原始数据如下: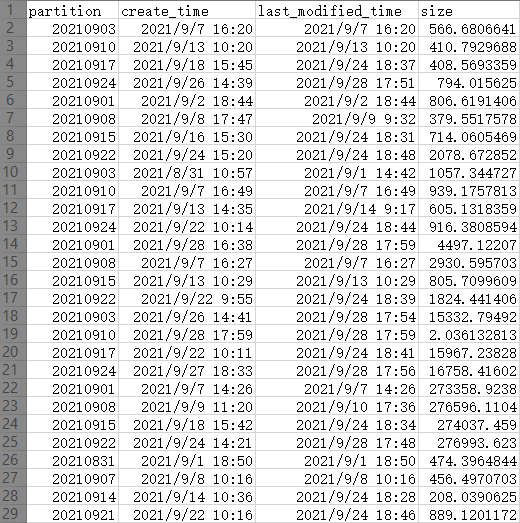
(图是从 excel 截的,最左1行不是数据,是 excel 自带的行号,为了方便说明截进来的)
除去首行是标题外,有效数据为 28行 x 4列
目前的需求是根据 partition 分组,然后取每组的前 2 行,如果不考虑排序,代码如下:
(把head()里面的数字改成 n 就可以取 n 行)
import pandas as pd
esp_df = pd.read_excel('excel文件路径', sheet_name='Sheet名')
esp_df.groupby(['partition', 'create_time', 'last_modified_time']).mean().reset_index(drop=False).groupby('partition').head(2)
结果如下: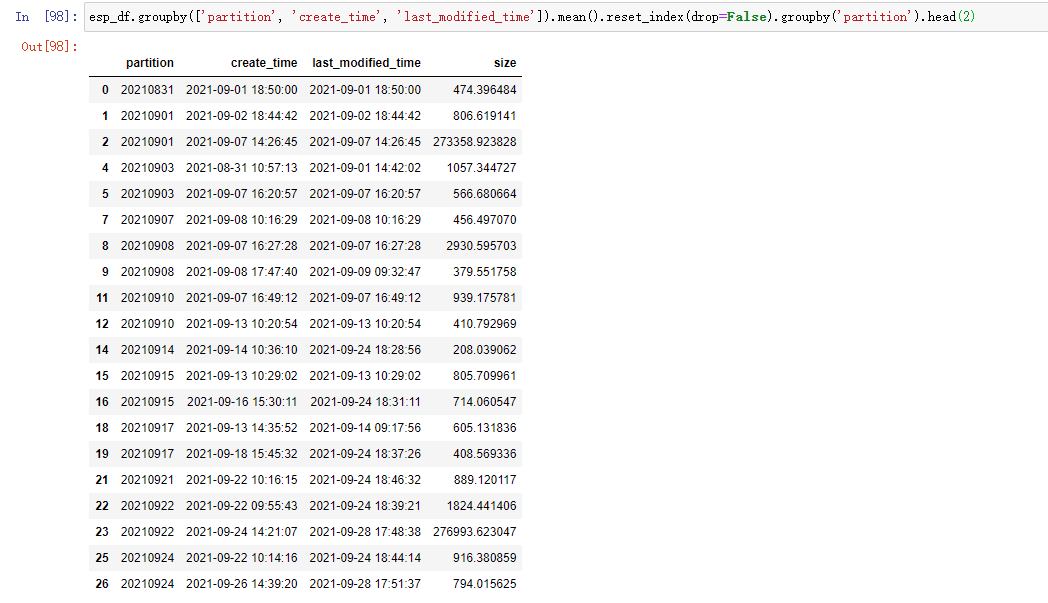
分别说明如下:
- groupby:分组,这里是根据数据中的 3 列来一起分组,因为我们并不需要做聚合运算,所以这么取可以保留原始数据不变。原始数据只有 4 列,这里 groupby 了 3 列,只剩下 size(其实把 size 放进去一起 groupby 也没问题)
- mean:求平均值,但是在这里没用,因为上一步的 groupby 取了前面的 3 列,在本例中,前 3 列并在一起就能得到一个唯一的一行,所以这里其实也只是每一行数据自己求平均数,结果等于它本身。同理,这里替代成求和函数
sum()也是一样的。但是不能省略,因为**省略后它就是一个DataFrameGroupBy类型的变量,不是DataFrame,而DataFrameGroupBy是没有后面的reset_index方法的 - reset_index:重置索引,groupby 之后,结果集的索引就变成了 groupby 里面的 key,这个
reset_index把这个索引重新退回为数据。
举例说明,在应用reset_index之前,即使用mean()之后的数据是这样的:
可以看到左边的 3 列,也就是 groupby key 的 partition、create_time、last_modified_time 是加粗了的,说明此时这 3 列都是索引;而且 partition 因为有相同的行,还被合并了。显然这不是我们想要的。reset_index 把它们重新放回到数据列里
参数中的 drop 作用是是否保留(重置前)的索引
数据就又回来了,索引变成了原来默认的(0123...)
- groupby:再次根据 partition 分组
- head: 取每个分组的前 n 行
如果要排序
本例中,如果要先根据 partition 分组,然后再根据 size 倒序(从大到小)再取前 2 行,则代码如下:
esp_df.groupby(['partition']).apply(lambda x: x.sort_values(["size"], ascending = False)).reset_index(drop=True).groupby('partition').head(2)
结果如下:
摘抄至 https://www.cnblogs.com/wuzhiblog/p/pandas_get_first_n_rows_for_each_group.html