以前面试的时候,碰到过一个问题。函数的调用过程是怎样的?
听到问题的时候有点懵,这算是问题吗。马上胡乱诌了一通。说完以后面试官看我的表情 ﹁_﹁。
多年以后看到了一些文章,发现应该从汇编角度解释这个问题,更容易理解。值得记下来。
函数调用过程需要用函数调用栈来解释。函数调用栈是程序运行时一段连续的内存区域,栈是后进先出的数据结构。
内存的生长方向是从低地址向高地址,而栈是相反的,从高地址向低地址。压栈时栈顶地址变小,退栈时栈顶地址变大。
总的来说函数调用过程如下图:
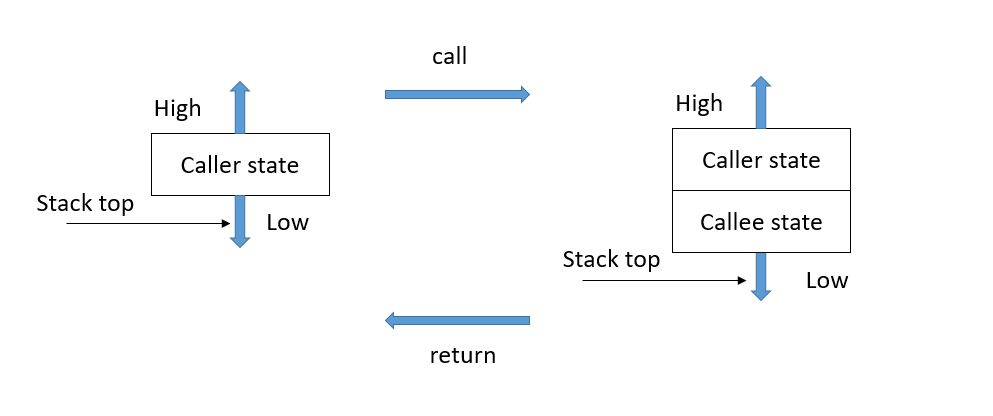
函数调用时,先将主调函数(Caller)的状态信息压入栈中,再将被调函数(Callee)的状态压入栈中。
Callee函数执行完毕,Callee信息退栈,Caller信息退栈,这样程序回到调用之前的位置,继续执行后面的语句。
如果用汇编来理解。则会有恍然大悟的感觉。上学的时候的汇编没学好,只记得一点,汇编是跟寄存器打交道的底层编程语言。
函数的调用过程涉及到3个寄存器。
EBP(Base Point):基地址寄存器,记录当前函数状态的基地址。
ESP(Stack Point):栈顶寄存器,记录函数调用栈的栈顶地址,压栈和出栈时变化。压栈esp-4,退栈esp+4
EIP:记录即将执行的指令的地址。
简单写一段代码,完成一个简单的加法功能。
#include <iostream> int fun(int a, int b) { return a + b; } int main() { int c = fun(1, 2); return 0; }
在vs里调试时按Alt + 8看到汇编代码:
int fun(int a, int b) { 01261700 push ebp ;ebp压栈,记录Caller函数状态的基地址(step 3) 01261701 mov ebp,esp ;esp的内容放入ebp,此时ebp,esp都指向栈顶(step 4) 01261703 sub esp,0C0h ;函数内部操作开始 01261709 push ebx 0126170A push esi 0126170B push edi 0126170C lea edi,[ebp-0C0h] 01261712 mov ecx,30h 01261717 mov eax,0CCCCCCCCh 0126171C rep stos dword ptr es:[edi] return a + b; 0126171E mov eax,dword ptr [a] 01261721 add eax,dword ptr [b] } 01261724 pop edi 01261725 pop esi 01261726 pop ebx ;函数内部操作结束 01261727 mov esp,ebp ;栈顶回到函数执行基地址(step 5) 01261729 pop ebp ;ebp退栈,ebp回到Caller函数状态的基地址(step 5) 0126172A ret ;返回地址退栈,存到eip中,跳转返回地址(step 6) int c = fun(1, 2); 0126175E push 2 ;参数2压栈(step 1) 01261760 push 1 ;参数1压栈(step 1) 01261762 call fun (01261154h) ;调用函数fun,返回地址压栈,跳转函数地址(step 2) 01261767 add esp,8 0126176A mov dword ptr [c],eax
只将函数调用栈相关的汇编代码部分作了注解。可以看到函数调用分为6个步骤:
1.将Caller的参数逆序压栈。
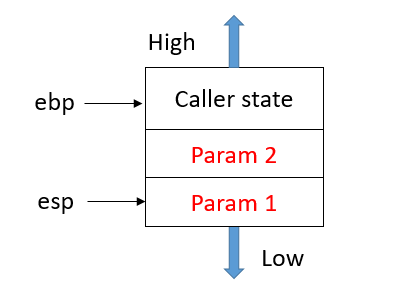
2.将Caller的返回地址压栈
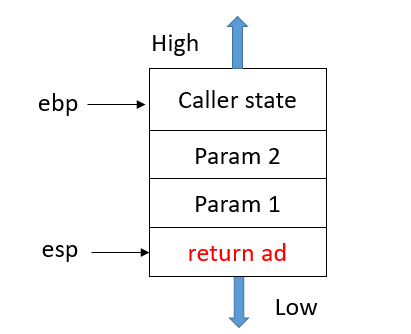
3.将Caller的状态基地址ebp压栈
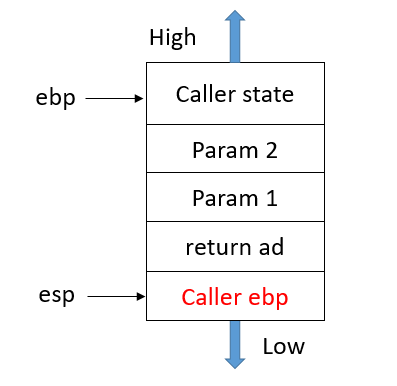
4.ebp指向esp,将esp的值放入ebp,使得ebp,esp指向栈顶
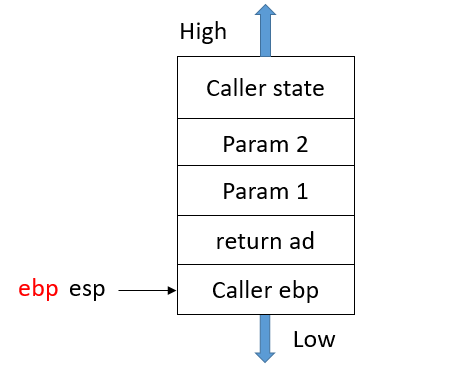
5.函数内部操作结束之后,esp回到ebp,将ebp退栈,值放到ebp里,这样ebp回到Caller的基地址位置
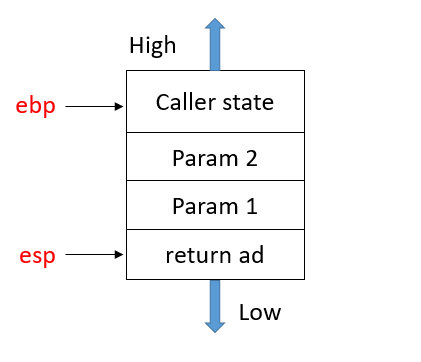
6.再将返回地址退栈,放到epi里,这样回到Caller状态全部恢复,继续执行以后的语句。

函数调用栈大约是这么个过程。图是为了加深理解,我自己画的。大家可以看下面引用里画的图。
引用:
https://zhuanlan.zhihu.com/p/25816426
http://blog.csdn.net/zsJum/article/details/6117043