Yolo v2 论文名称 Yolo9000:Better,Faster,Stronger
该论文实际上包含了2个模型,Yolov2 和 Yolo9000,Yolo v2 是在 Yolo v1 基础上进行了改进, 此外作者提出了一种 检测和分类 的联合训练方法,并用该方法在 COCO 检测数据集 和 ImageNet 分类数据集上训练 Yolo v2,把得到的模型称为 Yolo9000,其可以预测超过 9000 类物体
Yolo v2 改进策略
Yolo v1 虽然速度很快,但与 R-CNN 系列相比,它的 mAP 相对较低,且 定位 精度 和 召回率也较低;
Yolo v2 在保证速度的前提下,提出了如下改进措施,明显提高了 mAP,且 定位 精度和 recall 也有提高

可以看到 mAP 从 63 提高到了 78
Yolo v2 算法的逻辑同 Yolo v1,也是 分为多个 cell, 每个 cell 生成 bbox,然后回归,本文只讲述不同点
Batch Normalize
BN 我在其他博客详细阐述过;
在 Yolo v2 中增加了 BN,去掉了 Dropout,使得:
收敛更快:使得梯度保持在合理范围,避免梯度消失
收敛效果更好:以 relu 为例,BN 把输出规范到 0-1 附近,小于 0 的神经元被归 0,相当于弃掉该神经元,Dropout,避免过拟合
mAP 提高 2.4%
主网络
Yolo v1 的主网络是 GoogleNet,Yolo v2 的主网络是作者自己设计,称为 Darknet-19,包括19个卷积层和5个 max pooling 层,
网络结构类似于 VGG16,主要采用 3x3 卷积,每次 2x2 max pooling 后,feature map 的尺寸降低 2倍, channels 增加2 倍,
与 NIN (network in network)类似,最后采用 globel avgpool 做预测,
在 3x3 的卷积之间,加上 1x1 的卷积压缩特征图,以降低参数量,
卷积层后面加上了 BN 层,
Darknet-19的top-1准确度为72.9%,top-5准确度为91.2%,但是模型参数相对小一些,
使用Darknet-19之后,YOLOv2的mAP值没有显著提升,但是计算量却可以减少约33%

作者用这个网络是为了更快,自己可以更换
passthrough 检测细粒度特征
这是一种类似于 resnet 的设计;
目标检测的难点是目标有大有小,在经过多层卷积后,特征图中小目标的特征已经不明显甚至被忽略,
为了更好地识别较小的目标,在最后的特征图中加上更细粒度的特征是有必要的,
Yolo v2 引入了 passthrough 层保留细粒度特征,如下图

在最后一个 max pooling 之前,假设feature map 大小为 26x26x512,
然后经过 max pooling,变为 13x13x512,后面经过连续卷积,变为 13x13x1024,
然后把 26x26 加到 13x13 的 feature map 上,最终得到 13x13x3072 的 feature map
那么问题来了,不同的卷积池化层的输出尺寸肯定不同,如何相加呢?方式如下
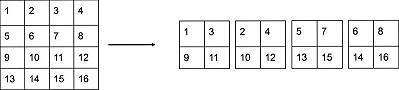
另外,作者在后期的实现中借鉴了ResNet网络,不是直接对高分辨特征图处理,而是增加了一个中间卷积层,先采用64个 卷积核进行卷积,然后再进行passthrough处理,这样
的特征图得到
的特征图。这算是实现上的一个小细节。
使用Fine-Grained Features之后YOLOv2的性能有1%的提升
全卷积网络 支持 多尺度输入
在 Yolo v1 中,输入只能是 448x448,因为后面有全连接层,所以输入尺寸固定;
在 Yolo v2 中,使用卷积层替代了全连接层,使得输入尺寸可变;
注意,全卷积不同尺寸输入的输出尺寸也不同;【思考如何处理?】
此外,在 Yolo v2 中,如果输入是 448,需要 resize 为 416x416,为什么呢?
作者发现,很多图像中的大物体的中心都落在图像的中心,【想象一下,不难明白】
而 Yolo v2 进过下采样的步长为 32,448 经过 32 的下采样为 14x14,这样图像的中心为 4 个 cell,用4个cell 来预测物体显然不合适,
416 经过 32 的下采样为 13x13,这样图像的中心为 1 个 cell,1个 cell 预测物体比较合适;
故输入尺寸需遵循原则:使得 32 下采样后 卷积尺寸为 奇数
引入 anchor box
Yolo v2 借鉴了 Faster R-CNN 中 anchor box(先验框)的思路,事先设定了 多个(num) 不同 大小和 宽高比的建议框,每个 cell 生成 num 个 bbox,,这大大增加了 bbox 和 可预测物体的数量,13x13x9=1521,动辄上千,作者这样做的结果是 recall 大幅增加,但 mAP 略微下降;

================ 扩展 ================
recall 增加,mAP 降低
在 Yolo v1 中,每个 cell 生成 2 个 bbox,且只有一个 bbox 负责为 cell 预测,这使得模型最多预测 49 个物体,造成 recall 很低;
Yolo v2 生成大量的 bbox,能框到更多的物体,召回率就高了,由 81% 升到 88%,框了更多的物体,自然更容易出错,mAP 下降
Yolo v2 anchor box 与 Yolo v1 bbox 输出
1. Yolo v1 中每个 cell 的 bbox 共享分类概率值,Yolo v2 中每个 cell 的每个 bbox 都对应各自的分类概率值;
换句话说,v1 中每个 cell 预测一个物体,v2 中每个 bbox 预测一个物体;
(x,y,w,h,c) 输出无差异;
Dimension Cluster
在 Yolo v1 中,bbox 是虚拟的,利用回归生成;
在 Faster R-CNN 中,人为设定 anchor box 的尺寸;【见上图】
在 Yolo v2 中,anchor box 也是预先设定,只是具体宽高比通过 KMeans 生成; 【anchor 没有 center,只有 w h】
这么做是为了选择更合适的先验框,使得模型更容易学习,从而做出更好的预测;
具体做法如下,把训练集中所有的 ground truth 进行 KMeans 聚类,正常情况下,KMeans 聚类以距离来衡量,此处聚类是为了找出常用的建议框尺寸,故作者以 IOU 作为衡量标准

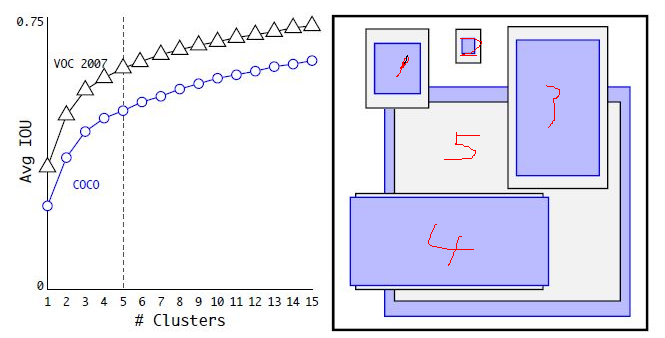
上图左边为对 VOC 数据集和 COCO 数据集的建议框分别聚类结果,
【随着 k 的增加,每个类别的 建议框 与 其平均建议框 的 IOU 逐渐增大,这句话是官方给出的,个人觉得没用】
随着 k 的增加,每个 cell 生成的 bbox 增加,recall 会增加,但是模型复杂度也会增加,综合考虑了 recall 和 复杂度,作者选择 k=5
预测边框的位置
所有手动生成 建议框 的位置预测都是对 建议框的中心做平移,对建议框的宽高做拉伸,只是各个算法的公式略有不同;
Faster-RCNN 计算公式如下

xa,ya 是建议框的中心,wa,ha 是建议框的宽高,x,y 是预测框中心,tx,ty 是需要学习的参数;
在 Yolo 论文中,是 -xa,但是根据 Faster-RCNN 应该是 +xa;
这个公式在问题在于,t 没有任何约束,使得 x,y 即预测框可能在图像的任意位置,如果初始预测框与 anchor box 偏移太大,就会导致很难学习到 tx,ty,或者说学习不稳定;
在 Yolo v2 中添加了约束,使得 预测框的中心 被限定在 建议框中心所在的 cell 中,
如下图所示,虚线 p 为 建议框,蓝色 cell 为 p 中心所在的 cell,蓝色框为 预测框,Yolo v2 的约束保证 蓝色框的中心 在 蓝色 cell 内;
如何做到的呢?
设 cx,cy 是 蓝色 cell 左上角到图像左上角的距离,那么 cx 加上一个 小于 cell 边长的数就能保证得到的坐标在 蓝色 cell 内,即 cx+w*cell边长,0<w<1
Yolo v2 中把 cell 大小归一化为 1x1,用 func(t) 代替 w,使得 0<func(t)<1,很明显,sigmoid 就可以;
故 Yolo v2 计算公式如下

bx,by,bw,bh 是预测框的中心和宽高,Pr(object)*IOU(b,object) 为预测框的置信度,t 为 模型输出;
在 Yolo v1 中用 C 表示置信度,是根据 loss 直接预测的;Yolo v2 需要对 t0 进行 sigmoid 变换
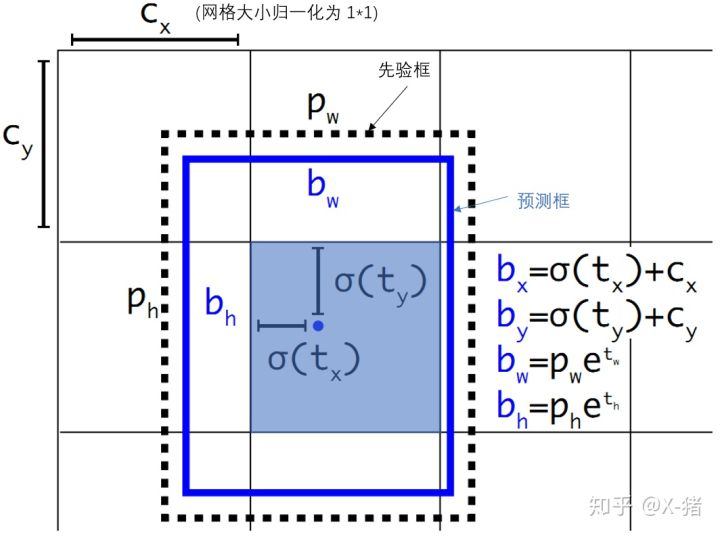
这样做使得预测框 与 先验框不会偏离太大,容易学习,学习快,准确度也更高;
当然这样做得益于 Yolo 系列对图像进行了划分,RCNN 系列是没有的;
由于 cell 归一化为 1,那么 feature map 大小为 W,H,如13,13,下面我们需要计算 bx,by 相对于 feature map 的位置




然后 拿 bx 乘以整个图像的像素值如 448x448,就得到了 图像上的 实际位置
采用 高分辨率 图像分类模型
目标检测任务一般都会在 ImageNet 1000 数据集上预训练 CNN 网络进行特征提取,其输入为 224x224,这个分辨率较低,不利于目标检测,
在 Yolo v1 中,将输入 resize 为 448x448,提高分辨率,但是这样直接切换分辨率,模型可能难以快速适应高分辨率;
在 Yolo v2 中,预训练阶段增加了 10 个 epochs,采用 448x448 输入来 finetune CNN 网络,这使得在用 检测数据 finetune 之前模型已经适应了 高分辨率,
mAP 提升了约 4%
多尺度训练
Yolo v2 是全卷积网络,支持多尺度输入,为了让模型能够适应多尺度输入,在训练时也采用多尺度训练,具体做法如下:
由于 Yolo v2 是 32 位下采样,故作者选择 32 的整数倍 [320,352,...608] 多个尺寸作为模型输入,每 10 个 batch 就随机更换一种尺寸,

Loss
论文中并没有明确指出 Yolo v2 的 loss function,网上大多是这么写的

公式解析:
W 为最终 feature map 的宽度;H 为最终 feature map 的高度,如 (13,13);
A 为每个 cell 的 anchor box 数,论文中为 5;每个 anchor box 对应一个 预测框;
三个求和 代表 遍历每个 cell 的每个 预测框,
lmax_iou<Thresh 表示对于每个 预测框,计算它与所有 Ground Truth 的 IOU,并取最大的 IOU,如果 Max IOU < Thresh,表示它与所有 Ground Thresh 都不匹配,这个预测框就定义为背景,即没有目标, 【论文中 Thresh=0.6】
如果是背景,lmax_iou<Thresh 为 1,否则为 0,
b 表示预测框的置信度,真实的背景置信度为 0,误差就是 (0-b)^2,
第一项表示背景的置信度误差;
lt<12800 表示前 12800 次迭代,12800 次后面的迭代不纳入计算,
Σr€(x,y,w,h) 表示 遍历 x,y,w,h,求和,
prior 表示 anchor box,b 表示 预测框,
第二项表示在前 12800 次迭代中 计算 预测框与先验框的位置偏差,即 xywh 的差,
这样做的目的是让 预测框快速学习到先验框的形状;
 表示 第 k 个预测框内有对象,
表示 第 k 个预测框内有对象,
如何确定预测框内有对象呢?对于某个 ground truth,首先计算它的中心落在哪个 cell,然后计算该 cell 对应的 anchor box 与 该 ground truth 的 IOU, 这里计算 IOU 时有点特殊,只比较形状,不比较位置,通常的做法是,把 anchor box 和 ground truth 都移动到图像左上角,然后计算 IOU,IOU 最大的那个 anchor box 与 ground truth 匹配,这个 anchor box 对应的预测框内就有对象,这个预测框负责预测 ground truth,
上述只是逻辑,具体实现时自行设计,
第3.1项表示 ground truth 与对应的预测框的坐标误差;
既然 可以约束预测框内有对象,那么置信度的计算就只是 IOU 了,IOUtruthk 表示 ground truth 的置信度,b 表示预测框的置信度,
λobj 是个系数,论文中取值为 1,
第3.2项表示 预测框与 ground truth 的置信度误差;
第3.3项表示 预测框与 ground truth 的类别误差;
一堆 λ 都是权重;
模型训练与预测
训练
Yolo v2 训练主要分为 3 个阶段
1. 在 ImageNet 上预训练 Darknet-19,输入为 224x224,训练 160 个 epoch
2. 将输入改为 448x448,继续在 ImageNet 上 finetune Darknet-19,训练 10 个 epoch
3. 修改 Darknet-19 分类模型为检测模型,并在 检测数据集上 finetune 模型
网络修改如下:移除最后一个卷积层、global avgpooling层以及softmax层,并且新增了三个 卷积层,同时增加了一个pass through层,最后使用
卷积层输出预测结果,输出的channels数为:

预测
由于anchors数为5,对于VOC数据集输出的channels数就是125,而对于COCO数据集则为425。
以VOC数据集为例,最终的预测矩阵为 (shape为
),可以先将其reshape为
,其中
为边界框的位置和大小
,
为边界框的置信度,而
为类别预测值。
模型效果
用 VOC 数据集进行测试,输入尺寸较小时,Yolo v2 mAP 较低,速度非常快,输入尺寸较大时,mAP 很高,速度略慢

Yolo 9000
后续更新...
参考资料:
https://zhuanlan.zhihu.com/p/35325884
https://zhuanlan.zhihu.com/p/47575929
https://zhuanlan.zhihu.com/p/40659490
https://zhuanlan.zhihu.com/p/74540100