1
先拷贝tar包到目录底下(tar 包解压 tar zxvf)
2 :
1、使用课程提供的hadoop-2.5.0-cdh5.3.6.tar.gz,上传到虚拟机的/usr/local目录下。(http://archive.cloudera.com/cdh5/cdh/5/)
2、将hadoop包进行解压缩:tar -zxvf hadoop-2.5.0-cdh5.3.6.tar.gz
3、对hadoop目录进行重命名:mv hadoop-2.5.0-cdh5.3.6 hadoop
4、配置hadoop相关环境变量
vi ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bashrc
5、创建/usr/local/data目录(用来存放data目录)
3:配置core-site
(dir/hadoop/etc/hadoop/)
<property>
<name>fs.default.name</name>
<value>hdfs://sparkproject1:9000</value>
</property>
4:配置hdfs-site.xml
<property>
<name>dfs.name.dir</name>
<value>/usr/local/data/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/data/datanode</value>
</property>
<property>
<name>dfs.tmp.dir</name>
<value>/usr/local/data/tmp</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
4.配置map-site.xml(mapreduce配置)
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
5.修改yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>sparkproject1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
6:scp -r hadoop root@sparkproject2:/usr/local/soft
用scp命令把hadoop文件scp到别的机器上
7:把bashrc也拷贝到别的机器上
scp ~/.bashrc root@sparkproject2:~/
(同理拷贝到别的机器上)
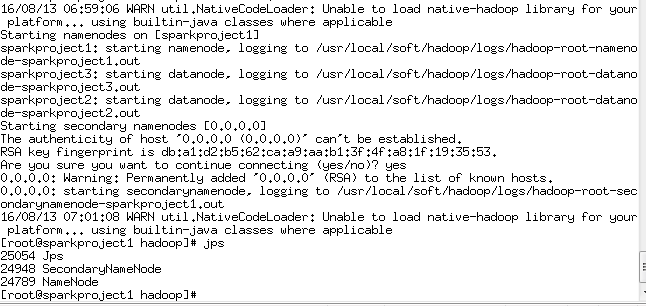
8:hdfs格式化
1、格式化namenode:在sparkproject1上执行以下命令,hdfs namenode -format
9:start-dfs.sh (yes)