偷懒的缘故
大家也可以看到笔者的很多随笔都有一定的美化,然而每次都是手工去调整,如果是内容比较少的随笔可能会比较容易,但是遇到内容比较多的随笔,就需要花费比较多的时间了,最终的情况可能是我们写了半个小时,美化一下就要十五分钟了,对于我们这类大懒人,太浪费时间了,于是笔者今天上午攻读了Perl,写出了一个基本自动化排版的脚本,下面将由我来论述。
选定工具
自然我们要使用perl,当然缺少不了一个好的ide,这里笔者选择了Padre,如果读者的要挑战自我可以使用文本编辑器+命令行来写。
头疼的代码块
一上来笔者就遇到这个问题,就是我们自动化排版可不能修改代码部分,因为这部分已经排版好了,但是它毕竟是整体的一部分。正则表达式一样会匹配,如果我们非要用正则过滤掉这块也不是不可能,但是正则的长度会太长。而笔者想的是我们可以将所有的代码部分的内容提取出来,这样剩下的都是我们可以处理的。最后我们处理完成之后就可以将原本的内容恢复回去,当然这中间需要一个占位符,而笔者选择的是用<script>,为什么用这个标签呢?大家都懂的。
通过查看博客园代码块部分的html:

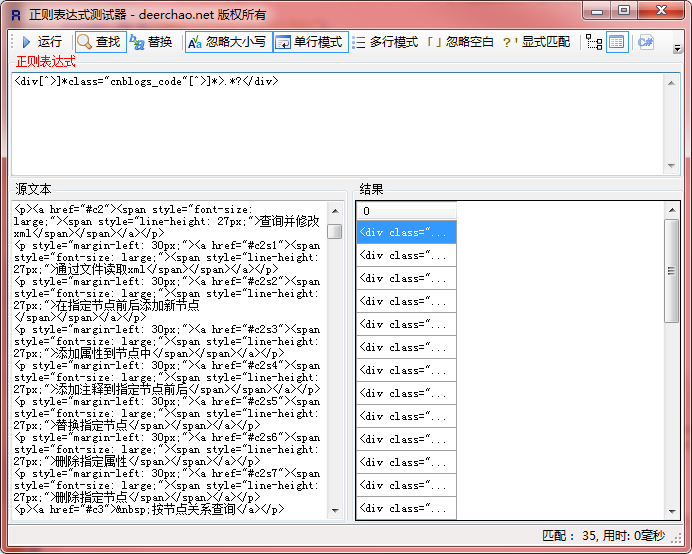
当然读者可以查看自己的html标签,一定会发现只要是代码块都会有一个div标签,并且这个标签的class是cnblogs_code。多亏这个class下面我们可以开始写正则来匹配这部分了,这里笔者用的是RegexTester,需要这个工具的可以猛点这
笔者随便找了一篇随笔最后的正则如下所示:
然后就是写到perl中去了:

上面我们定义两个文件,一个是代排版的随笔html,第二个是排版后的html。
下面我们继续,还要能够将代码块恢复回去:

我们可以看到红色框住的部分,我们利用perl的特点才能够办到(ps而且顺序要跟提取的时候一样否则就玩完了)。
剩下的顺理成章就应该是将该替换的替换了,首先我们从基本的内容入手,笔者喜欢将字体设置为楷体,16px,所以具体的正则和perl如下:

按照笔者的排版习惯我又写出了下面的几个正则,将h1和h3设置为带有动画的样式:

依次我们还要替换将匹配的结果进行替换:

为了区分开来笔者将他们单独写成了子程序,这里我们可以发现Perl语言的简洁,下面我们就要调用这些子程序:

当然光看是没用的,需要源码点击这里下载