监控系统作用
监控系统主要用于保证所有业务系统正常运行, 和业务的瓶颈监控. 需要周期性采集和探测.
采集的详情
- 采集: 采集器, 被监控端, 监控代理, 应用程序自带仪表盘, 黑盒监控, SNMP.
- 存储: SQL, NoSQL(k/v, document, TSDB(series))
- 展示: Grafana
- 可观测性系统
- 指标监控(Metrics): 随时间推移产生的一些于监控相关的可集合数据点.
- 日志监控(Logging): 离散式的日志或事件.
- 链路跟踪(Tracing): 分布式应用调用链链跟踪.
prometheus 是一款时序(time series)数据库, 但他的功能却并非止步于TSDB, 而是一款设计用于进行目标(Target)监控的关键组件.
组合生态系统内的其他组件, 例如 Pushgateway, Altermanager 和 Grafana等, 可构成完整的IT监控系统.
多维度标签, 每个独立的标签组合都代表一个独立的时间序列.
内建时序数据的聚合, 切割, 切片功能.
支持双精度浮点型数据.
时序数据, 是在一段时间内通过重复测量(measurement)而获得的观测值的集合; 将这些观测值绘制于图形之上, 它会有一个数据轴和一个时间轴.
服务器指标数据, 应用程序性能监控数据, 网络数据等也是时序数据.
如何抓取数据Pull?
基于 HTTP call, 从配置文件中指定的网络端点(endpoint) 上周期性获取指标数据.
Prometheus 支持通过三种类型的途径从目标上抓取(Scrape) 指标数据.
-
-
Instrumentation 应用程序内建的
-
Prometheus 同其它 TSDB 相比有一个非常经典的特性; 他可以主动从 Target 上"拉取" 数据, 而非等待被监控端的agent推送"push";
两种方式各有优劣, 其中 Pull 模型的优势在于:
-
集中控制: 有利于将配置集中在 Prometheus Server上完成, 包括指标即采集速率等.
-
Prometheus 的根本目标在于收集 在 Target 上预先完成集合的聚合性数据.而非一款由时间驱动的存储系统.
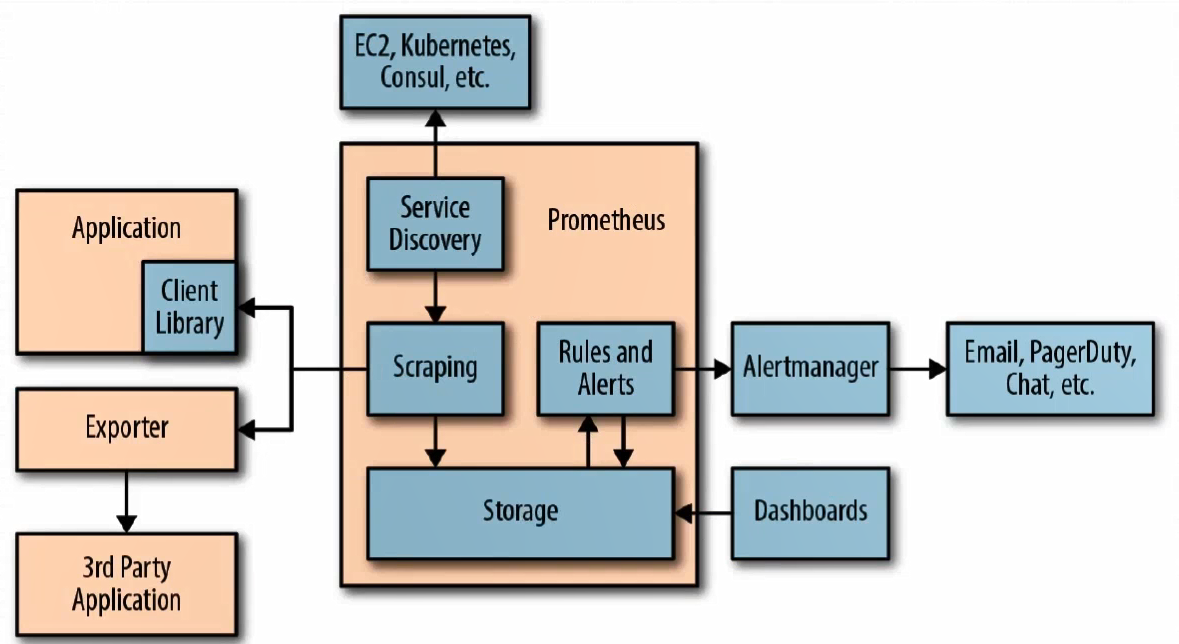
Prometheus 生态组件
- Prometheus Server: 收集和存储时间序列数据.
- Client Library: 客户端库, 目的在于为那些期望原生提供 Lnstrumentation 更的应用程序提供便捷的开发途径.
- Push Gateway: 接收那些通常由短期作业生成的指标数据的网关, 并支持Prometheus Server 进行指标拉取操作;
- Exporters: 用于暴露现有应用程序或者服务(不支持Instrumentation) 的指标给Prometheus Server.
- Alertmanager: 从 Prometheus Server 接收到告警通知后, 通过去重分组, 路由等预处理功能以高效向用户完成告警信息发送.
- Data Visuaization: Prometheus Web UI(Prometheus Server 内建), 及 Grafana 等,
- Service Discovery: 动态发现待监控的Target, 从而完成监控配置的中间组件, 从容器化环境尤为重要, 该组件目前由 Prometheus Server内建支持.
Prometheus 仅用于以键值形式存储的时间式的聚合数据, 它并不支持存储文本信息.
其中 键 成为指标 "Metric", 它通常意味着 CPU速率, 内存使用速率, 或 分区空闲比例等.
用一指标可能会适配到读个目标或设备, 因而他使用标签作为元数据, 从而为 Metric 添加更多的信息描述纬度.
这些标签还可以作为过滤器进行指标过滤机聚合运算.
Counter 计数器
用于保存单调递增的数据, 例如访问站点访问次数等, 不能为负值, 也不支持减少, 但是可以重置为0.
Gauge 仪表盘
用于 存储有着起伏特征的指标数据, 例如内存空间大小等;
Gauge 是 Counter 的超集, 但存在指标数据丢失的可能性是, Counter 能让用户确切来哦接指标随时间的变化, 而 Gauge 则可能随时间流逝而精准度越来越低.
Histogram 直方图
它会在一段时间内对数据进行采样, 并将其计入可配置的 bucket 之中, Histogram 能够储存更多的信息, 包括样本值分部在每个 bucket (bucket 自身的可配置) 中的数量, 所有样本值之和和以及总的样本数量, 从而 Prometheus 能够使用内建函数进行如下操作:
-
计算样本平均值: 以值的总和除以值的数量.
-
计算样本分位值: 分为数有助于了解符合特定标准的数据个数. 例如评估响应时长超1秒中的请求比例, 若超过20%即发送告警等.
summary 摘要
Histogram 扩展类型, 单它使直接由被检测端自行聚合计算出分位数, 并将计算结果响应给 Prometheus Server 的样本采集请求, 因而, 其分位数计算是由监控端完成.