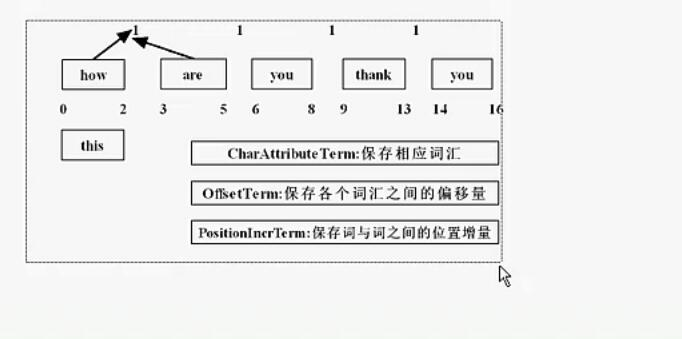
在Lucene中很多数据是通过Attribute进行存储的
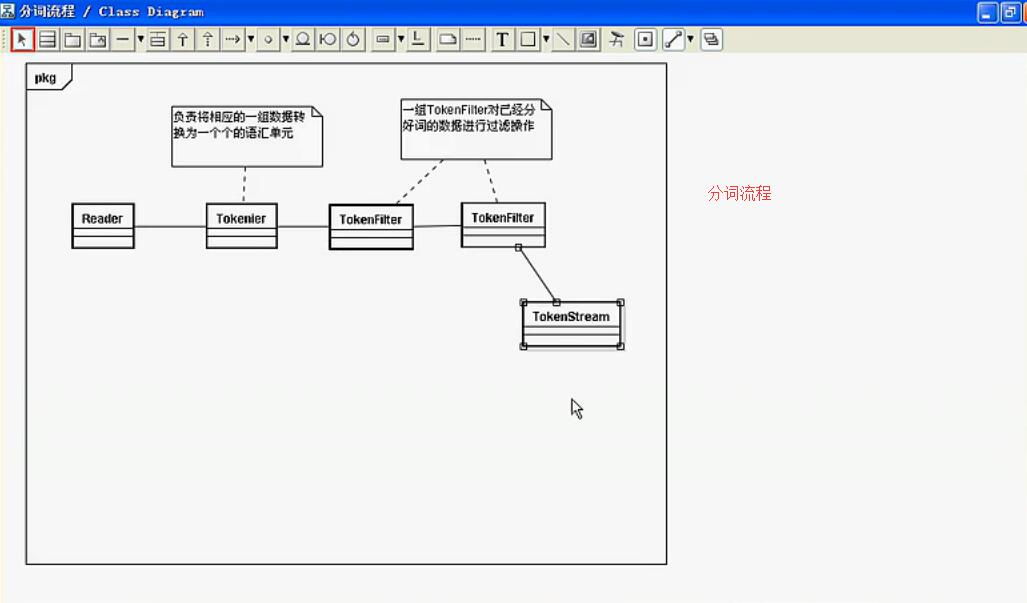
步骤是同过TokenStrem获取文本信息流
TokenStream stream = a.tokenStream("content", new StringReader(str)); (a:指的是Analyzer)
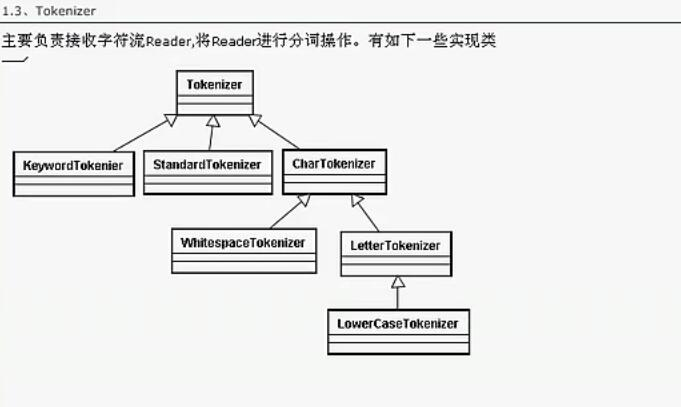
而在这里对这个由不同的分词的话之需要实现Analyer,并重写里面的tokenStream 方法
public TokenStream tokenStream(String fieldName, Reader reader) {
Dictionary dic = Dictionary.getInstance("F:\CheckOut\Lucene\03_lucene_analyzer\mmseg4j-1.8.4\data");
return new MySameTokenFilter(new MMSegTokenizer(new MaxWordSeg(dic), reader),samewordContext);
}
然后这里获取他的Tokenizer 并可以实现自己的过滤器,以及相应的同义词删减
public class MySameTokenFilter extends TokenFilter{ private CharTermAttribute cta = null; private PositionIncrementAttribute pia = null; private AttributeSource.State current = null; private Stack<String> sames = null; private SamewordContext samewordContext; protected MySameTokenFilter(TokenStream input,SamewordContext samewordContext) { super(input); cta = this.addAttribute(CharTermAttribute.class); pia = this.addAttribute(PositionIncrementAttribute.class); sames = new Stack<String>(); this.samewordContext=samewordContext; } /** * 思想如下: * 其实每个同义词都要放在CharTermAttribute里面,但是如果直接cta.append("大陆");的话 * 那会直接把原来的词和同义词连接在同一个语汇单元里面[中国大陆],这样是不行的 * 要的是这样的效果[中国][大陆] * 那么就要在遇到同义词的时候把当前的状态保存一份,并把同义词的数组放入栈中, * 这样在下一个语汇单元的时候判断同义词数组是否为空,不为空的话把之前的保存的一份状态 * 还原,然后在修改之前状态的值cta.setEmpty(),然后在把同义词的值加入cta.append("大陆") * 再把位置增量设为0,pia.setPositionIncrement(0),这样的话就表示是同义词, * 接着把该同义词的语汇单元返回 */ @Override public boolean incrementToken() throws IOException { System.out.println("yaobo"); while(sames.size() > 0){ //将元素出栈,并获取这个同义词 String str = sames.pop(); //还原状态 restoreState(current); cta.setEmpty(); cta.append(str); //设置位置 pia.setPositionIncrement(0); return true; } if(!input.incrementToken()) return false; if(addSames(cta.toString())){ //如果有同义词将当前状态先保存 current = captureState(); } return true; } /* * 使用这种方式是不行的,这种会把的结果是[中国]替换成了[大陆] * 而不是变成了[中国][大陆] @Override public boolean incrementToken() throws IOException { if(!input.incrementToken()) return false; if(cta.toString().equals("中国")){ cta.setEmpty(); cta.append("大陆"); } return true; } */ private boolean addSames(String name){ String[] sws = samewordContext.getSamewords(name); if(sws != null){ for(String s : sws){ sames.push(s); } return true; } return false; } }
其思想如下


然后通过不同的Attribute进行分割
TokenStream stream = a.tokenStream("content", new StringReader(str));
//位置增量
PositionIncrementAttribute pia = stream.addAttribute(PositionIncrementAttribute.class);
//偏移量
OffsetAttribute oa = stream.addAttribute(OffsetAttribute.class);
//词元
CharTermAttribute cta = stream.addAttribute(CharTermAttribute.class);
//分词的类型
TypeAttribute ta = stream.addAttribute(TypeAttribute.class);