1 如果两个对象相同,那么它们的hashCode值一定要相同。也告诉我们重写equals方法,一定要重写
hashCode方法,同一个对象那么hashcode就是同一个(同一个对象什么都是相同的)。
2 如果两个对象的hashCode相同,它们并不一定相同,这里的对象相同指的是用eqauls方法比较。
Object类中hashCode()方法的声明如下:
Object类中hashCode()方法的声明如下:
1 public native int hashCode();
可以看出,hashCode()是一个native方法,而且返回值类型是整形;实际上,该native方法将对象在内存中的地址作为哈希码返回,可以保证不同对象的返回值不同。
2、hashCode()的作用
总的来说,hashCode()在哈希表中起作用,如HashSet、HashMap等。
当我们向哈希表(如HashSet、HashMap等)中添加对象object时,首先调用hashCode()方法计算object的哈希码,通过哈希码可以直接定位object在哈希表中的位置(一般是哈希码对哈希表大小取余)。如果该位置没有对象,可以直接将object插入该位置;如果该位置有对象(可能有多个,通过链表实现),则调用equals()方法比较这些对象与object是否相等,如果相等,则不需要保存object;如果不相等,则将该对象加入到链表中。
这也就解释了为什么equals()相等,则hashCode()必须相等。如果两个对象equals()相等,则它们在哈希表(如HashSet、HashMap等)中只应该出现一次;如果hashCode()不相等,那么它们会被散列到哈希表的不同位置,哈希表中出现了不止一次。
实际上,在JVM中,加载的对象在内存中包括三部分:对象头、实例数据、填充。其中,对象头包括指向对象所属类型的指针和MarkWord,而MarkWord中除了包含对象的GC分代年龄信息、加锁状态信息外,还包括了对象的hashcode;对象实例数据是对象真正存储的有效信息;填充部分仅起到占位符的作用, 原因是HotSpot要求对象起始地址必须是8字节的整数倍。
hashcode:返回值是int值,并且每次运行的结果不一样,可以理解为内存编号,便于CPU 快速查找。当
然自己可以去重写hashcode方法,但是要保证每个对象的hashcode值不一样,如果一样,那么CPU查找这
个对象的时候就会出错。
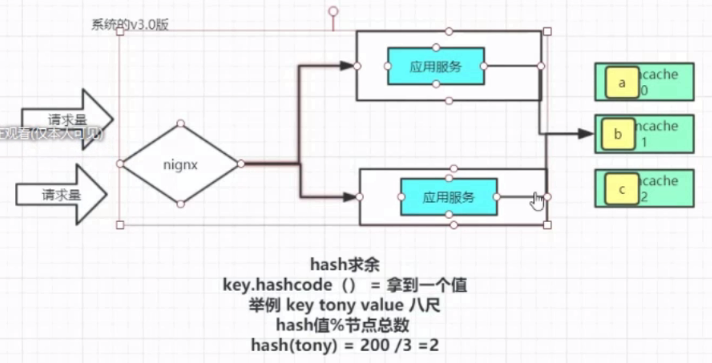
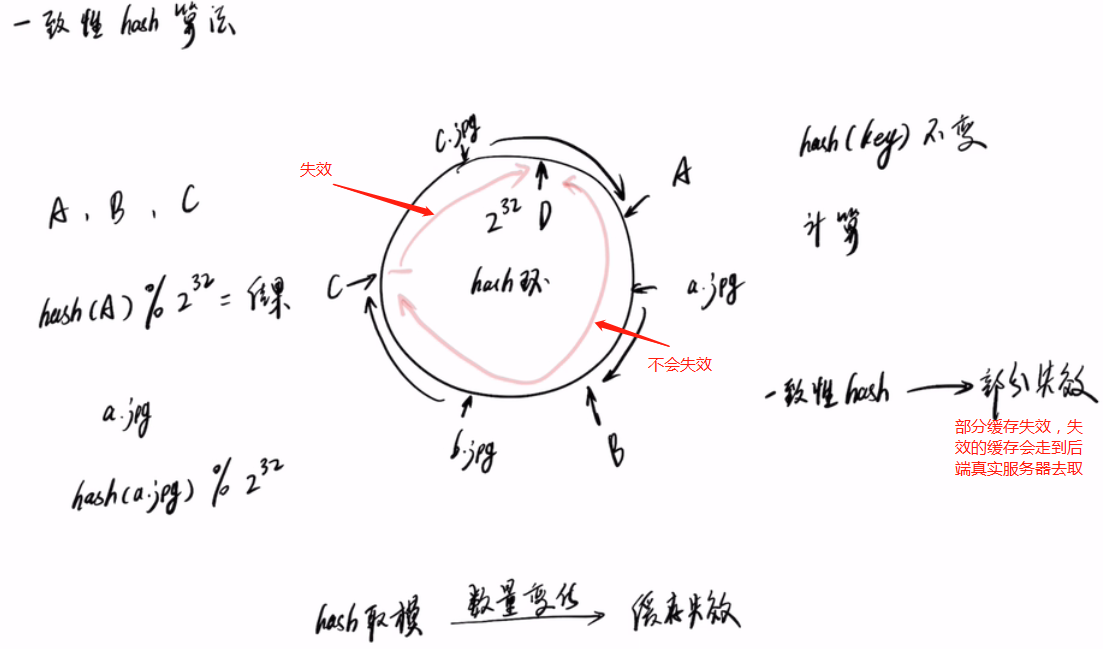
一致性hash 算法

int型占4个字节,有32位,所以有2^31-1个,即2147483647。因为我们这里用的是int值来标识位置信息,所以环的长度是Interger的最大值。否则会覆盖。
原来ACB3个机器,现在增加D这个机器。缓存失效也只有部分缓存失效。失效的缓存将会在后端真实服务器去取。
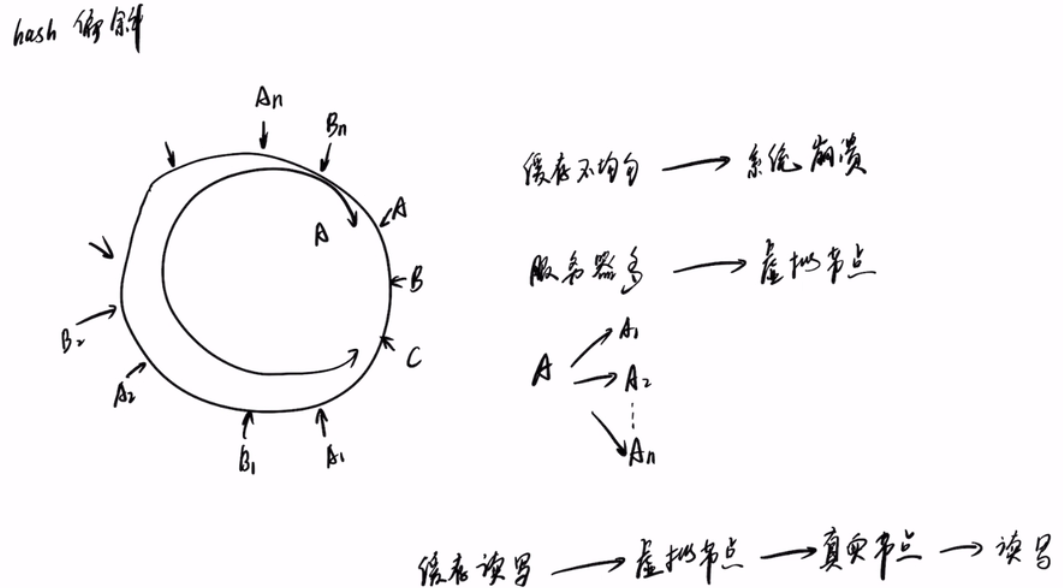
hash倾斜:会导致ABC3台机器在环上分配不均匀,那么所有的数据都在机器A上,当缓存失效的时候会有大量数据失效,从而加重后端非缓存机器的崩溃,所以可以在环上加很多虚礼节点,A加点虚拟出A1 A2 A3 ...,数据读写的时候,先算出虚礼节点的位置,然后找到真实节点,在把数据放入真实节点进行读写。虚礼节点也会跟真实节点碰撞。