1。消息系统!就是提供一个中间层,生产者只需要把消息提交到特定的中间层,消费者只需要从中间层去拿信息就可以了。
2。消息系统的基本要求:
- 性能要高。包含消息投递和消息消费,都要快。一般通过增加分片数获取并行处理能力。数据库显然是有瓶颈的。
- 消息要可靠。在某些场景,不能丢消息。生产、消费、MQ端都不能丢消息。一般通过增加副本,强制刷盘来解决。数据库显然也要通过主从来做备份的。
- 扩展性要好。能够陪你把项目做大,陪你到天荒地老。增加节点集群增大后,不能降低性能。数据库的扩展性肯定是存疑的,你可能会引入一些复杂的分库分表组件。
- 生态成熟。监控、运维、多语言支持、社区的活跃。这决定了你用的消息队列值不值得你信赖。
3。消息系统的作用:
- 削峰 用于承接超出业务系统处理能力的请求,使业务平稳运行。这能够大量节约成本,比如某些秒杀活动,并不是针对峰值设计容量。
- 缓冲 在服务层和缓慢的落地层作为缓冲层存在,作用与削峰类似,但主要用于服务内数据流转。比如批量短信发送。
- 解耦 项目伊始,并不能确定具体需求。消息队列可以作为一个接口层,解耦重要的业务流程。只需要遵守约定,针对数据编程即可获取扩展能力。
- 冗余 消息数据能够采用一对多的方式,供多个毫无关联的业务使用。
- 健壮性 消息队列可以堆积请求,所以消费端业务即使短时间死掉,也不会影响主要业务的正常进行。
4。副本:
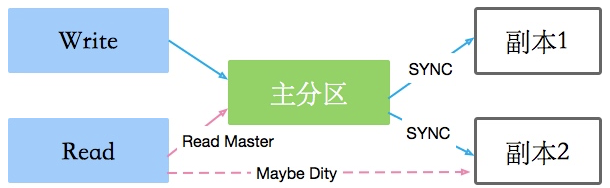
- 优点
- 单机上的任何数据都是不可信的,一般通过冗余多个副本来保证数据的安全。
- 另一个作用,就是提供额外的计算能力,比如某些请求,会落到副本上。副本越多,可用性越高。
- 缺点
- 数据的同步存在延迟。这就存在一个问题,读副本的请求读到的数据,可能不是最新的,这就是数据的一致性发生了改变。
- 当然有些手段能保证数据的一致性,但副本越多,延迟越大。
- 副本的加入还会引入主从的问题。主节点死掉以后,要有副本节点顶上去,这个过程的协调需要时间,其间部分不可用。
5。分区:
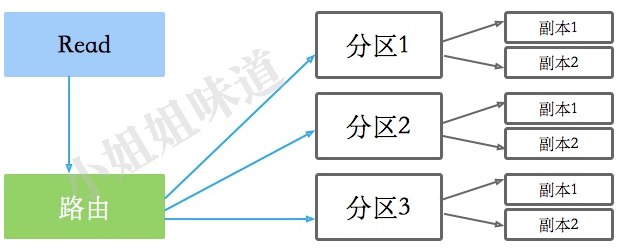
- 而当一类数据足够大(比如说某张表),在其上的操作已经非常耗时的情况下,就需要对此类数据进行切割,将其分布到多台机器上。
这个切割过程就是Sharding,通过一定规则的分片来减少单次查询数据的规模,增加集群容量。
- 针对一个分片的数据,只能有一个写入的地方,这就是
master,其他副本都是从master复制数据。 - 副本能够增加读操作的并行读,但会读到脏数据。
- 如果你想要读到的数据是一致的,可以采用同步写副本的方式,
- 比如KAFKA的
ack=-1,只有全部同步成功了,才认为本次提交成功。
- 副本太多,这个过程会非常的慢。你可能想要通过分配写入和读取的副本个数来协调写入和读取的效率,
Quorum的R+W>N就是一个权衡策略。
Kafka:是一个分布式消息(存储)系统。。Kafka的本分核心,就是当作消息队列用。分布式系统通过分区增加并行度;通过副本增加可靠性,kafka也不例外。
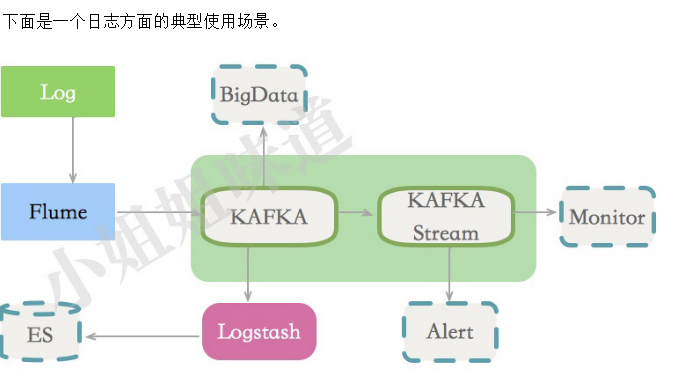
Kafka的主要功能和应用场景:
- 传递业务消息
- 用户活动日志 • 监控项等
- 日志
- 流处理,比如某些聚合
- Commit Log,作为某些重要业务的冗余
- Event Source,实践溯源,DDD中的概念
Kafka为什么快:
- Cache Filesystem Cache PageCache缓存
- 顺序写 由于现代的操作系统提供了预读和写技术,磁盘的顺序写大多数情况下比随机写内存还要快
- Zero-copy 零拷⻉,少了一次内存交换
- Batching of Messages 批量量处理。合并小的请求,然后以流的方式进行交互,直顶网络上限
- Pull 拉模式 使用拉模式进行消息的获取消费,与消费端处理能力相符
Kafka名词解释:
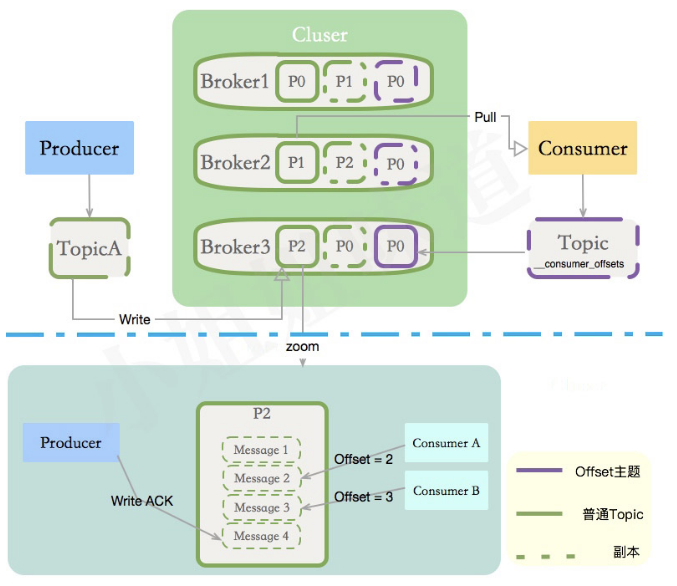
- 你在一台机器上安装了Kafka,那么这台机器就叫
Broker,KAFKA集群包含了一个或者多个这样的实例。- 这只是一个命名而已,并没有什么特定含义。
- 负责往KAFKA写入数据的组件就叫做
Producer,消息的生产者一般写在业务系统里。 - 发送到KAFKA的消息可能有多种,如何区别其分类?就是
Topic的概念。一个主题分布式化后,可能会存在多个Broker上。 - 将Topic拆成多个段,增加并行度后,拆成的每个部分叫做
Partition,分区一般平均分布在所有机器上。 - 那些消费Kafka中数据的应用程序,就叫做
Consumer,我们给某个主题的某个消费业务起一个名字,这么名字就叫做Consumer Group- 再看一下Kafka Server的配置文件,最重要的两个参数:
partitions和replication.factor,其实就非常好理解了。
- 再看一下Kafka Server的配置文件,最重要的两个参数:
- 再来说一个最重要的概念。Kafka解决副本之间的同步,采用的是
ISR,这是一个面试Kafka必考的点之一。- ISR全称"In-Sync Replicas",是保证HA和一致性的重要机制。
- 副本数对Kafka的吞吐率是有一定的影响,但极大的增强了可用性。一般2-3个为宜。
- 副本有两个要素,一个是数量要够多,一个是不要落在同一个实例上。
- ISR是针对与Partition的,每个分区都有一个同步列表。
- N个replicas中,其中一个replica为leader,其他都为follower, leader处理partition的所有读写请求,其他的都是备份。
- 与此同时,follower会被动定期地去复制leader上的数据。
- 如果一个flower比一个leader落后太多,或者超过一定时间未发起数据复制请求,则leader将其从ISR中移除。
- 当ISR中所有Replica都向Leader发送ACK时,leader才commit。
来自https://mp.weixin.qq.com/s/jXO2XAG5lMke_GAXhCXuIw