创建kafka容器:
docker run -itd --name centos-kafka4 --network=host mykafka3 /bin/bash
1、安装kafka
安装包的修改配置文件server.properties
broker.id=0 listeners=PLAINTEXT://172.19.0.5:9092 zookeeper.connect=172.19.0.4:2181,172.19.0.5:2181,172.19.0.6:2181/kafka
启动kafka
./kafka-server-start.sh ../config/server.properties
查询kafka进程值:jps -l
查询kafka打开的文件描述符 : ls /proc/31/fd | wc -l
2、创建topic
./kafka-topics.sh --zookeeper 172.19.0.2:2181,172.19.0.3:2181,172.19.0.4:2181/kafka --create --topic yhqtopic --partitions 1 --replication-factor 1
3、生产者与消费者
./kafka-console-producer.sh --broker-list 172.19.0.5:9092 --topic yhqtopic
./kafka-console-consumer.sh --bootstrap-server 172.19.0.5:9092 --topic yhqtopic
4、防火墙相关
systemctl status firewalld 查看防火墙状态
systemctl stop firewalld 关闭防火墙
systemctl disable firewalld 永久关闭防火墙
5、理论知识
kafka通过多副本机制来实现集群的高可用和高可靠,每个分区都会有一至多个副本,每个副本都分别存放在不同的broker节点上,并且只有leader副本对外提供服务。
元数据是指 Kafka 集群的元数据,这些元数据具体记录了集群中有哪些主题,这些主题有哪些分区,每个分区的 lead 副本分配在哪个节点上, follower 副本分配在哪些节点上,哪些副本在 AR ISR 等集合中,集群中有哪些节点,控制器节点又是哪一个等信息。
某些应用顺序性非常重要 ,比如 MySQL binlog 输,如果出现错误就会造成非常严重的后果,如果将 acks 参数配置为非零值,并且 max.in.flight.requests.per.connection 参数 配置为大于0的值,那么就会出现错序的现象 如果第一批次消息写入失败 而第二批次消息 写入成功,那么生产者会重试发送第一批次的消息, 此时如果第一批次的消息写入成功,那么 这两个批次的消息就出现了错序。在需要保证消息顺序的场合建议把参数 max.in.flight.requests.per.connection 配置为 1,而不是把 acks 配置为0 这样也会影响整体的吞吐。
要启用幂等性,只需要将 Producer 的参数中 enable.idompotence 设置为 true 即可。Kafka的幂等性实现其实就是将原来下游需要做的去重放在了数据上游。开启幂等性的 Producer 在初始化的时候会被分配一个 PID,发往同一 Partition 的消息会附带 Sequence Number。而Broker 端会对<PID, Partition, SeqNumber>做缓存,当具有相同主键的消息提交时,Broker 只会持久化一条。 但是 PID 重启就会变化,同时不同的 Partition 也具有不同主键,所以幂等性无法保证跨分区跨会话的 Exactly Once
Kafka 从 0.11 版本开始引入了事务支持。事务可以保证 Kafka 在 Exactly Once 语义的基础上,生产和消费可以跨分区和会话,要么全部成功,要么全部失败。 为了实现跨分区跨会话的事务,需要引入一个全局唯一的 Transaction ID,并将 Producer获得的PID和Transaction ID绑定。这样当Producer重启后就可以通过正在进行的Transaction ID 获得原来的 PID。
对于消息在分区中的位置 offset 称为“偏移量” 对于消费者消费到的位置,将 offset 称为“位移 ,有时候也会更明确地称 之为“消费位移”。
https://www.cnblogs.com/luckyhui28/category/1608573.html
6、kafka主题
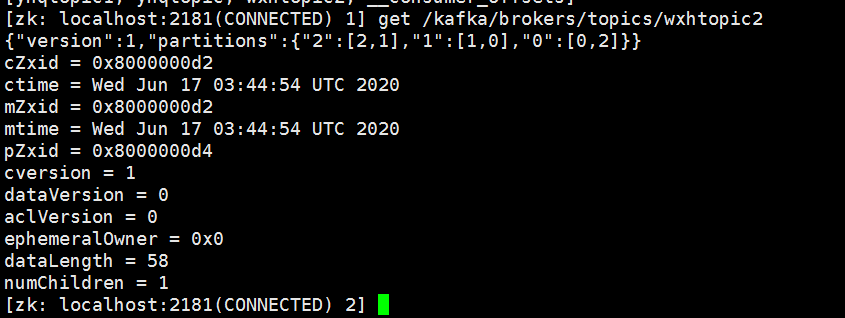
kafka-topics.sh --zookeeper 172.19.0.2:2181,172.19.0.3:2181,172.19.0.4:2181/kafka --describe --topic wxhtopic2

如果此时把 broker id为1的机器停掉,则使得0号节点成为1号分区的leader,长此以往,会导致负载失衡。kafka引入优先副本的概念,优先副本的选举是指通过一定方式促使优先副本选举为leader副本,以此来促进集群的负载均衡。

./kafka-preferred-replica-election.sh --zookeeper 172.19.0.2:2181,172.19.0.3:2181,172.19.0.4:2181/kafka
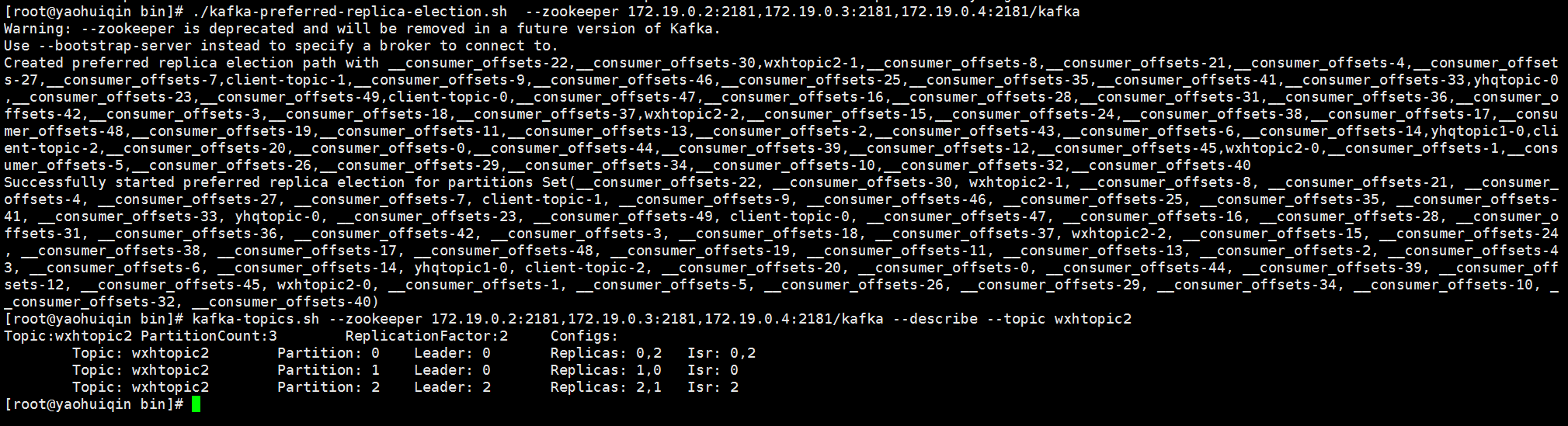
kafka3,kafka4,kafka5是不同的容器,容器内运行的kafka,其配置的broker.id分别为0,1,2, wxhtopic是创建的主题,对应3个分区,2个副本,3台机器
kafka5 wxhtopic2-2 wxhtopic2-0 kafka4 wxhtopic2-2 wxhtopic2-1 kafka3 wxhtopic2-0 wxhtopic2-1 partition = 0 leader = kafka3 replicas = kafka3 kafka5 partition = 1 leader = kafka4 replicas = kafka4 kafka3 partition = 2 leader = kafka5 replicas = kafka5 kafka4
7、压测
kafka-producer-perf-test.sh --topic yhqtopic --num-records 10000 --record-size 1024 --throughput -1 --producer-props bootstrap.servers=192.168.146.196:9095 acks=1
kafka-consumer-perf-test.sh --topic yhqtopic --messages 100000 --broker-list 192.168.146.196:9094
8、日志
kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.log
kafka-dump-log.sh --files 00000000000000000000.index
9、磁盘存储
顺序写入速度是随机写入速度的6000倍,甚至比随机写内存的速度快。
页缓存:当一个进程读取磁盘文件内容时,如果在页缓存中存在,则直接返回数据,避免IO操作,如果没有命中,则系统向磁盘发起IO请求,并将读取数据的数据页存入页缓存,之后再将数据返回给进程。同样,如果一个进程需要将数据写入磁盘,如果不命中,则在也缓存中添加响应的页并写入数据。被修改的数据变成了脏页,操作系统会在合适的时间把脏数据写入磁盘以保持数据的一致性。
因此,使用文件系统的顺序写入并依赖页缓存的做法明显优于维护进程内存缓存或其他结构。即使kafka服务重启,页缓存还是会保持有效,然而进程内的缓存却需要重建。kafka大量使用页缓存是kafka实现高吞吐的重要因素,虽然消息是先被写入页缓存,然后由操作系统负责具体的刷新任务,但是kafka中同样提供了同步刷盘及间断性强刷盘的功能来提高可靠性(不建议,多副本机制即可保证可靠性)
除了消息顺序追加、页缓存等技术,Kafka还使用零拷贝(Zero-Copy)技术来进一步提升性能。所谓的零拷贝是指将数据直接从磁盘文件复制到网卡设备中,而不需要经由应用程序之手。零拷贝大大提高了应用程序的性能,减少了内核和用户模式之间的上下文切换。对 Linux操作系统而言,零拷贝技术依赖于底层的 sendfile()方法实现。对应于 Java 语言,FileChannal.transferTo()方法的底层实现就是sendfile()方法。
零拷贝(Zero-copy)技术指在计算机执行操作时,CPU 不需要先将数据从一个内存区域复制到另一个内存区域,从而可以减少上下文切换以及 CPU 的拷贝时间。
实现零拷贝用到的最主要技术是 DMA 数据传输技术和内存区域映射技术:
- 零拷贝机制可以减少数据在内核缓冲区和用户进程缓冲区之间反复的 I/O 拷贝操作。
- 零拷贝机制可以减少用户进程地址空间和内核地址空间之间因为上下文切换而带来的 CPU 开销。
10、时间轮
Kafka存在大量延时操作,比如延时生产、延时拉取和延时删除等。JDK中Timer和DelayQueue的插入和删除的平均时间复杂度为O(nlogn)并不能满足kafka高性能的要求。而基于时间轮可以将插入和删除操作的时间复杂度都降为O(1)
11、消费组管理
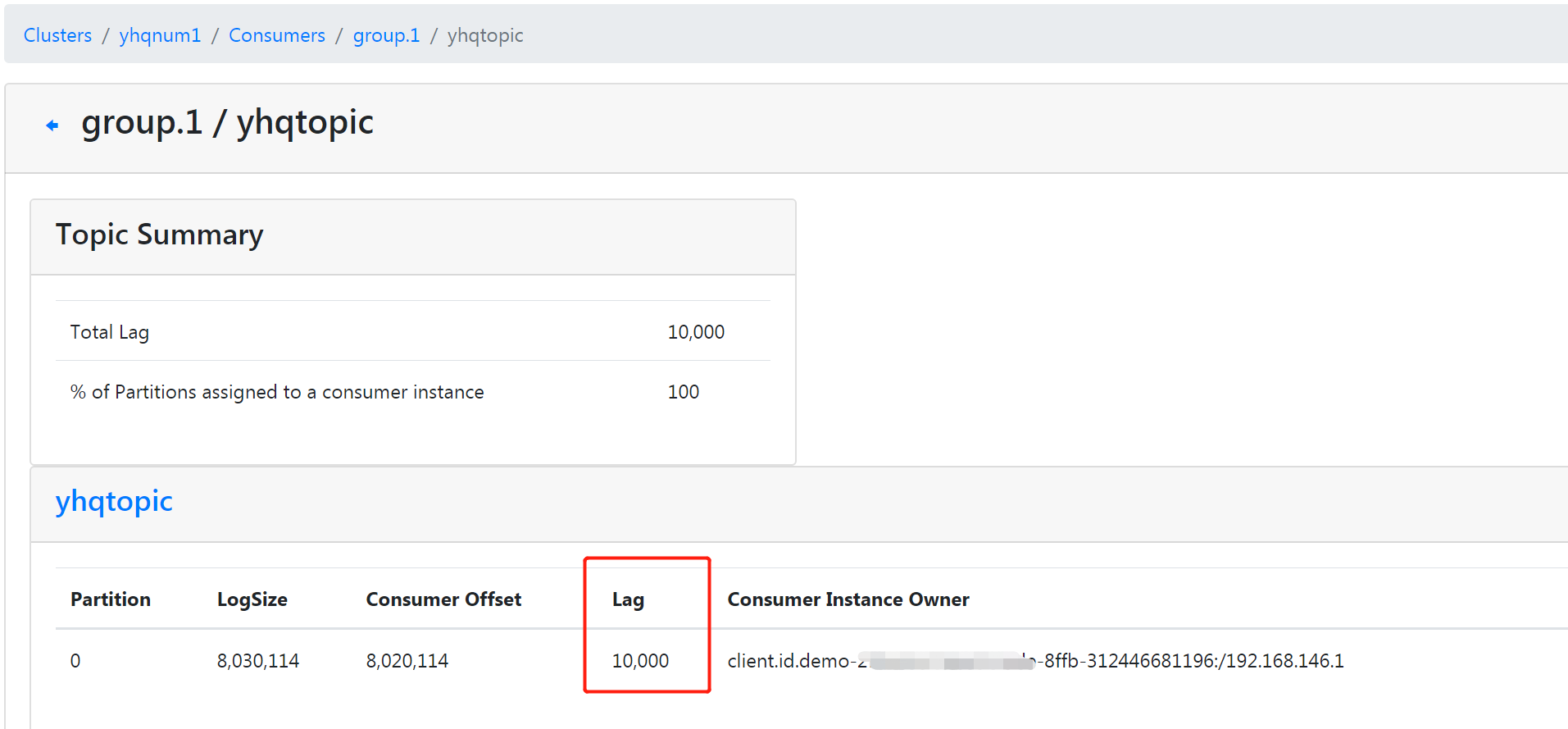
kafka-consumer-groups.sh --bootstrap-server 192.168.146.200:9092 --describe --group group.1

注意:这里有一个消费滞后的概念,即LAG,LAG=(log-end-offset ) - (current-offset)
12 安装kafka监控 kafka manager
https://blog.csdn.net/dengjili/article/details/99495760
编辑vim conf/application.conf
kafka-manager.zkhosts="172.19.0.2:2181,172.19.0.3:2181,172.19.0.4:2181/kafka"
执行命令:./kafka-manager -Dconfig.file=../conf/application.conf 默认端口号9000
添加cluster:
查看消费滞后lag:
查看同步失效分区,wxhtopic有三个分区,3个broker。关闭其中一个broker上的kafka:

13、高级应用
过期时间(TTL)
延时队列
优先级队列
死信队列和重试队列
死信队列:由于某些原因消息无法正确地投递,为了确保消息不会被无故丢弃,一般将其置于死信队列。这里的死信可以看做消费者不能处理的消息或不符合处理要求的消息。
回退队列:如果消费者在消费时发生了异常,那么就不会对这一次消费进行确认,进而发生回滚消息的操作之后,消息始终会放在队列的顶部,然后不断被处理和回滚,导致队列陷入死循环。为解决这个问题,可以为每个队列设置一个回退队列。
消费轨迹:消息轨迹指的是一条消息从生产者发出,经由broker存储,再到消费者消费的整个过程中,各个相关节点的状态时间地点等数据汇聚而成的完整链路信息。
消费审计是指在消费生产、存储和消费的整个过程之间对消费个数以及延迟的审计,以此来检测是否有数据丢失,是否有数据重复,端到端的延迟又是多少等内容。
消费模式:消息模式分为push和pull,推模式是指由broker主动推送消息至消费端,实时性较好,不过需要一定的流控机制来确保broker推送过来的消息不会压垮消费端,而拉模式实时性较差,但是可以根据自身的处理能力控制拉取的消息量。
回溯消费:消息在消费完成之后,还能消费之前被消费的消息。
消费堆积+持久化:流量削峰是消息中间件一个非常重要的功能,这得益于消息堆积能力。消费堆积分内存式堆积和磁盘式堆积。Rabbit是典型的内存式堆积,但在某些条件触发后会有幻夜动作来将内存消息换页到磁盘,或者直接使用惰性队列来将消息直接持久化到磁盘中。kafka是典型的磁盘式堆积。
流量控制:发送方和消费方速度不匹配,流量控制提供一种速度匹配服务来抑制发送速度,接收方应用程序的读取速度与之相适应。通常的流量控制方法:stop-and-wait,滑动窗口和令牌桶。
14、消息中间件比较
性能:一般kafka单机QPS在十万甚至百万,但RabbitMQ在万级别内
可靠性:kafka采用类似于PacificA的一致性协议,通过ISR(In-Sync-Replica)来保证多副本之间的同步,并且支持强一致性。 RabbitMQ通过镜像环形队列实现多副本及强一致性。
目前,在金融支付领域使用RabbitMq居多,而在日志处理、大数据等方面Kafka使用居多。