概率密度函数(PDF)
以高斯分布的概率密度函数(PDF)为例,
(f(x)=frac{1}{sigmasqrt{2pi}} e^{-frac{1}{2}left(frac{x - mu}{sigma}
ight)^2})
期望值(mu)和方差(sigma)确定之后,(f(x))是(x)的PDF函数。更一般地, (f(x))可以认为是(x)和( heta(mu, sigma))的函数,
(f(x; heta)=frac{1}{sigmasqrt{2pi}} e^{-frac{1}{2}left(frac{x - mu}{sigma}
ight)^2})
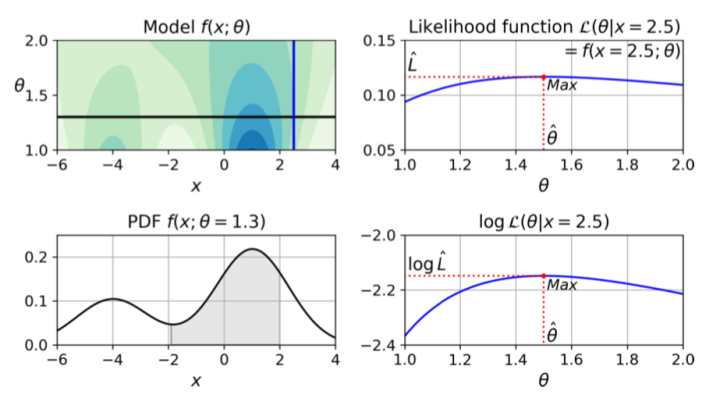
最大似然估计(maximum likelihood estimation)
现已知数据集 (x={x_0, x_1, x_2, ...}) ,求使得 (f(x)) 最大化的参数 ( heta),此时 (f(x; heta)) 是模型参数 ( heta) 的函数,
(
f( heta)=frac{1}{sigmasqrt{2pi}} e^{-frac{1}{2}left(frac{x - mu}{sigma}
ight)^2}
)
在所有 ( heta) 的可能取值中,最大似然估计求解使得 (f( heta)) 最大化的参数值 (hat{ heta})
用大神Aurélien书里的一张图来总结一下: