文章末尾查看参考
页结构
InnoDB数据页由一下7个部分组成:
- File Header(文件头,固定
38字节) - Page Header(页头,固定
56字节) - Infimun 和 Superemum Records(最小记录和最大记录,固定
26字节) - User Records(用户记录,即行记录)
- Free Space(空闲空间)
- Page Directory(页目录)
- File Trailer(文件结尾信息,固定
8字节)
PS:想要了解更多细节,可在文章末尾查看参考
索引
索引是在存储引擎层实现的,而不是在服务器层实现的,所以不同存储引擎具有不同的索引类型和实现。
索引分类
1. B+ Tree索引
聚集索引
InnoDB存储引擎是索引组织表,表中数据按照主键顺序存放。而聚集索引就是按照每张表的主键构造一课B+树,同时叶子节点存放的即为整张表的行记录数据,也将聚集索引的叶子称为数据页。每个数据页都通过一个双向链表进行连接。
- 每一张表只能拥有一个聚集索引
- 查询优化器倾向于采用聚集索引,因为聚集索引能够在叶子节点直接找到数据,降低I/O次数
- 范围查询快,双向链表+已排序
- 聚集索引的存储并不是物理连续而是逻辑连续
- 页通过双向链表连接,页按照主键顺序排序
- 每个页中的记录通过链表进行维护
页示意图:
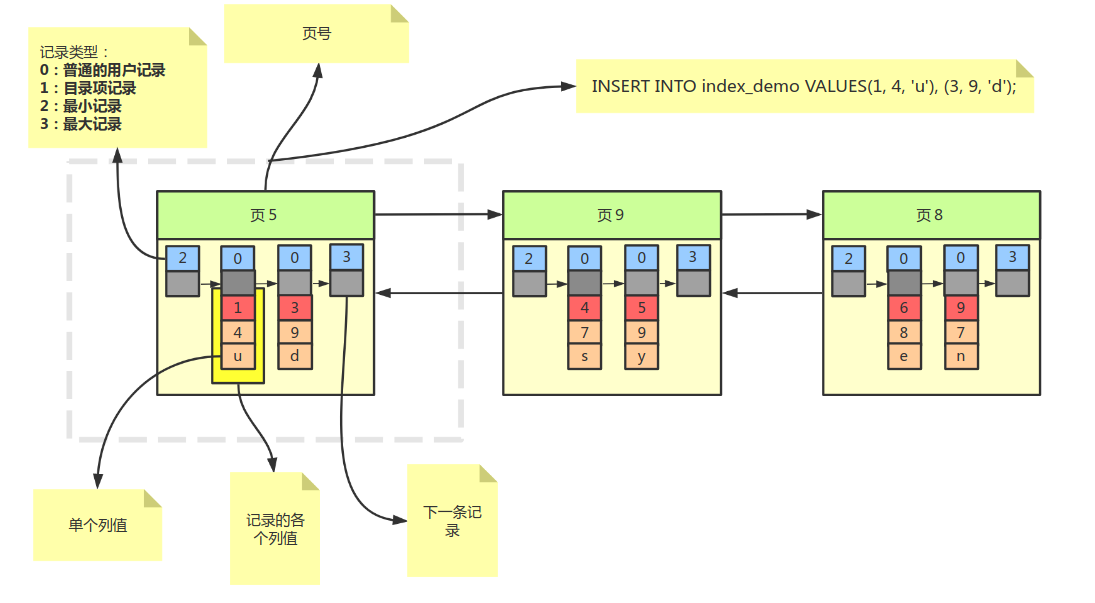
聚集索引示意图:
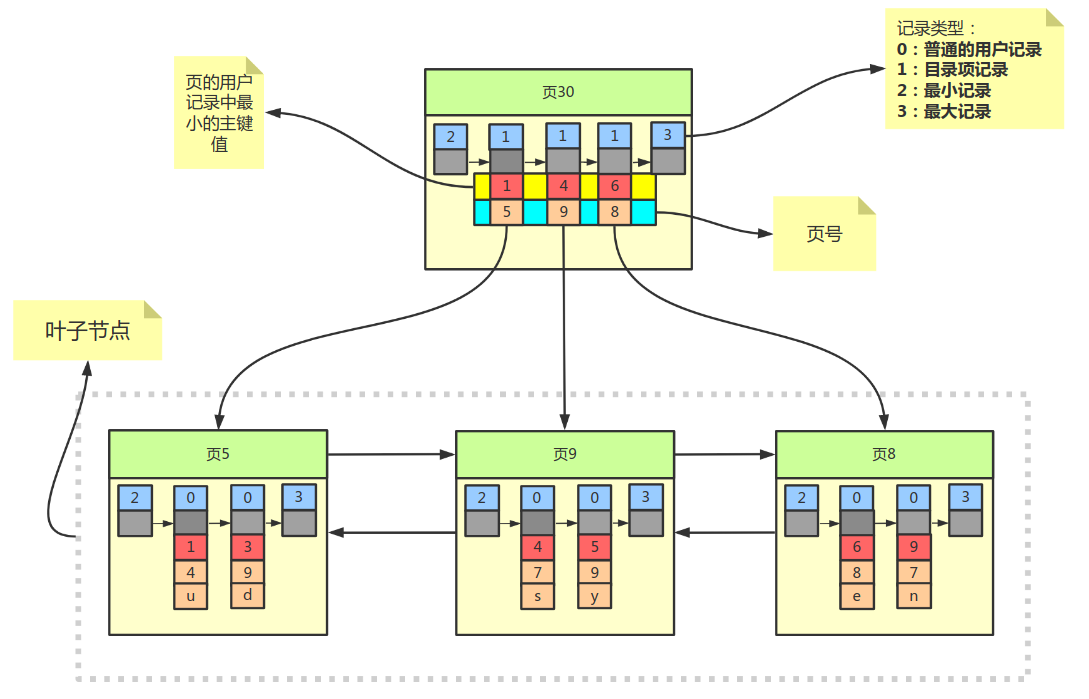
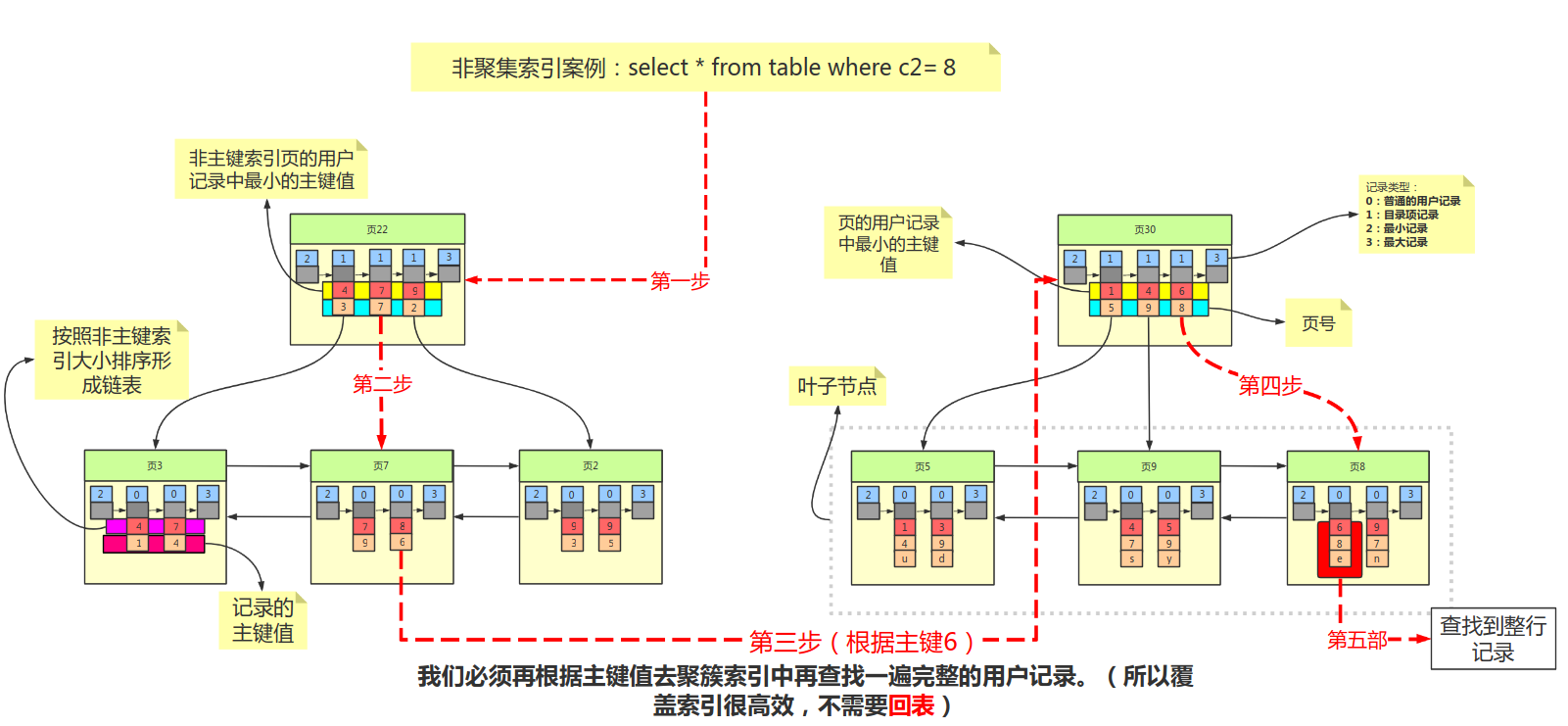
辅助索引(非聚集索引)
叶子节点不包含行记录的所有数据。叶子节点除了包含键值外,每个叶子节点中的索引行包含一个书签,通过书签可以找到索引对应的行数据
当通过辅助索引来寻找数据时,InnoDB存储引擎会遍历辅助索引,通过叶子节点指针获得指向主键索引的主键,然后通过主键索引来查找完整行记录。
辅助索引示意图:
联合索引
联合索引是指对表上的多个列进行索引,联合索引的创建方法和单个索引创建方法一样,不同之处在于对多个列索引。
比方说我们想让B+树按照c2和c3列的大小进行排序,这个包含两层:
- 先把各个记录和页按照
c2列进行排序。 - 在记录的
c2列相同的情况下,采用c3列进行排序
为c2和c3列建立的索引的示意图如下:
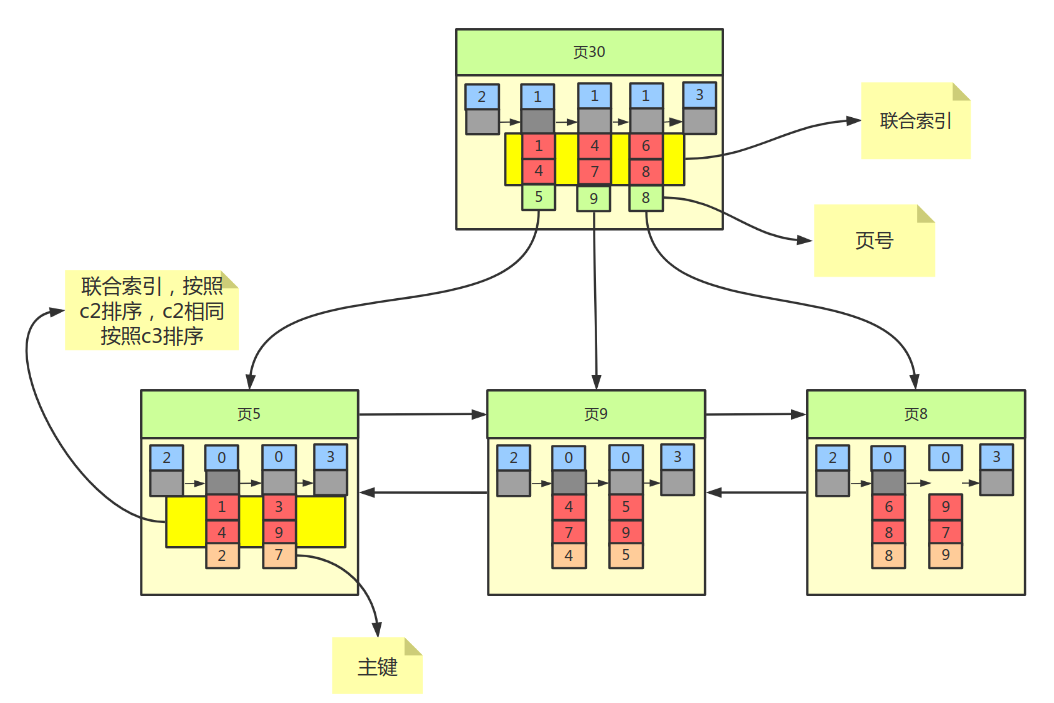
如图所示,我们需要注意一下几点:
- 每条
目录项记录都由c2、c3、页号这三个部分组成,各条记录先按照c2列的值进行排序,如果记录的c2列相同,则按照c3列的值进行排序。 B+树叶子节点处的用户记录由c2、c3和主键c1列组成。
千万要注意一点,以c2和c3列的大小为排序规则建立的B+树称为联合索引,它的意思与分别为c2和c3列建立索引的表述是不同的,不同点如下:
- 建立
联合索引只会建立如上图一样的1棵B+树。 - 为
c2和c3列建立索引会分别以c2和c3列的大小为排序规则建立2棵B+树。
2. 哈希索引
InnoDB存储引擎使用哈希算法来对字典进行查找,其冲突采用链地址法,哈希函数采用除法散列。即哈希函数为:
h(k) = k mod m
哈希索引只能用来搜索等值查询,如:
select * from table where index_col='xxx';
自适应哈希索引是有InnoDB存储引擎自己控制,不过可以通过参数innodb_adaptive_hash_index来禁用或启用,默认启用。
3. 全文检索
全文检索是将存储于数据库中的整本书或整篇文章中的任意内容信息找出来的计数,它可以根据需要获取全文中有关章、节、段、句等信息也可以进行各种统计和分析。
倒排索引
全文检索通常使用倒排索引来实现,也是一种索引结构。它在辅助表中存储单词或单词自身一个或多个文档中所在位置之间的映射,通常利用关联数组实现,其拥有两种表现形式:
inverted file index:表现形式{单词,所在文档ID}full inverted index:表现形式{单词,(单词所在文档的ID,在具体文档中的位置)}
例如,对于下面的例子,表存储的内容:
| DocumentId | Text |
|---|---|
| 1 | Please porridge hot,Please porridge code |
| 2 | Please porridge hot |
| 3 | Nine days old |
对于inverted file index的关联数组存储如下:
| Number | Text | Documents |
|---|---|---|
| 1 | code | 1 |
| 2 | Please | 1,2 |
| 3 | old | 3 |
可以看到单词code存在于文档1,而单词Please存在于文档1和2,下面是通过full inverted index存储:
| Number | Text | Documents |
|---|---|---|
| 1 | code | (1:6) |
| 2 | Please | (1:1,4),(2:1) |
| 3 | old | (3:3) |
可以看到,full inverted index还存储了单词所在的位置信息,相比之下占用更多的空间,但是能够更好的定位数据。
参考链接:
MySQL技术内幕 InnoDB存储引擎 第2版
MySQL索引
MySQL的索引(中)
InnoDB数据页结构
InnoDB记录存储结构