查询出的原始数据:
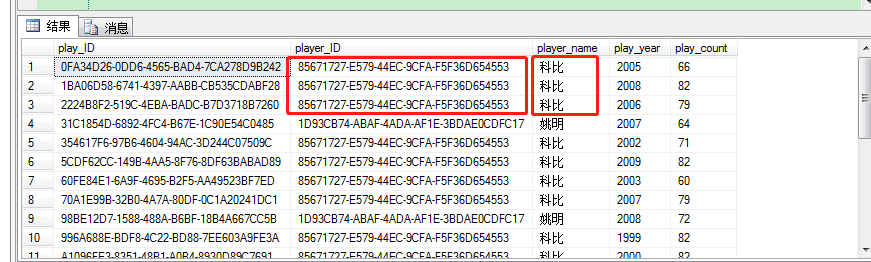
可以看出,标红的两列有大量的重复数据,而我们需要的最终效果如下图所示:
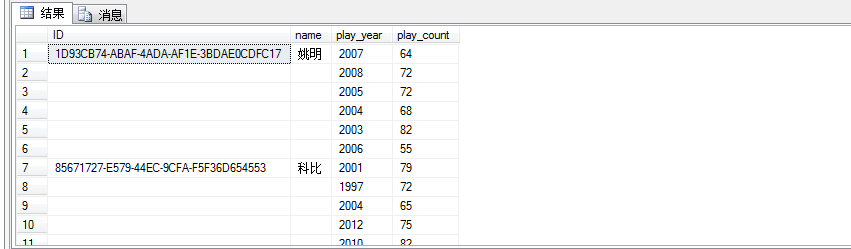
具体的实现,先上SQL吧:
1 with cte as( 2 select rid=row_number() over (partition by player_ID,a.player_name order by player_name),* from playinfo_demo1 a 3 ) 4 select 5 CASE when rid=1 then ltrim(player_ID) else '' END AS ID, 6 CASE when rid=1 then ltrim(player_name) else '' END AS name, 7 play_year,play_count FROM cte
在 SQL Server 数据库中,为咱们提供了一个函数 row_number() 用于给数据库表中的记录进行标号,在使用的时候,其后还跟着一个函数 over(),而函数 over() 的作用是将表中的记录进行分组和排序。两者使用的语法为:
意为:将表中的记录按字段 COLUMN1进行分组,按字段 COLUMN2 进行排序,其中
PARTITION BY:表示分组ORDER BY:表示排序
1 SELECT player_ID,player_name,play_year,play_count,rid = ROW_NUMBER() OVER(PARTITION BY player_ID ORDER BY player_name) FROM playinfo_demo1
上述SQL语句就是按照 player_ID进行了分组,然后按照player_name 进行了排序,因此运行结果如下所示:
