输出是一个连续的数值。
模型表示
对于一个目标值,它可能受到多个特征的加权影响。例如宝可梦精灵的进化的 cp 值,它不仅受到进化前的 cp 值的影响,还可能与宝可梦的 hp 值、类型、高度以及重量相关。因此,对于宝可梦进化后的 cp 值,我们可以用如下线性公式来表示:
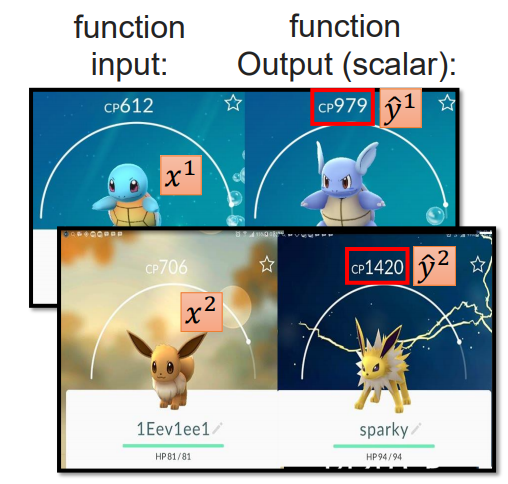
上述的线性函数就是我们的模型,学习目标就是去根据观察的值去拟合权重参数 \(\theta\) 和偏置 \(b\) 。为了简化模型表示,可以令 \(x_0=1\) ,和 \(\theta_0 = b\) ,则可以将线性函数表示为如下形式:
表示为矩阵相乘的形式,则我们的目标就是期望学习得到函数 \(h_{\theta}(x_i)=\theta^Tx_i\) 。
模型评估
上述的线性函数表示的是一个包含无数个可能的模型的假设空间,每一组 \(\theta\) 值都会确定一个模型,所以我们需要根据样本空间来找到最佳的模型。
首先,我们需要对模型的好坏进行定义。即什么样的模型是一个好的模型,而什么样的模型是一个坏的模型。模型的好坏的最直观的定义就是预测的值和真实的值之间的差距,如下图所示,黑色的直线是我们学习到的模型,红色的 × 是真实的值,则模型的误差就可以用真实值和预测值之间的欧氏距离来进行评估。距离越小,表示预测的越准确,反之,则表示预测的效果越差。
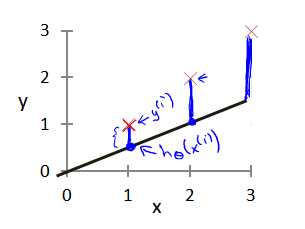
我们用 \(x^{(i)}\) 表示第 \(i\) 个样本的特征,\(h_{\theta}(x^{(i)})\) 表示对该样本的预测值,而 \(y^{(i)}\) 则表示对应的真实值。因此,对于模型的误差,我们可以用所有样本的平均误差来表示,即:
这里的 \(i\) 和模型表示中的 \(i\) 是不同的含义,前者表示第 \(i\) 个样本,后者表示样本的第 \(i\) 个特征。
上述误差函数又叫做代价函数或损失函数,在线性回归中,通常用均方误差来作为代价函数。
计算代价函数的Python代码如下:
def compute_cost(X, y, theta):
inner = np.power(((X * theta.T) - y), 2)
return np.sum(inner) / (2 * len(X))
模型学习
有了上述的代价函数之后,我们的学习目标就十分清晰了。我们的目标就是学习到一个模型,使得代价函数的值最小。学习模型其实就是等价于学习权重参数向量 \(\theta\) ,因此,我们的目标函数也应该是关于参数 \(\theta\) 的函数。令 \(\theta^*\) 表示我们的目标模型,则目标函数可以表示为:
该目标函数我们可以用梯度下降的方法来求解,即每次都往函数的负梯度的方向去进行搜索。我们知道,一个函数的最小值一般会出现在该函数的极值点上,前提是该函数是凸函数(这里先不对凸函数做过多的阐述)。因此对于一个初始权重参数 \(\theta^{(0)}\) ,我们可以计算函数在该参数位置的导数,如果导数大于0,则表示目标函数在该点是递增的,则我们需要降低我们的 \(\theta\) 值。反之,如果当前的导数小于0,则表示目标函数在该点是递减的,为了找到更小的值,我们应该增加我们的 \(\theta\) 值。过程如下图所示:
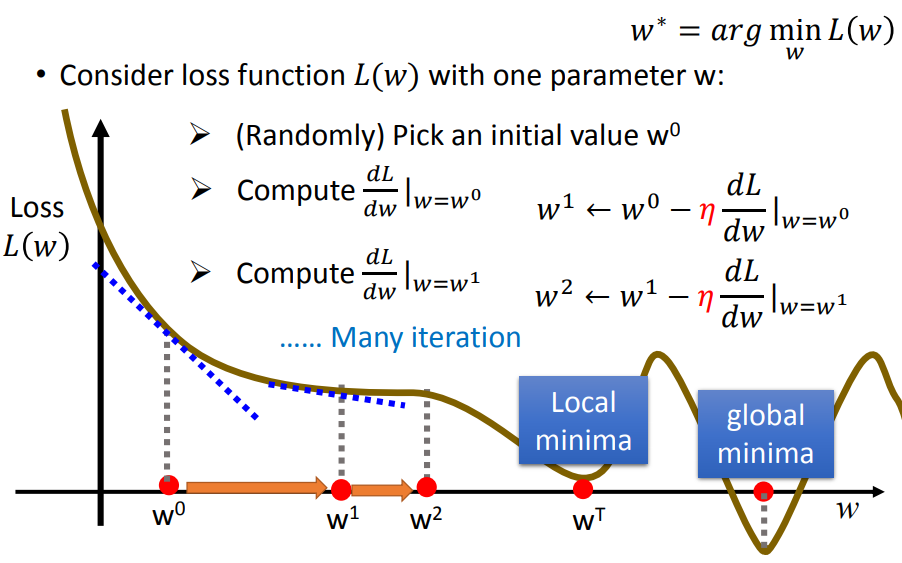
图片来源于李宏毅《机器学习》2017,\(w\) 等价于 \(\theta\)。
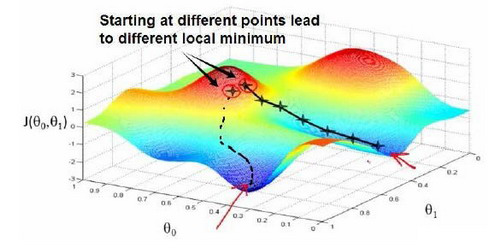
很显然,该方法最终会落入到一个极值点,但是该极值点不一定是全局最小值,而可能是局部最小值。因为梯度下降方法在导数为0的点就不会对参数进行更新了,所以当遇到局部最小值点时,由于目标函数的导数为0,所以权重参数会收敛,学习到的模型就不再是一个最佳的模型,找到的这种解叫做局部最优解。
后续在介绍如何解决梯度下降过程中的局部最优解的问题...
现在我们知道了线性回归模型的完整学习过程,其目标就是最小化代价函数来学习得到一组权重参数,而且我们也知道可以利用梯度下降的方法来寻找最佳的权重参数。接下来将介绍如何去更新我们的权重参数。
权重参数 \(\theta\) 是一个向量,它与样本的特征数目是相对应的,如果样本含有 n 个特征,则权重参数的维度为 n+1 ,注意,还包含一个偏置。对参数向量的求导,实质上就是对各个方向进行偏微分。依然假设我们初始的权重参数向量为 \(\theta^{(0)}\) ,现在我们求第 \(j\) 个权重参数的梯度:
此处也很好的解释了为什么目标函数要增加一个
1/(2m),这是为了最后更新权重参数时更方便计算。同时,乘以一个正数也不会影响函数的极小值点。
前面分析了,权重参数的更新应该是超该参数的负梯度方向更新。所以对于参数 \(\theta_j\) ,其在下一轮的更新值为:

其它的参数更新与上述的更新方式相同,注意:上述式子需要同时更新一组参数 \((\theta_0,\theta_1,\cdots,\theta_n)\) 后再进行下一次迭代。\(\alpha\) 是学习率。
上述的更新方式叫做批量梯度下降,即每次根据所有样本的综合误差来更新参数。相对应的被称为随机梯度下降,即每计算一个样本的值就更新权重参数。两者的区别和优缺点后续再进行介绍。梯度下降在很多机器学习算法中都有使用,包括大部分的深度学习,所以一定要理解其原理。
模型总结
现在我们已经对线性回归的原理和问题解决方法都有了一定的了解,接下来将对整个算法的流程进行总结,并分析线性回归存在的一些问题,以及优化的方法。
算法流程
- 根据特征维度随机初始化一组参数 \((\theta_0,\theta_1,\cdots,\theta_n)\) ;
- 根据该参数计算所有样本的预测值 \(h_{\theta}(x)\);
- 根据公式(9)更新权重参数;
- 重复执行步骤2和步骤3,直到权重参数收敛或者达到一定的迭代次数。
存在的问题
- 只适用于解决线性可分的问题,因为目标函数是多种变量的线性组合;
- 对异常值敏感
算法优化
包括岭回归和Lasso回归。