df_1 = pd.DataFrame({'A': [0, 1, 2], 'B': [3, 4, 5]})
print df_1

默认左边行index0往上递增,AB为顶部标识,数组内为内容
loc——通过行标签索引行数据
iloc——通过行号索引行数据
iloc比较简单,它是基于索引位来选取数据集,0:4就是选取 0,1,2,3这四行,需要注意的是这里是前闭后开集合(注意:是取多行,','是取单个元素)
Column为行名字,index为列名字
用index可以取列ridership_df[['R003', 'R005']]
df = pd.DataFrame({'A': [0, 1, 2], 'B': [3, 4, 5]})
print df.sum()

python中,axis通常有3个值:-1,0,1,分别表示:默认,列,行
df.values.sum() //全部元素相加
df.sum(axis=1)//行元素相加
df.sum()//默认是
dataFram之间的相互操作
df1 = pd.DataFrame({'a': [1, 2, 3], 'b': [4, 5, 6], 'c': [7, 8, 9]})
df2 = pd.DataFrame({'a': [10, 20, 30], 'b': [40, 50, 60], 'c': [70, 80, 90]})
print df1
print df1 + df2

if True:
df1 = pd.DataFrame({'a': [1, 2, 3], 'b': [4, 5, 6], 'c': [7, 8, 9]})
df2 = pd.DataFrame({'d': [10, 20, 30], 'c': [40, 50, 60], 'b': [70, 80, 90]})
print df1 + df2
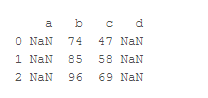 (不相符为NAN,但是见过有办法保留原始数据,但是具体方法还需再去查找下)
(不相符为NAN,但是见过有办法保留原始数据,但是具体方法还需再去查找下)
df1 = pd.DataFrame({'a': [1, 2, 3], 'b': [4, 5, 6], 'c': [7, 8, 9]},
index=['row1', 'row2', 'row3'])
df2 = pd.DataFrame({'a': [10, 20, 30], 'b': [40, 50, 60], 'c': [70, 80, 90]},
index=['row4', 'row3', 'row2'])
print df1 + df2
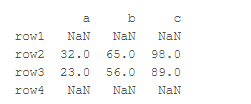 (列不同的情况下,不一样的列会默认为NaN)
(列不同的情况下,不一样的列会默认为NaN)
DataFrame函数的使用,
df = pd.DataFrame({
'a': [1, 2, 3],
'b': [10, 20, 30],
'c': [5, 10, 15]
})