语音识别中声音和文字的表示
声音:通常表示为一个d维、长度为T的向量序列,
文字:表示为长度为N的token序列(token的共V类),token通常用它在词表中id表示。
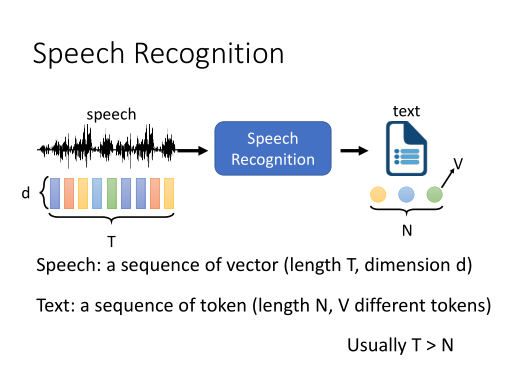
token通常有很多种粒度:Bytes < Grapheme/Phoneme < Morpheme < Word
Phoneme:声音单元,通常需要配合词典(word-phoneme)使用,是一些W,AN,N,P,CH之类的助记符,对同音词不友好,
Grapheme:书写单元,英文的包括二十六个字母和空格及标点符号,中文的话包括几千个汉字,没有OOV的问题,不过模型需要自己学会一个词汇包含几个Grapheme,
Word: 词单元,对于很多语言来说,可能词数会非常多,像土耳其语,一个词甚至可以非常长,无法穷举,
Morpheme:表意的最小单元,英语的话就是把前缀后缀也拆出来,可以通过语言学和统计学的方法来获取,
Bytes: 二进制单元,语言无关(都可以用UTF-8编码),直接从字节层面获取信息,token大小不超过256。
目前论文中的使用情况如下图。
还有很多有趣应用,比如输入声音讯号,输出word embedding,
输入英文语音,输出中文句子(类似翻译),
还有和意图识别、槽位填充结合到一起的应用。

声音数据的处理
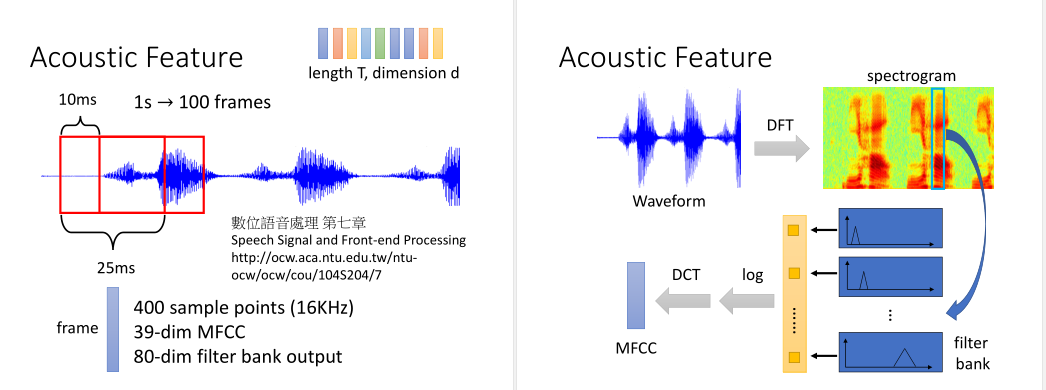
传统的语音识别方法,会将语音讯号抽帧(取一个窗口),一个25ms的frame有400个采样点(16KHz)。
或者会用MFCC将它转为39维的向量,近年来非常流行的是用filter bank output方法转换为80维的向量。
然后窗口右移10ms,再用同样的方法取向量。窗口之间是有重叠的。
一个窗口的讯号我们会用傅里叶变换映射到频域空间。频谱和声音之间的关联性是非常强的。
接着我们会用一些根据人发声器官发声原理设计的filter bank来对频谱过滤,取log后再做DCT就可以得到MFCC向量。这些我们叫作声学特征。
以下是论文中的趋势,filter bank output最为流行,其次是MFCC。
有哪些数据集可以使用可以看下图,并和图像处理的MNIST、CIFAR-10做了类比。不过在工业上Google,FB使用的数据集还是要远大于此。
