例子需求:
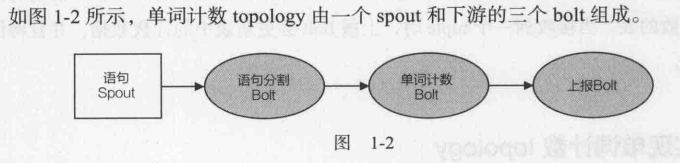
spout:向后端发送{"sentence":"my dog has fleas"}。一般要连数据源,此处简化写死了。
语句分割bolt(SplitSentenceBolt):订阅spout发送的tuple。每收到一个tuple,bolt会获取"sentence"对应值域的值,然后分割为一个个的单词。最后,每个单词向后发送1个tuple:
{"word":"my"}
{"word":"dog"}
{"word":"has"}
{"word":"fleas"}
单词计数bolt(WordCountBolt):订阅SplitSentenceBolt的输出。每当接收到1个tuple,会将对应单词的计数加1,最后向后发送该单词当前的计数。
{"word":"dog","count":5}
上报bolt:接收WordCountBolt输出,维护各单词对应计数表,并修改累计计数值。
代码实现:
package com.ebc.spout; import com.ebc.Utils; import org.apache.storm.spout.SpoutOutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichSpout; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Values; import java.util.Map; /** * @author yaoyuan2 * @date 2019/4/11 */ public class SentenceSpout extends BaseRichSpout { private SpoutOutputCollector collector; private final String [] sentences = {"a b", "c a"}; private int index = 0; /** * 所有spout组件在初始化时调用这个方法。 * @param conf:storm配置信息 * @param context:topology中组件信息 * @param collector:提供了emit tuple方法 * @return void */ @Override public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { this.collector = collector; } @Override public void nextTuple() { this.collector.emit(new Values(sentences[index])); index++; if (index >= sentences.length) { index = 0; } Utils.waitForMillis(1); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("sentence")); } }
package com.ebc.blot; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values; import java.util.Map; /** * @author yaoyuan2 * @date 2019/4/11 */ public class SplitSentenceBolt extends BaseRichBolt { private OutputCollector collector; /** * 类似spout中的open()方法,可初始化数据库连接 * @param stormConf * @param context * @param collector * @return void */ @Override public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { this.collector = collector; } /** * <pre> * 每当从订阅的数据流中接收1个tuple,都会调用这个方法。 * 形如:{"sentence":"my dog has fleas"} * </pre> * @param input * @return void */ @Override public void execute(Tuple input) { String sentence = input.getStringByField("sentence"); String [] words = sentence.split(" "); for (String word:words) { this.collector.emit(new Values(word)); } } /** * <pre> * 每个tuple包含一个"word",如 * {"word":"my"} * {"word":"dog"} * {"word":"has"} * {"word":"fleas"} * </pre> * @param declarer * @return void */ @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word")); } }
package com.ebc.blot; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values; import java.util.HashMap; import java.util.Map; /** * @author yaoyuan2 * @date 2019/4/11 */ public class WordCountBolt extends BaseRichBolt { private OutputCollector collector; private HashMap<String,Long> counts = null; /** * <pre> * 一般情况下, * 在构造函数中,只能对可序列化的对象赋值和实例化 * 在prepare中,对不可序列化的对象实例化。 * </pre> * @param stormConf * @param context * @param collector * @return void */ @Override public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { this.collector = collector; this.counts = new HashMap<String,Long>(); } @Override public void execute(Tuple input) { String word = input.getStringByField("word"); Long count = this.counts.get(word); if (count == null) { count = 0L; } count++; this.counts.put(word,count); this.collector.emit(new Values(word,count)); } /** * 形如:{"word":"dog","count":5} * @param declarer * @return void */ @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word","count")); } }
package com.ebc.blot; import lombok.extern.slf4j.Slf4j; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.tuple.Tuple; import java.util.*; /** * @author yaoyuan2 * @date 2019/4/11 */ @Slf4j public class ReportBolt extends BaseRichBolt { private HashMap<String,Long> counts = null; @Override public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { this.counts = new HashMap<String,Long>(); } @Override public void execute(Tuple input) { String word = input.getStringByField("word"); Long count = input.getLongByField("count"); this.counts.put(word,count); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { //该bolt不再向后emit任何数据流 } /** * <pre> * 当topology关闭时输出最终的计数结果。 * 通常,clean()方法用来释放bolt占用的资源,如数据库连接。 * 注意,当topology在strom集群上运行时,clean()不能保证会执行,但本地模式能保证执行。 * </pre> * @return void */ @Override public void cleanup() { log.info("最终counts"); List<String> keys = new ArrayList<String>(); keys.addAll(this.counts.keySet()); Collections.sort(keys); for (String key : keys) { System.out.println(key + " : " + this.counts.get(key)); } log.info("---------"); } }
package com.ebc; import com.ebc.blot.ReportBolt; import com.ebc.blot.SplitSentenceBolt; import com.ebc.blot.WordCountBolt; import com.ebc.spout.SentenceSpout; import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org.apache.storm.topology.TopologyBuilder; import org.apache.storm.tuple.Fields; /** * @author yaoyuan2 * @date 2019/4/12 */ public class WordCountTopology { private static final String SENTENCE_SPOUT_ID = "sentence-spout"; private static final String SPLIT_BOLT_ID = "split-bolt"; private static final String COUNT_BOLT_ID = "count-bolt"; private static final String REPORT_BOLT_ID = "report-bolt"; private static final String TOPOLOGY_NAME = "word-count-topology"; public static void main(String[] args) { SentenceSpout spout = new SentenceSpout(); SplitSentenceBolt splitBolt = new SplitSentenceBolt(); WordCountBolt countBolt = new WordCountBolt(); ReportBolt reportBolt = new ReportBolt(); TopologyBuilder builder = new TopologyBuilder(); builder.setSpout(SENTENCE_SPOUT_ID,spout); //SentenceSpout --> SplitSentenceBolt。shuffleGrouping:要求spout将tuple随机均匀的分发给splitBolt实例 builder.setBolt(SPLIT_BOLT_ID,splitBolt).shuffleGrouping(SENTENCE_SPOUT_ID); //SplitSentenceBolt --> WordCountBolt。fieldsGrouping:field="word"的tuple会被路由到同一个WordCountBolt实例中。 builder.setBolt(COUNT_BOLT_ID,countBolt).fieldsGrouping(SPLIT_BOLT_ID,new Fields("word")); //WordCountBolt --> ReportBolt。globalGrouping:将WordCountBolt上所有的tuple都发送到唯一的一个ReportBolt实例中。此时并发度失去了意义。 builder.setBolt(REPORT_BOLT_ID,reportBolt).globalGrouping(COUNT_BOLT_ID); Config config = new Config(); LocalCluster cluster = new LocalCluster(); cluster.submitTopology(TOPOLOGY_NAME,config,builder.createTopology()); Utils.waitForSeconds(10); cluster.killTopology(TOPOLOGY_NAME); cluster.shutdown(); } }
输出:
10:16:22.675 [SLOT_1027] INFO com.ebc.blot.ReportBolt:45 - 最终counts
a : 7526
b : 3763
c : 3763
10:16:22.686 [SLOT_1027] INFO com.ebc.blot.ReportBolt:52 - ---------