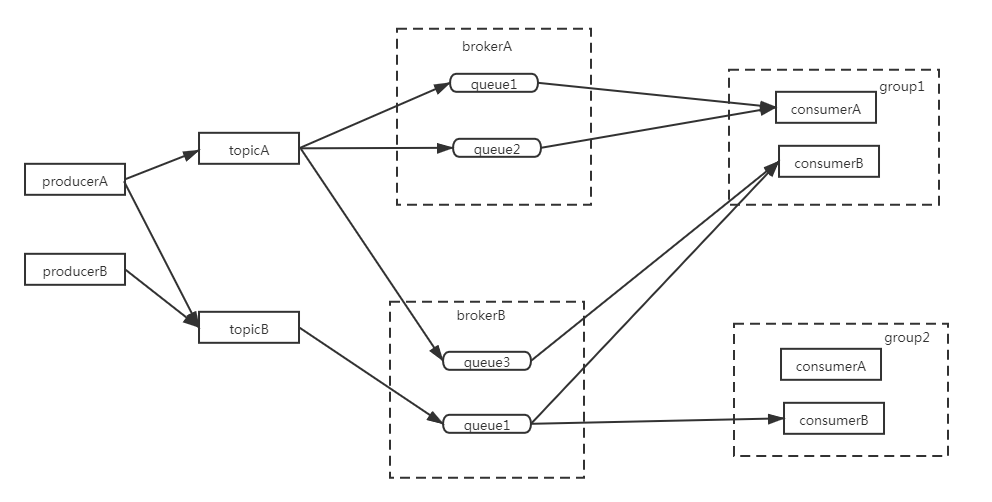
消息模型
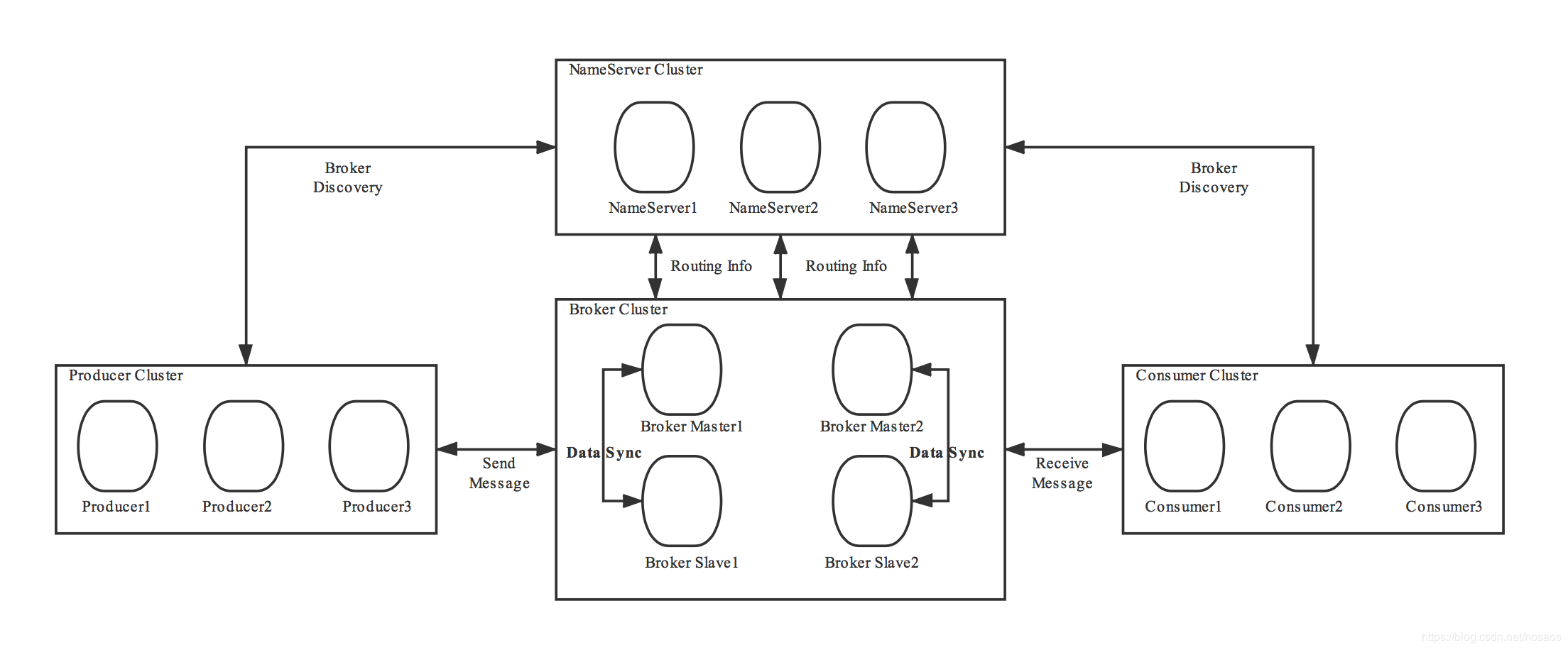
集群部署
NameServer
NameServer主要作用:为消息生产者和消息消费者提供关于主题Topic的路由信息(也就是topic包含哪些queue,每个queue分布在哪个broker上,broker的主从信息,集群中有哪些broker,broker的心跳信息)。
所以NameServer包含的功能主要有:
- borker向NameServer注册自己
- broker启动时向NameServer注册自己,然后开启定时任务每个30s报告自己存活心跳
- 获取NameServer集群中所有NameServer地址,遍历挨个进行注册
- broker向NameServer发送存活心跳,NameServer会开启定时任务,每10秒扫描无效broker并且剔除(默认120秒未收到心跳则剔除)
- broker向NameServer报告下线:
- producer和consumer向NameServer查询路由信息
- NameServer处理上述所有请求
NameServer支持集群部署,但是它们之间不会同步数据,broker会向所有NameServer注册路由信息。
Server向NameServer更新路由信息,客户端向NameServer查询路由信息。这两种操作通过读写锁来实现并发安全。
RoutelnfoManager:NameServer通过RoutelnfoManager对象来存封装由信息
public class RouteInfoManager {
private static final InternalLogger log = InternalLoggerFactory.getLogger(LoggerName.NAMESRV_LOGGER_NAME);
private final static long BROKER_CHANNEL_EXPIRED_TIME = 1000 * 60 * 2;
private final ReadWriteLock lock = new ReentrantReadWriteLock();
//topic和queue关系
private final HashMap<String/* topic */, List<QueueData>> topicQueueTable;
//Broker基础信息,包含brokerName、所属集群名称、主备Broker地址。brokerId为0代表Master,大于0表示Slave 。
private final HashMap<String/* brokerName */, BrokerData> brokerAddrTable;
//Broker 集群信息,存储集群中所有 Broker 名称
private final HashMap<String/* clusterName */, Set<String/* brokerName */>> clusterAddrTable;
//Broker 状态信息。 NameServer 每次收到心跳包时会替换该信息
private final HashMap<String/* brokerAddr */, BrokerLiveInfo> brokerLiveTable;
private final HashMap<String/* brokerAddr */, List<String>/* Filter Server */> filterServerTable;
}
producer
producer发送消息:
- 首先启动的时候,创建客户端实例MQClientlnstance,将其实例名instanceName设置为进程ID,为什么这么做
- 首先每个producer都会创建一个客户端实例MQClientlnstance负责拉取NameServer中的路由信息,那么如果一台服务器部署两个producer应用,实例名默认是服务器ip,如果这里不将服务命设置成进程id,那么这两个producer的实例名就重复了。
- 同理可以知道:同一个应用下的多个producer是共用一个MQClientlnstance的。
- 验证发送的消息不能超过4M
- 先从本地缓存中查询topic的路由信息封装到对象TopicPublishInfo中,如果未命中去nameserver获取,然后在将路由信息缓存到本地
- 如果发送消息失败的话,通过for循环的方式进行重试
- 当broker挂掉的时候,客户端感知是有延迟性的,所以要实现一个失败重试的机制,比如broker集群包括a、b、c三个服务器,第一次向a,发送消息,失败了,则将a从列表中移除,然后在从b和c中选择一个再次尝试发送
- 消息发送先获取主题的路由信息,broker主从时,默认是轮询的方式进行负载
TopicPublishInfo:producer通过TopicPublishInfo对象封装topic的路由信息
public class TopicPublishInfo {
private boolean orderTopic = false;//是否是顺序消费
private boolean haveTopicRouterInfo = false;
private List<MessageQueue> messageQueueList = new ArrayList<MessageQueue>();//主题的消息队列
//每选择一次消息队列, 该值会自增 l ,如果 Integer.MAX_VALUE, 则重置为 0,用于选择消息队列
private volatile ThreadLocalIndex sendWhichQueue = new ThreadLocalIndex();
private TopicRouteData topicRouteData;
}
public class TopicRouteData extends RemotingSerializable {
private String orderTopicConf;
private List<QueueData> queueDatas;//topic 队列元数据。
private List<BrokerData> brokerDatas;//topic 分布的 broker 元数据。
private HashMap<String/* brokerAddr */, List<String>/* Filter Server */> filterServerTable;
}
RocketMQ 支持 3 种消息发送方式:同步(sync)、 异步(async)、单向(oneway)。
同步: 发送者向 MQ 执行发送消息 API 时,同步等待, 直到消息服务器返回发送结果。 默认是该方式,默认超时时间为 3s
异步: 发送者向 MQ 执行发送消息 API 时,指定消息发送成功后的回掉函数,然后调 用消息发送 API 后,立即返回,消息发送者线程不阻塞 ,直到运行结束,消息发送成功或 失败的回调任务在一个新的线程中执行。
单向:消息发送者向 MQ 执行发送消息 API 时,直接返回,不等待消息服务器的结果, 也不注册回调函数,简单地说,就是只管发,不在乎消息是否成功存储在消息服务器上
消息队列选择器MessageQueueSeleetor
例子:订单状态变更消费,生产者如果需要保证一个订单的顺序性,也就是一个订单的消息要发到同一个队列上。

消息存储
commitLog数据存储文件

所有topic消息混合存储,数据文件存在commitLog目录下,每一个文件默认lG,一个文件写满后再创建另外一个,以该文件中第一个偏移量为文件名,偏移量小于20位用0补齐。
commitLog是二进制文件,转换一下是下面这个样子
主题:topic0 消息:清幽之地 队列ID:1 存储地址:/192.168.44.1:10911
主题:topic1 消息:清幽之地 队列ID:0 存储地址:/192.168.44.1:10911
主题:topic2 消息:清幽之地 队列ID:1 存储地址:/192.168.44.1:10911
主题:topic3 消息:清幽之地 队列ID:0 存储地址:/192.168.44.1:10911
主题:topic4 消息:清幽之地 队列ID:3 存储地址:/192.168.44.1:10911
主题:topic5 消息:清幽之地 队列ID:1 存储地址:/192.168.44.1:10911
commitLog文件写入需要获取锁。
ConsumeQueue索引文件
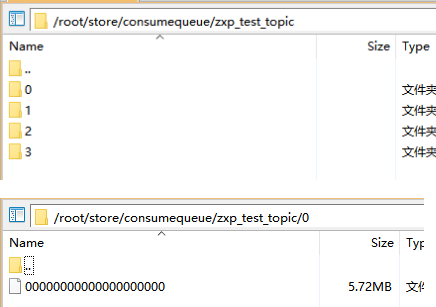
- 因为所有topic的数据文件都是混合存储在一个大目录commitLog下的,但是查询消息的时候都是根据topic-queue来查询消息的,所以维护了这么个索引结构,ConsumeQueue就是数据文件的索引。
- 每个topic对应一个目录,topic下每个queue对应一个目录,queue下的文件里的内容就是commitLog里数据的偏移量索引。
ConsumeQueue文件内容如下
消息长度:173 消息偏移量:2003
消息长度:173 消息偏移量:2695
消息长度:173 消息偏移量:3387
消息长度:173 消息偏移量:4079
消息长度:173 消息偏移量:4771
消息长度:173 消息偏移量:5463
消息长度:173 消息偏移量:6155
消息长度:173 消息偏移量:6847
消息长度:173 消息偏移量:7539
消息长度:173 消息偏移量:8231
消息长度:173 消息偏移量:8923
消息长度:173 消息偏移量:9615
消息长度:173 消息偏移量:10307
消息长度:173 消息偏移量:10999
消息长度:173 消息偏移量:11691
消息长度:173 消息偏移量:12383
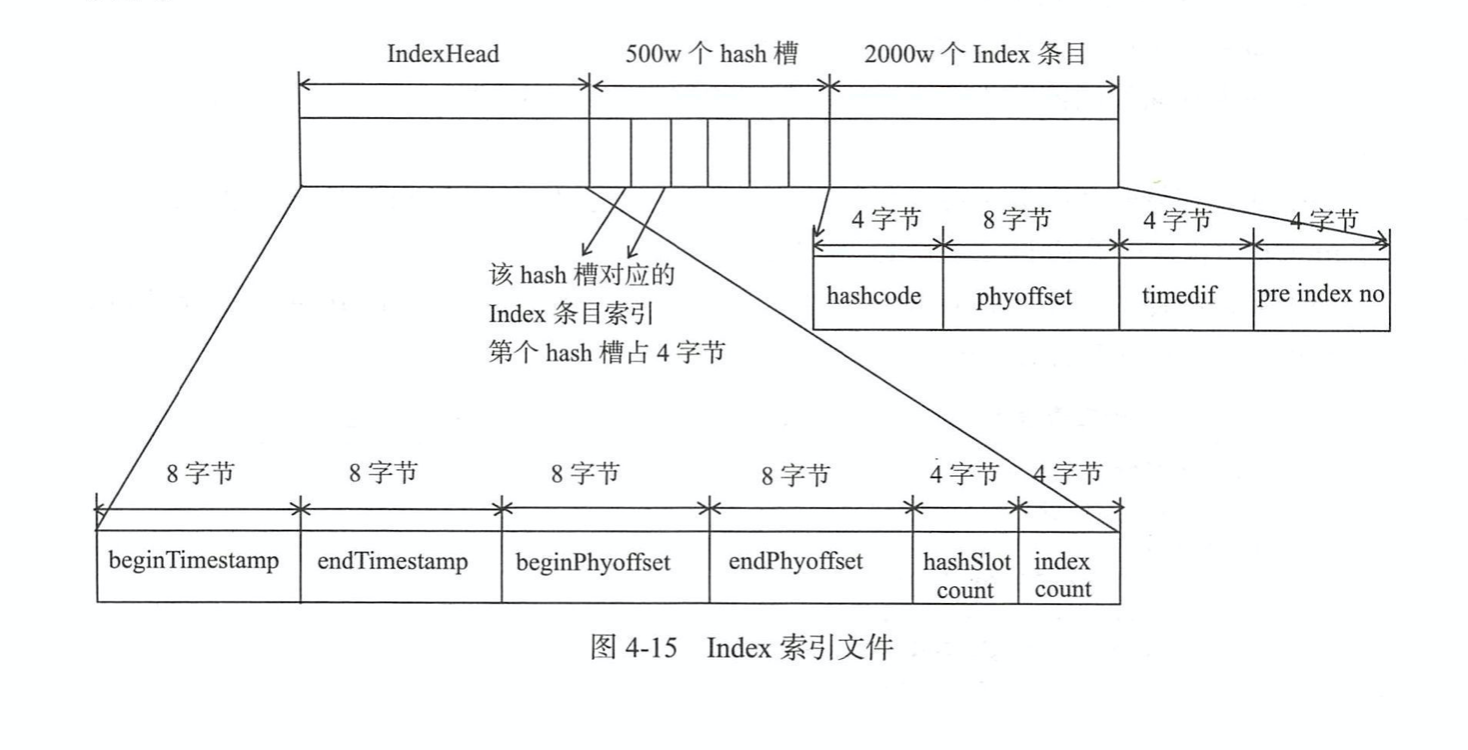
IndexFile索引文件
根据key查找消息时,通过该索引文件。
消息查找
分三种场景:
- 根据偏移量:消费者订阅topic消费消息,使用cosumerQueue索引结构
- 根据消息key:生产者这发送消息时可以指定key,也可以producer自动生成,使用IndexFile索引结构
- 根据消息id:broker自己生成的
根据偏移量查询
1.消费者每次消费需要记录一个当前消费位置偏移量,下次从server消费消息时要带着这个偏移量
2.根据偏移量可以定位到具体的cosumerQueue文件的某一行(topic有多少个queue,每个queue存了多少条消息,根据这两个就能计算出来),进而获取消息在commitLog中的偏移量
3.然后去commitLog定位出具体消息
根据消息id查询
1.消息id16个字节,包含了消息存储的broker节点、在commitLog文件中的偏移量。
2.在producer发送消息,server存储的时候生成这个消息id
3.根据消息id查询的时候就可以直接在commitLog文件中精确定位
根据消息key查询
1.producer发送消息,server存储时,会维护一个哈希结构的索引文件,对消息key哈希。
2.查询的时候直接根据消息key哈希定位到某一个哈希槽,哈希槽记录了该槽位对应链表结构的最新一条条目数据,每个index条目数据存储了链表结构的上一条数据的偏移量。这样就能定位出具体数据。
实时更新消息消费队列与索引文件
消息消费队列文件、消息属性索引文件都是基于 CommitLog 文件构建的 , 当消息生产 者提交的消息存储在 Commitlog 文件中 , ConsumeQueue、 IndexFile 需要及时更新,否则消 息无法及时被消费,根据消息属性查找消息也会出现较大延迟。 RocketMQ 通过开启一个线 程 ReputMessageServcie 来准实时转发 CommitLog 文件更新事件, 相应的任务处理器根据 转发的消息及时更新 ConsumeQueue、 IndexFile 文件
消息队列与索引文件恢复
由于 RocketMQ 存储首先将消息全量存储在 Commitlog 文件中,然后异步生成转发任 务更新 ConsumeQueue、 Index 文件。 如果消息成功存储到 Commitlog 文件中,转发任务未 成功执行,此时消息服务器 Broker 由 于某个原因看机,导致 Commitlog、 ConsumeQueue、 IndexFile 文件数据不一致。 如果不加以人工修复的话,会有一部分消息即便在 Commitlog 文件中存在,但由于并没有转发到 Consum巳queue,这部分消息将永远不会被消费者消费。 那 RocketMQ 是如何使 Commitlog、 消息消费队列( ConsumeQueue)达到最终一致性的 呢?
- 启动的时候判断上一次退出是否正常。 其实现机制是 Broker 在启动时创建${ROC口T_ HOME}/store/abort 文件,在退出时通过注册 NM 钩子函数删除 abort 文件。 如果下一次启 动时存在 abort 文件。 说明 Broker 是异常退出的, Commitlog 与 Consumequeue 数据有可能 不一致,需要进行修复。
- 然后加载commitLog、consumeQueue、索引文件到内存,生产相应的内存中对应的对象
- 加载checkPoint文件,该文件记录上面三个文件的刷盘时间.
- 根据 Broker 是否是正常停止执行不同的恢复策略。
过期文件删除机制
由于 RocketMQ 操作 CommitLog、 ConsumeQueu巳文件是基于内存映射机制并在启动 的时候会加载 commitlog、 ConsumeQueue 目录下的所有文件,为了避免内存与磁盘的浪 费,不可能将消息永久存储在消息服务器上,所以需要引人一种机制来删除己过期的文件。 RocketMQ 顺序写 Commitlog 文件、 ConsumeQueue 文件,所有写操作全部落在最后一个 CommitLog 或 ConsumeQueue 文件上,之前的文件在下一个文件创建后将不会再被更新。 RocketMQ 清除过期文件的方法是 :如果非当前写文件在一定时间间隔内没有再次被更新, 则认为是过期文件,可以被删除, RocketMQ 不会关注这个文件上的消息是否全部被消费。 默认每个文件的过期时间为 72 小时,通过在 Broker 配置文件中设置 fileReservedTime 来改 变过期时间,单位为小时
刷盘
当生产者发送消息到server的时候,消息并不是直接存储到磁盘,而是先写到内存中。 然后有一个单独线程刷到磁盘。
消息消费
集群模式:一个消息同一时间只能被群组内一个消费者消费。rocketmq只支持局部顺序消费,也就是只能保证一个消息队列顺序消费。消息进度保存在 Broker 上。rocketmq默认是集群模式
广播模式:一个消息被所有消费者消费,消费进度存储在消费端
推模式和拉模式
消息消费过程
rocketmq开启一个单独的线程PullMessageService 负责对消息队列进行消息拉取,从远端服务器 拉取消息后将消息存入 ProcessQueue 消息队列处理队列中,然后在从ProcessQueue提交到消费线程池,线程池中消息消费后在从ProcessQueue中移除,确保了消息拉取 与消息消费的解耦。
ProcessQueue:每个队列对应一个ProcessQueue,又叫快照队列。该快照队列内部持有个锁,可以通过他来实现流量控制和顺序消息等。
拉取消息流控
1.当ProcessQueue中消息总数达到阀值,触发流控,不在继续从broker拉取消息,延迟50ms后继续。
2.当ProcessQueue中最大偏移量和最小偏移量间距达到阀值,触发流控。
长轮训消费
消费者通过拉模式消费消息,消费者主动轮训去broker拉取消息,当没有消息可消费的时候,broker会将该拉取请求挂起,直到有消息后在返回给消费者。
- broker最长挂起时间为15s
队列与消费者负载映射
topic下有多个队列,消费者群组内有多个消费者,当消费者组发生变化时,会触发在平衡重新对队列和消费者进行映射。另外会有个单独的线程每隔20s触发一次在平衡。
队列和消费者映射规则
- 平均分配 推荐
- 平均轮训分配 推荐
- 哈希
- 根据配置文件
- 根据broker部署机房
延时消息
延时消息的关键点在于Producer生产者需要给消息设置特定延时级别,消费端代码与正常消费者没有差别。
设置消息延时级别的方法是setDelayTimeLevel(),目前RocketMQ不支持任意时间间隔的延时消息,只支持特定级别的延时消息,什么意思呢?
延时级别1对应延时1秒后发送消息
延时级别2对应延时5秒后发送消息
延时级别3对应延时10秒后发送消息
private String messageDelayLevel = "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";
延迟消息总流程:
- producer端设置消息delayLevel延迟级别,消息属性DELAY中存储了对应了延时级别
- broker端收到消息后,判断延时消息延迟级别,如果大于0,则备份消息原始topic,queueId,并将消息topic改为延时消息队列特定topic(SCHEDULE_TOPIC),queueId改为延时级别-1
- mq服务端ScheduleMessageService中,为每一个延迟级别单独设置一个定时器,定时(每隔1秒)拉取对应延迟级别的消费队列
根据消费偏移量offset从commitLog中解析出对应消息 - 从消息tagsCode中解析出消息应当被投递的时间,与当前时间做比较,判断是否应该进行投递
若到达了投递时间,则构建一个新的消息,并从消息属性中恢复出原始的topic,queueId,并清除消息延迟属性,从新进行消息投递 - 定时消息会暂存在名为SCHEDULE_TOPIC_XXXX的topic中,并根据delayTimeLevel存入特定的queue,queueId = delayTimeLevel – 1,即一个queue只存相同延迟的消息,保证具有相同发送延迟的消息能够顺序消费。broker会调度地消费SCHEDULE_TOPIC_XXXX,将消息写入真实的topic。
顺序消息
顺序消息分为全局顺序消息与分区顺序消息,全局顺序是指某个Topic下的所有消息都要保证顺序;部分顺序消息只要保证每一组消息被顺序消费即可。
rockerMq默认不开启顺序消息
全局顺序 对于指定的一个 Topic,所有消息按照严格的先入先出(FIFO)的顺序进行发布和消费。 适用场景:性能要求不高,所有的消息严格按照 FIFO 原则进行消息发布和消费的场景
分区顺序 对于指定的一个 Topic,所有消息根据 sharding key 进行区块分区。 同一个分区内的消息按照严格的 FIFO 顺序进行发布和消费。 Sharding key 是顺序消息中用来区分不同分区的关键字段,和普通消息的 Key 是完全不同的概念。 适用场景:性能要求高,以 sharding key 作为分区字段,在同一个区块中严格的按照 FIFO 原则进行消息发布和消费的场景。
消息过滤
rocketmq支持表达式和类两种过滤方式,表达式又分为tag和sql92两种方式
Tag过滤方式
Consumer端订阅消息是需要通过ConsumeQueue这个消息消费的逻辑队列拿到一个索引,然后再从CommitLog里面读取真正的消息实体内容,所以说到底也是还绕不开其存储结构。其ConsumeQueue的存储结构如下,可以看到其中有8个字节存储的Message Tag的哈希值,基于Tag的消息过滤正式基于这个字段值的。
Consumer端在订阅消息时除了指定Topic还可以指定TAG,如果一个消息有多个TAG,可以用||分隔。broker首先定位到ConsumeQueue的一条记录后,会用它记录的消息tag hash值去做过滤,由于在服务端只是根据hashcode进行判断,无法精确对tag原始字符串进行过滤,故在消息消费端拉取到消息后,还需要对消息的原始tag字符串进行比对,如果不同,则丢弃该消息,不进行消息消费。

实战例子:


SQL92的过滤方式
实战例子:

类过滤
需要一个classFilter服务器,消费者需要上传过滤类到classFilter服务器。 然后消费的时候经过classFilter中转过滤。可以精确过滤,不像tag在broker上是哈希过滤。
实战例子:



主从同步
主从同步:从服务器启动时主动向主建立tcp长连接,然后将自身commitLog最大偏移量发送给主,主会和自身commitLog最大偏移量比较,判断是否需要同步数据。
读写分离(broker负载):消费者首先从broker主拉取消息,broker会根据各个节点压力情况判断下次从哪个节点拉取消息,返回给消费者,消费者下次从这个节点拉取消息。
事务消息
首先生产者发送状态为prepare的消息到服务器,服务器将消息保存在单独队列中,然后开启定时线程回查生产者该消息是回滚还是提交。
实战例子:



