1、python没有显式声明变量类型,不代表写代码时候可以没有类型概念,当使用三方包时候,三方包的方法经常返回一个三方包里面的自定义的类的实例,就是不是普通的int str list dict这些类型,得到这么个变量怎么处理他手足无措,连自己写的变量是什么类型的都是模糊的,那写代码就是蒙蔽的靠猜,或者只能生搬硬套网上的写法,多年前开始写py就一直是这么一个蒙蔽的状态。
2、pycahrm是有自动方法补全的,任何变量都是某个类的实例,所以当变量加上 . 这个符号,就可以自动补全了,一定程度弱化了需要知道类型的必要性。但是有些情况下多层返回没有写标准的注释或者返回是带if分支的,pycharm决定不了到底是什么类型,那就补全不了,当使用这个变量时候,怎么使用他就没有pycharm自动补全提示了,必须要找到变量的类型,就是找到变量是哪个类实例化出来的,这样才能使用这个变量。
3、比如在重写logging模块的handler类的commit方法时候,第二个参数是record,重写此方法时候,record参数加点是不能自动补全的,那么record有什么属性和方法,就不知道了,必须百度查看老司机们怎么用这个record变量的(而且这种很偏门的东西不好搜)。但是python命名是有规则的,类名的首字母大写的,实例最好是小写的类名,根据这规律,很容易在logging模块找到一个叫LogRecord的类,找到record变量的类型了,那就很容易使用他了。
4、如果从不写类,就不熟悉类,调用三方库存在很多障碍,纯看教程文档的api是很得到很详细的使用方法,必须定位到三方包的那个类,才能更好的使用。
5、很多笨猪说写代码从不需要类,说requests.get是函数,pymsql的conect都是函数,人家三方库高手全是写函数,自己为什么需要类 。这样认为就大错特错了
pymsql里面的连接是Connection类。
拿pymsql类来说,__init__.py里面


所以看到网上那个的大部分这个写法,看到是在调用函数一样 :conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='', db='tkq1', charset='utf8')
其实是在里面实例化一个Connection类了,上面的写法等同于conn = pymysql.Connection(host='127.0.0.1', port=3306, user='root', passwd='', db='tkq1', charset='utf8'),那么后续得到这个conn变量后怎么使用他,知道他的类型是Connection就好办了
再来说requests的get函数,也是使用了类
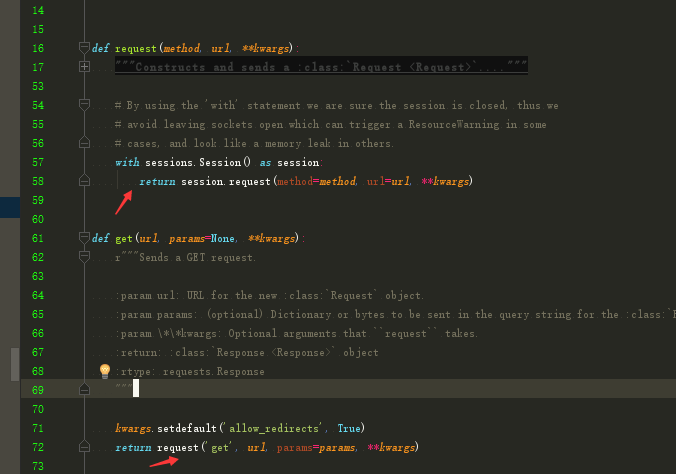
可以看到get函数调用request函数,request函数是实例化了一个session类,并且返回了一个Response类的实例。(这也是为什么要保持cookie在连续访问时候,不能使用get函数,因为每次都新实例化Session类造成cookie不能在多个请求中共享,要直接使用Session类的原因了)
7、而且requests的get函数返回得到的变量的类型是Response,所以命名上最好是 resp 或者response = requests.get(url) ,见过不少人喜欢写text = requests.get(url) ,真的很让人困惑,代码长了不知道写的什么玩意。这 样命名就好像喜欢写 x_list = {"a":1},y_dict = [3,4,5],这种写代码没时候有类型意识的,真得是只有自己能看懂,非常的不好。例如下面这样的,代码一长就弄混了,把a变量误认为了是A类型,误人。
class A():
pass
class B():
pass
b = A()
a = B()
8、类和模块比,在多实例(模块只能是单例)和继承后者组合都有很大优势。自己从不写类,就会造成除了基本类型 字符串 整形 列表类型 字典类型 元祖类型和一些三方库的类型以外,没有自己的类型。还会造成使用新的三方包库的时候,手足无措,学用起来很慢,必须找个网上现成的例子照抄。
9、类就是类型,类型就是类,如果还认为不需要学习类,那就是觉得不需要知道代码中的变量是什么类型了。