减少上下文切换的方法有无锁并发编程、CAS算法、使用最少线程和使用协程。 无锁并发编程。多线程竞争锁时,会引起上下文切换,所以多线程处理数据时,可以用一 些办法来避免使用锁,如将数据的ID按照Hash算法取模分段,不同的线程处理不同段的数据。 协程:在单线程里实现多任务的调度,并在单线程里维持多个任务间的切换。 现在我们介绍避免死锁的几个常见方法。 ·避免一个线程同时获取多个锁。 ·避免一个线程在锁内同时占用多个资源,尽量保证每个锁只占用一个资源。 ·尝试使用定时锁,使用lock.tryLock(timeout)来替代使用内部锁机制。 ·对于数据库锁,加锁和解锁必须在一个数据库连接里,否则会出现解锁失败的情况。 硬件资源限 制有带宽的上传/下载速度、硬盘读写速度和CPU的处理速度。软件资源限制有数据库的连接 数和socket连接数等。 Java代码在编译后会变成Java字节码,字节码被类加载器加载到JVM里,JVM执行字节 码,最终需要转化为汇编指令在CPU上执行,Java中所使用的并发机制依赖于JVM的实现和 CPU的指令。 volatile是轻量级的 synchronized,它在多处理器开发中保证了共享变量的“可见性”。可见性的意思是当一个线程 修改一个共享变量时,另外一个线程能读到这个修改的值。如果volatile变量修饰符使用恰当 的话,它比synchronized的使用和执行成本更低,因为它不会引起线程上下文的切换和调度。
x = 10; //语句1
y = x; //语句2
x++; //语句3
x = x + 1; //语句4
咋一看,有些朋友可能会说上面的4个语句中的操作都是原子性操作。其实只有语句1是原子性操作,其他三个语句都不是原子性操作。
语句1是直接将数值10赋值给x,也就是说线程执行这个语句的会直接将数值10写入到工作内存中。
语句2实际上包含2个操作,它先要去读取x的值,再将x的值写入工作内存,虽然读取x的值以及 将x的值写入工作内存 这2个操作都是原子性操作,但是合起来就不是原子性操作了。
同样的,x++和 x = x+1包括3个操作:读取x的值,进行加1操作,写入新的值。
所以上面4个语句只有语句1的操作具备原子性。
也就是说,只有简单的读取、赋值(而且必须是将数字赋值给某个变量,变量之间的相互赋值不是原子操作)才是原子操作。
不过这里有一点需要注意:在32位平台下,对64位数据的读取和赋值是需要通过两个操作来完成的,不能保证其原子性。但是好像在最新的JDK中,JVM已经保证对64位数据的读取和赋值也是原子性操作了。
从上面可以看出,Java内存模型只保证了基本读取和赋值是原子性操作,如果要实现更大范围操作的原子性,可以通过synchronized和Lock来实现。由于synchronized和Lock能够保证任一时刻只有一个线程执行该代码块,那么自然就不存在原子性问题了,从而保证了原子性。
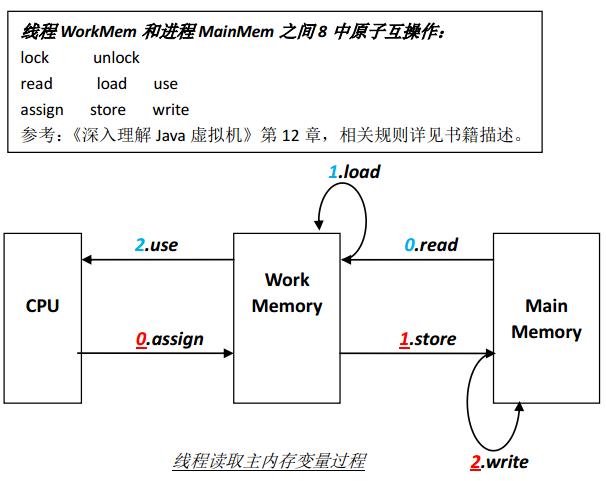
2. 线程独有的工作内存和进程内存(主内存)之间通过8中原子操作来实现,如下图所示:
原子操作的规则(部分):
1) read,load必须连续执行,但是不保证原子性。
2) store,write必须连续执行,但是不保证原子性。
3) 不能丢失变量最后一次assign操作的副本,即遍历最后一次assign的副本必须要回写到MainMemory中。
其它规则详见《深入理解Java虚拟机》第12章 Java内存模型与线程
read(读取) :它把一个变量的值从主内存中传递到工作内存,
load(载入) :赋值给工作内存
store(存储) :把工作内存中的值传递到主内存中来
write(写入) :赋值给主内存
use(使用) :使用工作变量值
assign(赋值) :修改工作变量
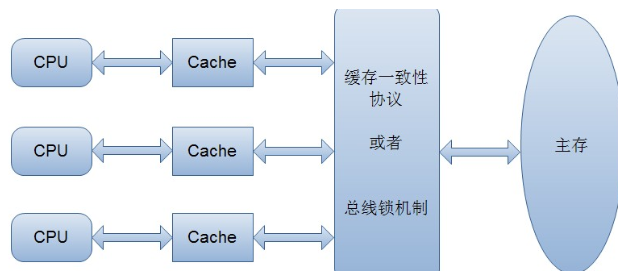
大家都知道,计算机在执行程序时,每条指令都是在CPU中执行的,而执行指令过程中,势必涉及到数据的读取和写入。由于程序运行过程中的临时数据是存放在主存(物理内存)当中的,这时就存在一个问题,由于CPU执行速度很快,而从内存读取数据和向内存写入数据的过程跟CPU执行指令的速度比起来要慢的多,因此如果任何时候对数据的操作都要通过和内存的交互来进行,会大大降低指令执行的速度。因此在CPU里面就有了高速缓存。
也就是,当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU的高速缓存当中,那么CPU进行计算时就可以直接从它的高速缓存读取数据和向其中写入数据,当运算结束之后,再将高速缓存中的数据刷新到主存当中。举个简单的例子,比如下面的这段代码:
i = i + 1;
当线程执行这个语句时,会先从主存当中读取i的值,然后复制一份到高速缓存当中,然后CPU执行指令对i进行加1操作,然后将数据写入高速缓存,最后将高速缓存中i最新的值刷新到主存当中。CPU只跟高速缓存交互。
这个代码在单线程中运行是没有任何问题的,但是在多线程中运行就会有问题了。在多核CPU中,每条线程可能运行于不同的CPU中,因此每个线程运行时有自己的高速缓存(对单核CPU来说,其实也会出现这种问题,只不过是以线程调度的形式来分别执行的)。本文我们以多核CPU为例。
比如同时有2个线程执行这段代码,假如初始时i的值为0,那么我们希望两个线程执行完之后i的值变为2。但是事实会是这样吗?
可能存在下面一种情况:初始时,两个线程分别读取i的值存入各自所在的CPU的高速缓存当中,然后线程1进行加1操作,然后把i的最新值1写入到内存。此时线程2的高速缓存当中i的值还是0,进行加1操作之后,i的值为1,然后线程2把i的值写入内存。
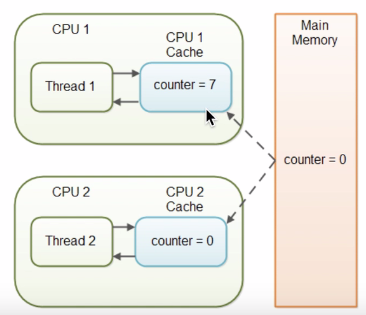
最终结果i的值是1,而不是2。这就是著名的缓存一致性问题。通常称这种被多个线程访问的变量为共享变量。
也就是说,如果一个变量在多个CPU中都存在缓存(一般在多线程编程时才会出现),那么就可能存在缓存不一致的问题。
为了解决缓存不一致性问题,通常来说有以下2种解决方法:
1)通过在总线加LOCK#锁的方式
2)通过缓存一致性协议
这2种方式都是硬件层面上提供的方式。
在早期的CPU当中,是通过在总线上加LOCK#锁的形式来解决缓存不一致的问题。因为CPU和其他部件进行通信都是通过总线来进行的,如果对总线加LOCK#锁的话,也就是说阻塞了其他CPU对其他部件访问(如内存),从而使得只能有一个CPU能使用这个变量的内存。比如上面例子中 如果一个线程在执行 i = i +1,如果在执行这段代码的过程中,在总线上发出了LCOK#锁的信号,那么只有等待这段代码完全执行完毕之后,其他CPU才能从变量i所在的内存读取变量,然后进行相应的操作。这样就解决了缓存不一致的问题。
但是上面的方式会有一个问题,由于在锁住总线期间,其他CPU无法访问内存,导致效率低下。
所以就出现了缓存一致性协议。最出名的就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。(这是没有涉及到java的内存的模型)
i = 9;
假若一个线程执行到这个语句时,我暂且假设为一个32位的变量赋值包括两个过程:为低16位赋值,为高16位赋值。
那么就可能发生一种情况:当将低16位数值写入之后,突然被中断,而此时又有一个线程去读取i的值,那么读取到的就是错误的数据。这就是原子性。
//线程1执行的代码 //线程2执行的代码
int i = 0; j = i;
i = 10;
假若执行线程1的是CPU1,执行线程2的是CPU2。由上面的分析可知,当线程1执行 i =10这句时,会先把i的初始值加载到CPU1的高速缓存中,然后赋值为10,那么在CPU1的高速缓存当中i的值变为10了,却没有立即写入到主存当中。
此时线程2执行 j = i,它会先去主存读取i的值并加载到CPU2的缓存当中,注意此时内存当中i的值还是0,那么就会使得j的值为0,而不是10.
这就是可见性问题,线程1对变量i修改了之后,线程2没有立即看到线程1修改的值。
int i = 0;
boolean flag = false;
i = 1; //语句1
flag = true; //语句2
上面代码定义了一个int型变量,定义了一个boolean类型变量,然后分别对两个变量进行赋值操作。从代码顺序上看,语句1是在语句2前面的,那么JVM在真正执行这段代码的时候会保证语句1一定会在语句2前面执行吗?不一定,为什么呢?这里可能会发生指令重排序(Instruction Reorder)。
下面解释一下什么是指令重排序,一般来说,处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的。单线程下没影响就排序。
比如上面的代码中,语句1和语句2谁先执行对最终的程序结果并没有影响,那么就有可能在执行过程中,语句2先执行而语句1后执行。
但是要注意,虽然处理器会对指令进行重排序,但是它会保证程序最终结果会和代码顺序执行结果相同,那么它靠什么保证的呢?再看下面一个例子:
int a = 10; //语句1
int r = 2; //语句2
a = a + 3; //语句3
r = a*a; //语句4
这段代码有4个语句,那么可能的一个执行顺序是:2134,那么可不可能是这个执行顺序呢: 语句2 语句1 语句4 语句3
不可能,因为处理器在进行重排序时是会考虑指令之间的数据依赖性,如果一个指令Instruction 2必须用到Instruction 1的结果,那么处理器会保证Instruction 1会在Instruction 2之前执行。
虽然重排序不会影响单个线程内程序执行的结果,但是多线程呢?下面看一个例子:
//线程1:
context = loadContext(); //语句1
inited = true; //语句2
//线程2:
while(!inited ){
sleep()
}
doSomethingwithconfig(context);
上面代码中,由于语句1和语句2没有数据依赖性,因此可能会被重排序。假如发生了重排序,在线程1执行过程中先执行语句2,而此是线程2会以为初始化工作已经完成,那么就会跳出while循环,去执行doSomethingwithconfig(context)方法,而此时context并没有被初始化,就会导致程序出错。
从上面可以看出,指令重排序不会影响单个线程的执行,但是会影响到线程并发执行的正确性。
也就是说,要想并发程序正确地执行,必须要保证原子性、可见性以及有序性。只要有一个没有被保证,就有可能会导致程序运行不正确。
三.Java内存模型
Java内存模型规定所有的变量都是存在主存当中(类似于前面说的物理内存),每个线程都有自己的工作内存(类似于前面的高速缓存)。线程对变量的所有操作都必须在工作内存中进行,而不能直接对主存进行操作。并且每个线程不能访问其他线程的工作内存。
举个简单的例子:在java中,执行下面这个语句:i = 10;
执行线程必须先在自己的工作线程中对变量i所在的缓存行进行赋值操作,然后再写入主存当中。而不是直接将数值10写入主存当中。
那么Java语言 本身对 原子性、可见性以及有序性提供了哪些保证呢?
synchronized和Lock保证每个时刻是有一个线程执行同步代码,相当于是单线程执行同步代码,(多线程就是通过单线程解决的)自然就保证了有序性。 另外,Java内存模型具备一些先天的“有序性”,即不需要通过任何手段就能够得到保证的有序性,这个通常也称为 happens-before 原则。如果两个操作的执行次序无法从happens-before(不能重排序的原则)原则推导出来,那么它们就不能保证它们的有序性,虚拟机可以随意地对它们进行重排序。
volatile关键字能保证可见性没有错,但是上面的程序错在没能保证原子性。可见性只能保证每次读取的是最新的值,但是volatile没办法保证对变量的操作的原子性。
CAS实际上是利用处理器提供的CMPXCHG指令实现的,而处理器执行CMPXCHG指令是一个原子性操作。
public class Test {
public volatile int inc = 0;
public void increase() { inc++; }
public static void main(String[] args) {
final Test test = new Test();
for(int i=0;i<10;i++){
new Thread(){
public void run() {
for(int j=0;j<1000;j++)
test.increase();
};
}.start();
}
while(Thread.activeCount()>1) //保证前面的线程都执行完
Thread.yield();
System.out.println(test.inc);
}}
大家想一下这段程序的输出结果是多少?也许有些朋友认为是10000。但是事实上运行它会发现每次运行结果都不一致,都是一个小于10000的数字。
可能有的朋友就会有疑问,不对啊,上面是对变量inc进行自增操作,由于volatile保证了可见性,那么在每个线程中对inc自增完之后,在其他线程中都能看到修改后的值啊,所以有10个线程分别进行了1000次操作,那么最终inc的值应该是1000*10=10000。
这里面就有一个误区了,volatile关键字能保证可见性没有错,但是上面的程序错在没能保证原子性。可见性只能保证每次读取的是最新的值,但是volatile没办法保证对变量的操作的原子性。
在前面已经提到过,自增操作是不具备原子性的,它包括读取变量的原始值、进行加1操作、写入工作内存。那么就是说自增操作的三个子操作可能会分割开执行,就有可能导致下面这种情况出现:
假如某个时刻变量inc的值为10,
线程1对变量进行自增操作,线程1先读取了变量inc的原始值,然后线程1被阻塞了;
然后线程2对变量进行自增操作,线程2也去读取变量inc的原始值,由于线程1只是对变量inc进行读取操作,而没有对变量进行修改操作,所以不会导致线程2的工作内存中缓存变量inc的缓存行无效,所以线程2会直接去主存读取inc的值,发现inc的值时10,然后进行加1操作,并把11写入工作内存,最后写入主存。
然后线程1接着进行加1操作,由于已经读取了inc的值,注意此时在线程1的工作内存中inc的值仍然为10,所以线程1对inc进行加1操作后inc的值为11(是加一操作,不是读取,如果++的三步里面有读取,就会失效,下次访问相同内存地址时就会失效),然后将11写入工作内存,最后写入主存。
那么两个线程分别进行了一次自增操作后,inc只增加了1。
解释到这里,可能有朋友会有疑问,不对啊,前面不是保证一个变量在修改volatile变量时,会让缓存行无效吗?然后其他线程去读就会读到新的值,对,这个没错。这个就是上面的happens-before规则中的volatile变量规则,但是要注意,线程1对变量进行读取操作之后,被阻塞了的话,并没有对inc值进行修改。然后虽然volatile能保证线程2对变量inc的值读取是从内存中读取的,但是线程1没有进行修改,所以线程2根本就不会看到修改的值。
根源就在这里,自增操作不是原子性操作,而且volatile也无法保证对变量的任何操作都是原子性的。x = x + n,就依赖当前值,就不原子。因为读取值之后,卡住了,再次回来时候,不用再次读取值,就不会失效,继续使用旧的错误值。
把上面的代码改成以下任何一种都可以达到效果:
先看一段代码,假如线程1先执行,线程2后执行:
//线程1
boolean stop = false;
while(!stop){
doSomething();
}
//线程2
stop = true;
每个线程在运行过程中都有自己的工作内存,那么线程1在运行的时候,会将stop变量的值拷贝一份放在自己的工作内存当中。
那么当线程2更改了stop变量的值之后,但是还没来得及写入主存当中,线程2转去做其他事情了,那么线程1由于不知道线程2对stop变量的更改,因此还会一直循环下去。
但是用volatile修饰之后就变得不一样了:
第一:使用volatile关键字会强制将修改的值立即写入主存;
第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量stop的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
第三:由于线程1的工作内存中缓存变量stop的缓存行无效,所以线程1再次读取变量stop的值时会去主存读取。
那么在线程2修改stop值时(当然这里包括2个操作,修改线程2工作内存中的值,然后将修改后的值写入内存),会使得线程1的工作内存中缓存变量stop的缓存行无效,然后线程1读取(下次访问相同内存地址时)时,发现自己的缓存行无效,它会等待缓存行对应的主存地址被更新之后,然后去对应的主存读取最新的值。
那么线程1读取到的就是最新的正确的值。
3.volatile能保证有序性吗?
在前面提到volatile关键字能禁止指令重排序,所以volatile能在一定程度上保证有序性。
volatile关键字禁止指令重排序有两层意思:
1)当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见;在其后面的操作肯定还没有进行;
2)在进行指令优化时,不能将在对volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。
可能上面说的比较绕,举个简单的例子:
//x、y为非volatile变量
//flag为volatile变量
x = 2; //语句1
y = 0; //语句2
flag = true; //语句3
x = 4; //语句4
y = -1; //语句5
由于flag变量为volatile变量,那么在进行指令重排序的过程的时候,不会将语句3放到语句1、语句2前面,也不会讲语句3放到语句4、语句5后面。但是要注意语句1和语句2的顺序、语句4和语句5的顺序是不作任何保证的。语句就是栏杆,重排序不能超过这个栏杆。
并且volatile关键字能保证,执行到语句3时,语句1和语句2必定是执行完毕了的,且语句1和语句2的执行结果对语句3、语句4、语句5是可见的。
那么我们回到前面举的一个例子:
//线程1:
context = loadContext(); //语句1
inited = true; //语句2
//线程2:while(!inited ){
sleep()
}doSomethingwithconfig(context);
前面举这个例子的时候,提到有可能语句2会在语句1之前执行,那么久可能导致context还没被初始化,而线程2中就使用未初始化的context去进行操作,导致程序出错。
这里如果用volatile关键字对inited变量进行修饰,就不会出现这种问题了,因为当执行到语句2时,必定能保证context已经初始化完毕。
多线程访问时候,要加volatile,既能保证可见性又能保证不排序,不能保证原子性。
“观察加入volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令”
lock前缀指令实际上相当于一个内存屏障(也成内存栅栏),内存屏障会提供3个功能:
1)它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
2)它会强制将对缓存的修改操作立即写入主存;
3)如果是写操作,它会导致其他CPU中对应的缓存行无效。
而volatile关键字在某些情况下性能要优于synchronized,但是要注意volatile关键字是无法替代synchronized关键字的,因为volatile关键字无法保证操作的原子性。通常来说,使用volatile必须具备以下2个条件:
1)对变量的写操作不依赖于当前值,x = x + n,就依赖当前值,就不原子。因为读取值之后,卡住了,再次回来时候,不用再次读取值,就不会失效,继续使用旧的错误值。
2)该变量没有包含在具有其他变量的不变式中
实际上,这些条件表明,可以被写入 volatile 变量的这些有效值独立于任何程序的状态,包括变量的当前状态。
事实上,我的理解就是上面的2个条件需要保证操作是原子性操作,才能保证使用volatile关键字的程序在并发时能够正确执行。
工作内存中的变量在没有执行过assign修改值操作时,不允许无意义的同步回主内存。
下面列举几个Java中使用volatile的几个场景。
1.状态标记量
volatile boolean flag = false; while(!flag){ doSomething(); } public void setFlag() { flag = true; };
volatile boolean inited = false; //线程1: context = loadContext(); inited = true; //线程2: while(!inited ){ sleep() }doSomethingwithconfig(context);
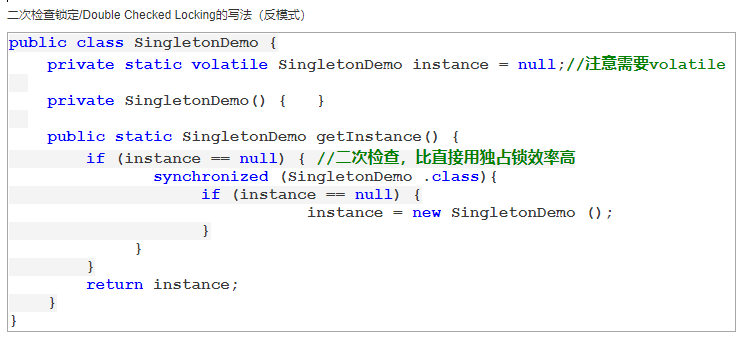
2.double check
class Singleton{ private volatile static Singleton instance = null; private Singleton() { } public static Singleton getInstance() { if(instance==null) { synchronized (Singleton.class) { if(instance==null) instance = new Singleton(); } } return instance; } }
Volatile从来就不是用来保证操作原子性的关键字,他只负责保证可见性和有序性,他的原子性是需要依靠锁来保证的。其实他也有一定的原子性,单个volatile变量的读操作和写操作是具有原子性的,但是一旦拥有多个操作,不再保证原子性。所以Volatile的使用需要你参照具体的场景来使用,并不是什么场景都能用,它是不能替代锁的作用的。之所以称之为轻量级锁,就是因为这个!
cpu指令是原子性的,就不会被打断,i++是3个操作,所以不是原子的,i=3是原子的。
至于为什么线程1的inc没有被更新的原因,我来谈谈自己的看法。
首先要明白volatile的特殊规则“保证了新值能够立即同步到主内存中,以及每次使用前立即从主存中刷新”。注意这个关键词“每次使用前”。非原子性的自增操作的一次使用包括三个步骤:1、inc副本压入操作数栈 2、加1操作 3、弹出操作数栈。只有完成这三步才算是一次使用。当线程1把值为10 的inc读入工作内存中开始使用volatile变量时线程1阻塞,等到线程2成功将inc变为11后,唤醒线程1,此时线程1仍然处于上次使用的过程中,继续完成本次使用,这就是为什么不从主存中更新inc的原因。
而对于原子性操作来说,其一次使用的过程是不会被中断的,对于另一个例子,布尔型变量stop,当线程2将stop置为true,立即更新到主存后,线程1再次使用到stop时便会从主存中刷新。
我的看法是: 因为线程1已经读取到了值, 并把操作数放入了自己的操作数栈中, 此时线程1中断了, CPU由于保存了上次线程1的工作状态, 因此, 轮到线程1工作时, 会继续上次的操作, 即: 开始对操作数栈中的数进行+1操作, 然后立即刷回主存, 因此不再涉及读操作, 否则CPU保存线程的工作状态将毫无意义.
在32位系统中,long和double是采用了高低位两个位置进行操作的。在操作系统级别就需要两个动作才能完成,所以不是原子性的。
volatile修饰的变量,赋值的时候如果是一个动作就多个线程都可以看到更新值(可见性和原子性),如果是多个动作就多个线程不一定都看到更新值。

/** 队列中的头部节点 */ private transient f?inal PaddedAtomicReference<QNode> head; /** 队列中的尾部节点 */ private transient f?inal PaddedAtomicReference<QNode> tail; static f?inal class PaddedAtomicReference <T> extends AtomicReference T> { // 使用很多4个字节的引用追加到64个字节 Object p0, p1, p2, p3, p4, p5, p6, p7, p8, p9, pa, pb, pc, pd, pe; PaddedAtomicReference(T r) { super(r); } } public class AtomicReference <V> implements java.io.Serializable { private volatile V value; // 省略其他代码 }
追加字节能优化性能?这种方式看起来很神奇,但如果深入理解处理器架构就能理解其
中的奥秘。让我们先来看看LinkedTransferQueue这个类,它使用一个内部类类型来定义队列的
头节点(head)和尾节点(tail),而这个内部类PaddedAtomicReference相对于父类
AtomicReference只做了一件事情,就是将共享变量追加到64字节。我们可以来计算下,一个对
象的引用占4个字节,它追加了15个变量(共占60个字节),再加上父类的value变量,一共64个
字节。
为什么追加64字节能够提高并发编程的效率呢?因为对于英特尔酷睿i7、酷睿、Atom和
NetBurst,以及Core Solo和Pentium M处理器的L1、L2或L3缓存的高速缓存行是64个字节宽,不
支持部分填充缓存行,这意味着,如果队列的头节点和尾节点都不足64字节的话,处理器会将
它们都读到同一个高速缓存行中,在多处理器下每个处理器都会缓存同样的头、尾节点,当一
个处理器试图修改头节点时,会将整个缓存行锁定,那么在缓存一致性机制的作用下,会导致
其他处理器不能访问自己高速缓存中的尾节点,而队列的入队和出队操作则需要不停修改头
节点和尾节点,所以在多处理器的情况下将会严重影响到队列的入队和出队效率。Doug lea使
用追加到64字节的方式来填满高速缓冲区的缓存行,避免头节点和尾节点加载到同一个缓存
行,使头、尾节点在修改时不会互相锁定。(锁定就是锁定一行64字节,头尾节点在一行之后,操作头节点会锁定这一行,那么其他处理器就不能操作尾节点)
那么是不是在使用volatile变量时都应该追加到64字节呢?不是的。在两种场景下不应该
使用这种方式。
--缓存行非64字节宽的处理器。如P6系列和奔腾处理器,它们的L1和L2高速缓存行是32个
字节宽。
--共享变量不会被频繁地写。因为使用追加字节的方式需要处理器读取更多的字节到高速
缓冲区,这本身就会带来一定的性能消耗,如果共享变量不被频繁写的话,锁的几率也非常
小,就没必要通过追加字节的方式来避免相互锁定。
不过这种追加字节的方式在Java 7 可能不生效,因为Java 7变得更加智慧,它会淘汰或
重新排列无用字段,需要使用其他追加字节的方式。除了volatile,Java并发编程中应用较多的
是synchronized,下面一起来看一下。
因为它会锁住总线,导致其他CPU不能访问总线,不能访问总线就意味着不能访问系统内
存。







只要两个指令之间不存在数据依赖,就可以对这两个指令乱序。不必关心数据依赖的精确定义,可以理解为:只要不影响程序单线程、顺序执行的结果,就可以对两个指令重排序。
public class OutofOrderExecution { private static int x = 0, y = 0; private static int a = 0, b = 0; public static void main(String[] args) throws InterruptedException { Thread t1 = new Thread(new Runnable() { public void run() { a = 1; x = b; } }); Thread t2 = new Thread(new Runnable() { public void run() { b = 1; y = a; } }); t1.start(); t2.start(); t1.join(); t2.join(); System.out.println(“(” + x + “,” + y + “)”); } }

public class MutableInteger { private int value; public int get(){ return value; } public void set(int value){ this.value = value; } }

class Singleton { private static Singleton instance; private Singleton(){} public static Singleton getInstance() { if (instance == null) { // 这里存在竞态条件 instance = new Singleton(); } return instance; } 竞态条件会导致instance引用被多次赋值,使用户得到两个不同的单例。
class Singleton { private static Singleton instance; public int f1 = 1; // 触发部分初始化问题 public int f2 = 2; private Singleton(){} public static Singleton getInstance() { if (instance == null) { // 当instance不为null时,可能指向一个“被部分初始化的对象” synchronized (Singleton.class) { if ( instance == null ) { instance = new Singleton(); } } } return instance; } }






在多线程的环境下,如果某个线程首次读取共享变量,则首先到主内存中获取该变量,然后存入工作内存中,以后只需要在工作内存中读取该变量即可。同样如果对该变量执行了修改的操作,则先将新值写入工作内存中,然后再刷新至主内存中。但是什么时候最新的值会被刷新至主内存中是不太确定的,这也就解释了为什么VolatileFoo中的Reader线程始终无法获取到init_value最新的变化。
· 使用关键字volatile,当一个变量被volatile关键字修饰时,对于共享资源的读操作会直接在主内存中进行(当然也会缓存到工作内存中,当其他线程对该共享资源进行了修改,则会导致当前线程在工作内存中的共享资源失效,所以必须从主内存中再次获取),对于共享资源的写操作当然是先要修改工作内存,但是修改结束后会立刻将其刷新到主内存中。
· 通过synchronized关键字能够保证可见性,synchronized关键字能够保证同一时刻只有一个线程获得锁,然后执行同步方法,并且还会确保在锁释放之前,会将对变量的修改刷新到主内存当中。
· 通过JUC提供的显式锁Lock也能够保证可见性,Lock的lock方法能够保证在同一时 刻只有一个线程获得锁然后执行同步方法,并且会确保在锁释放(Lock的unlock方法)之前会将对变量的修改刷新到主内存当中。
CAS其非阻塞性,它对死锁问题天生免疫,就是不使用锁。没有锁的概念。
两个线程同时使用一个共享变量,会在Cache中缓存该变量,当一个线程修改共享变量时,Cache未能及时将修改的值放回RAM,导致另一个线程不能读取修改后的值。
volatile关键字的作用:用来保证对变量修改后,能立即写回主存,从而保证共享变量的修改对所有线程是可见的。






public class LinkedQueue <E> { private static class Node <E> { final E item; final AtomicReference<Node<E>> next; Node(E item, Node<E> next) { this.item = item; this.next = new AtomicReference<Node<E>>(next); } } private AtomicReference<Node<E>> head = new AtomicReference<Node<E>>(new Node<E>(null, null)); private AtomicReference<Node<E>> tail = head; public boolean put(E item) { Node<E> newNode = new Node<E>(item, null); while (true) { Node<E> curTail = tail.get(); Node<E> residue = curTail.next.get(); if (curTail == tail.get()) {//暂停了,下次从来 if (residue == null) /* A */ {//暂停了,下次从来 if (curTail.next.compareAndSet(null, newNode)) /* C */ {//暂停了,下次从来 tail.compareAndSet(curTail, newNode) /* D */ ;//暂停了,下次从来 return true; } } else { tail.compareAndSet(curTail, residue) /* B */;//帮助别人做 } } } } }