source data 我们称为源域,通常源域数据量很大;
target data 我们称为目标域,通常数据量很小;
迁移学习是把 在 源域 上学到的东西 迁移到 目标域上;
迁移学习不仅可以用于 监督学习,也可以用于无监督学习;

保守训练
预训练的模型是非常经典的模型,大数据集下得到的泛化能力很强的模型;
迁移学习通常 数据量 较小,如果过分训练很容易过拟合;
保守训练的思想是我还是相信一个权威的模型,只允许你在这个模型上做些许的变动,不允许大幅度改变模型;
通常的做法是 保证 训练后的参数和预训练的参数 差距不大; 【只是一种思路,你可以脑洞大开】
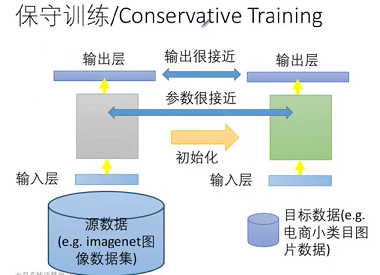
可在 loss function 上添加约束 loss + λ[(w1-w1')^2 + ... (wn-wn')^2] λ 正则化系数
layer 层迁移
这是最常用的做法,我们常说的 finetune 就是这个;
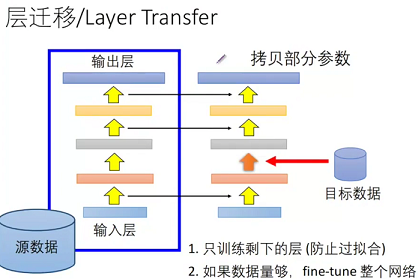
层迁移有个问题:迁移哪些层?这根据任务来确定

多任务学习
多任务学习是指多个任务同时学习,使得一套参数可以完成多个任务;
有很多这样的场景,比如:
1. 在目标检测中,基于共同的卷积 完成 分类 和 检测的 任务;
2. 两个分类任务,一个是判断是不是狗,一个是判断是不是狼,由于狗的样本很多,狼的样本很少,我可以先训练狗的模型,然后 层迁移到 狼的网络进行 finetune,
也可以 同时训练,loss = 狗 loss + 狼 loss,这样做或许可以避免 狼的样本少,造成过拟合;
训练完之后,我可以分开使用;结果可能是 狗的模型比单独训练差点,但是狼的模型比单独训练好很多;而我们的目标是狼的模型;
多任务学习的重点在于 多任务 loss;
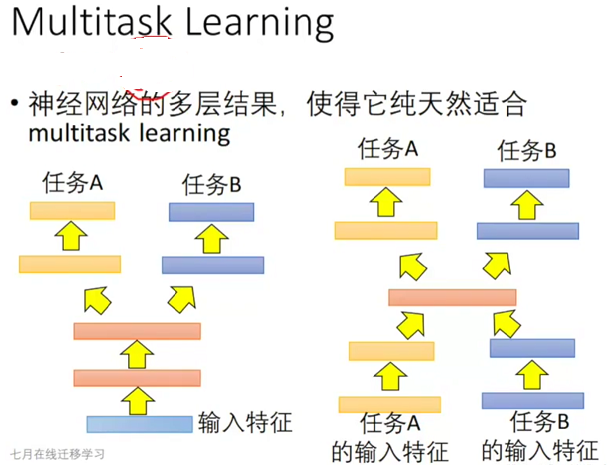
多任务学习已经在语因识别领域有一定应用

渐进式学习
随着任务的越来越困难,比如先训练一个 是不是狗的模型,又训练一个 狗与 狼的模型,又训练一个不同品种的狗的模型;
第一个模型相对容易训练,在训练第二个模型时,我们可以把 第一个模型的特征加到第二个模型上,可能有助于学到更好的特征;

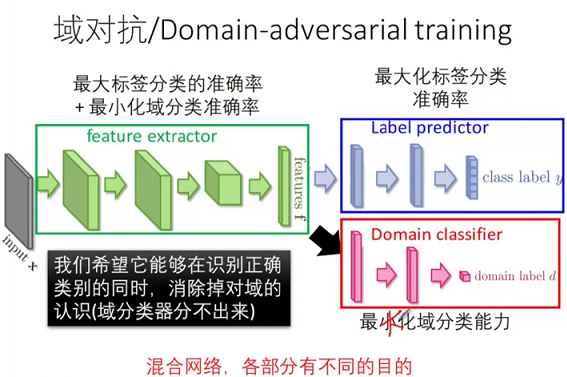
域对抗
这种情况针对 目标域 没有 标签的情况,如下图

黑白色的手写数字是有标签的 源域;
彩色并有一定噪声的手写数字是目标域,目标域没有标签;
我们的目标是得到一个模型能够识别 目标域;
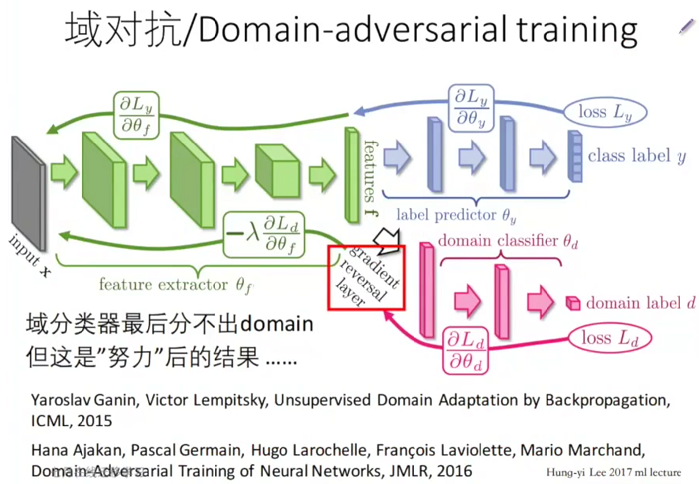
这是一个对抗网络,
上路是对输入进行分类,类别为 0123456789,输入是源域,
下路是对输入来源进行分类,类别为来源于 源域 还是 目标域,输入是源域和目标域,
在训练时,二者交替训练,先训练几次上路,然后固定上路,训练下路,依次进行,
网络的思想是得到一种特征,使得 网络无法判断他来源于 源域还是目标域,而且能准确分类,
对抗的思想体现在,网络希望通过特征 来识别 输入来源于 源域还是目标域,但同时又希望 识别不出来,注意,在我们得到 loss Ld 时,我们反向传播来减小 loss 使得 我们可以区分来源,但是传播时我们又把 梯度乘以 -1,使得本身希望可以区分来源变成区分不了来源,当区分不了来源时,源域和目标域就得到了公共特征,从而在源域上表现不错的分类器也可以用于目标域;
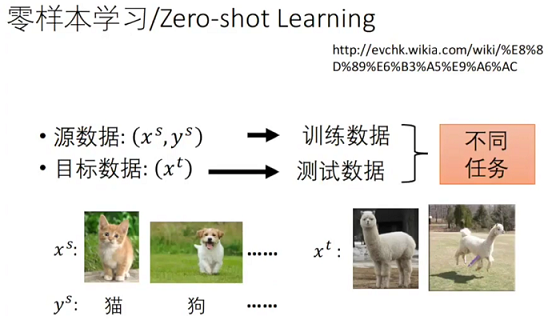
零样本学习-zero shot
除了 zero shot,还有 one shot,few shot,这里以 zero shot 为例进行讲解;
zero shot 不同于上面的迁移学习,
上面的迁移学习都是学习一个 新的分类器 用于 独立的 目标域上,也就是说 源域和目标域相互独立,各有各的分类器;
而 zero shot 是 目标域 也包含在 源域里,他们是一个任务,学习一个分类器,即可识别源域,也可以识别目标域;
如 源域是 人,label 是男女,目标域是鬼,显然没有样本,但 分类器依然能够识别男女;
或者如下图, 源域是 猫狗,label 是动物名称,目标域是一种不知道是啥的动物,没见过,依然能够识别,哪怕是随便起个名字呢,比如 草泥马,但不是猫,也不是狗;
这种情况比较少见,我大致介绍下解决方法,有几种方式
1. 猫狗 我们从像素和形状的角度进行识别,是否可以换一种 角度 去识别呢,比如 属性 角度:几只眼睛、几条腿等

chimp,猩猩,毛茸茸,2条腿,没尾巴;
dog,狗,毛茸茸,4条腿,有尾巴;
这样 就可以 识别 草泥马了,当然有可能识别为 马,但是总比识别成狗强;

2. 对输出做加权平均,这种处理方式其实不是很正式的迁移学习;
他是把 输出 多个目标的概率做加权平均,如下图
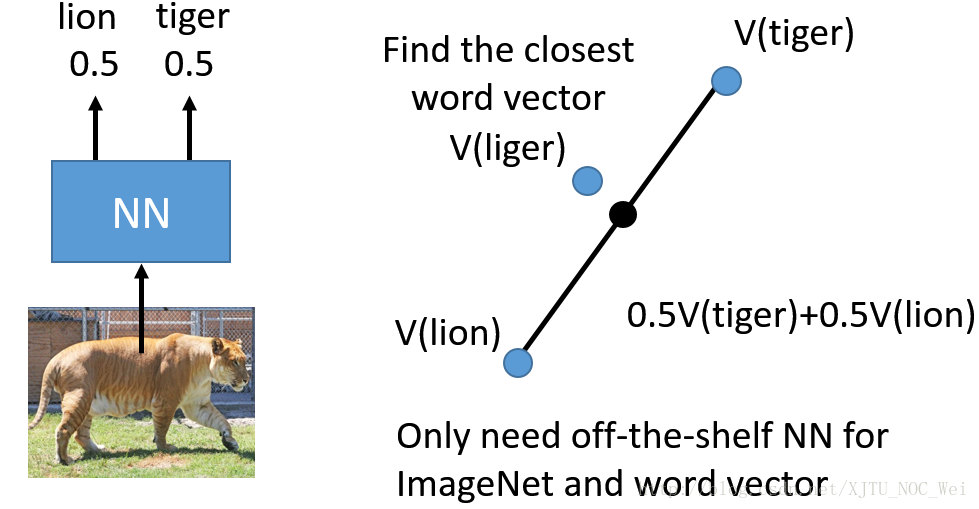
网络输出 50% 是老虎, 50% 是狮子,加权平均后得到一种 狮虎兽;
总结
迁移学习,transform learning 是一个大学科,内容很多,且研究空间很大,是未来的发展方向,后面会继续学习...
参考资料:
https://blog.csdn.net/XJTU_NOC_Wei/article/details/77850221?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task