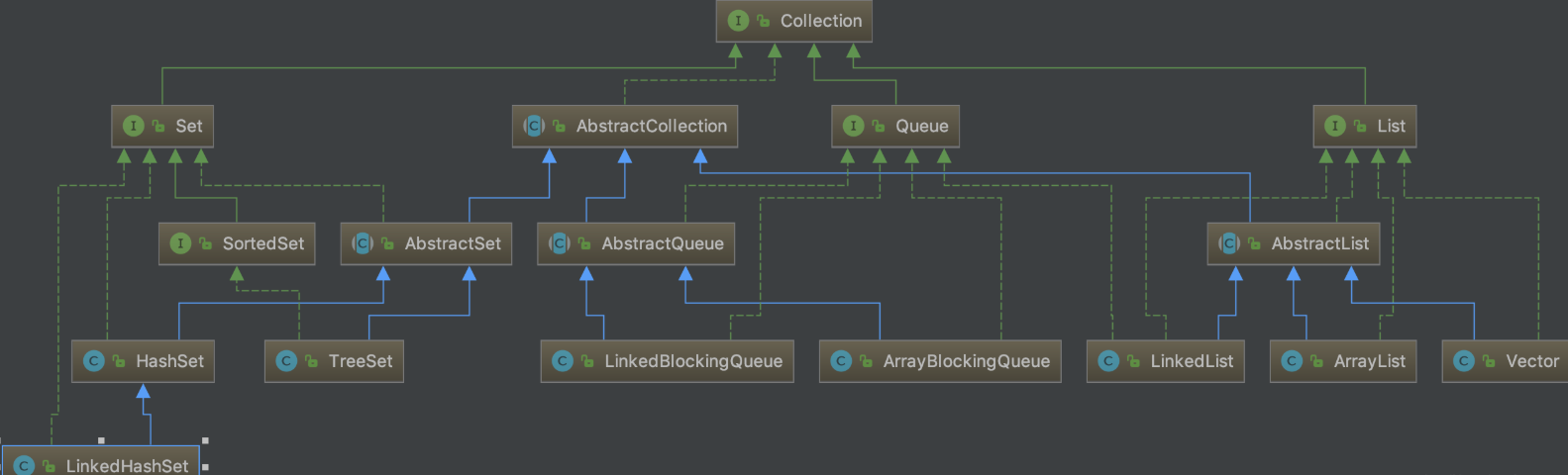
List , Set, Queue和Map都是接口,前三个继承至Collection接口,Map为独立接口
一 、Collection:
集合的顶层接口,不能被实例化
a) 根接口Collection
i. 常用子接口
1. List
实现类:ArrayList、Vector、LinkedList
2. Set
实现类:HashSet、TreeSet
b) 添加功能
i. boolean add(object obj)添加一个元素
ii. boolean addAll(Collection c)将集合c的全部元素添加到原集合元素后返回true
iii. 添加功能永远返回true
c) 删除功能
i. void clear();移除所有元素
ii. boolean remove(Object o)移除一个元素
iii. boolean removeAll(Collection c)移除一个集合的元素,只要有一个被移除就返回true,改变原集合,删除原集合中和c中相同的元素
iv. 删除功能只有删除成功后才返回true
d) 判断功能
i. boolean contain(object o)判断集合中是否包含指定的元素。
ii. boolean containsAll(Collection c)判断原集合中是否包含指定集合c的所有元素,有则true,
iii. boolean isEmpty()判断集合是否为空
e) 获取功能
i. Iterator iterator()迭代器,集合的专用方式,实现遍历的功能
ii. Object next()获取当前元素,并移动到下一个位置
iii. boolean hasNext()判断此位置是否有元素
iv. 迭代器遍历实例在下面
f) 长度功能
i. int size()元素的个数
ii. 数组和字符串中都是length()方法获取元素个数,集合中是size()方法
因为object包括集合、字符串、数组,所以其不能直接用length方法。
g) 交集功能boolean retainAll(Collection c)
两个集合交集的元素给原集合,并判断原集合是否改变,改变则true,不变则false
h) 把集合转换为数组
i. Object [] toArray()
1、List集合
Collection集合的子类
特点:
a) 有序(存储和取出的元素顺序一致),可重复
b) 特有功能
i. 添加功能
void add(int index,Object element)在指定位置添加元素(原索引处的元素后延)
ii. 获取功能
Object get(int index)获取指定位置的元素
iii. 列表迭代器
1. ListIterator listIterator() List集合特有的迭代器
2. Iterator迭代器的子类,所以其可以用Iterator中的boolean hasNext()、Object next()方法
3. 特有的方法:
a) Object previous ()返回此处位置的前一个的元素,并移动到前一个位置。
b) boolean hasPrevious()判断此处的前一个位置是否有元素
c) 逆向遍历必须先正向遍历使指针指到后面位置才能使用(使用意义不大)
4. 迭代器遍历元素时不能直接通过集合修改元素,怎么办?
a) 迭代器修改元素
i. List迭代器有修改方法,Collection中的迭代器没有
ii. 通过迭代器中add(object obj)方法添加,跟在刚才迭代元素后面
b) 通过集合遍历元素,并用集合修改元素(for循环遍历)
i. 通过集合中add(object obj)方法添加,跟在集合最后面
5. 迭代器遍历实例实例在下面给出
iv. 删除功能
Object remove(int index)根据索引删除指定的元素,并返回删除的元素
v. 修改功能、
Object set(int index,Object element)根据索引修改元素,返回被修改的元素
vi. 数组转成集合
1. public static List asList(T… a),返回类型为List类型
2. a为集合,此处的… 代表可变参数,也就是a的数组元素个数可变
3. 此方法是Arrays类中的静态方法
4. 数组转变为集合,实质还是数组需要保证长度不变,所以不支持增删集合元素,可以修改元素
c) List子类的特点:
i. ArrayList:
1. 底层数据结构是数组,查询快、增删慢
2. 线程不安全,效率高
ii. Vector:
1. 底层数据结构是数组,查询快,增删慢
2. 线程安全,效率底
iii. LinkedList:
1. 底层数据结构是链表,查询慢,增删快
2. 线程不安全,效率高
1.1、 Vector集合特有的特点
a) 添加功能
i. public void addElement(Object obj)
b) 获取功能
i. public Object elementAt(int index)
ii. public Enumeration elements ()
1. 也是用来遍历集合
2. boolean hasMoreElements()
3. Object nextElement()
4. 基本不用这个,都是直接用上面的迭代器实现遍历
1.2、LinkedList集合的特有功能
a) 添加功能
i. public void addFirst(Object e)
ii. public void addLast(Object e)
b) 获取功能
i. public Object getFirst()
ii. public Object getLast()
c) 删除功能
i. public Object removeFirst()
ii. public Object removeLast()
2、 Set集合
a) 无序(存储和取出顺序不一致,有可能会一致),但是元素唯一,不能重复
b) b) 实现类
i. HashSet
1. 底层数据是哈希表
2. 通过两个方法hashCode()和equals()保证元素的唯一性,方法自动生成
3. 子类LinkedHashSet底层数据结构是链表和哈希表,由链表保证元素有序,
由哈希表保证元素唯一。
ii. TreeSet
1. 底层数据是红黑二叉树
2. 排序方式:自然排序、比较器排序
3. 通过比较返回值是否为0来保证元素的唯一性。
2.1、 HashSet类:
a) 不保证set的迭代顺序,
b) 当存储对象时需要重写equals()和hashCode()方法
2.1.1、 LinkedHashSet类
a) HashSet的子类
b) 可预知的迭代顺序,底层数据结构由哈希表和链表组成
i. 哈希表:保证元素的唯一性
ii. 链表:保证元素有序(存储和取出顺序一致)
2.2、 TreeSet类
a) 能够保证元素唯一性(根据返回值是否是0来决定的),并且按照某种规则排序
i. 自然排序,无参构造方法(元素具备比较性)
按照compareTo()方法排序,让需要比较的元素所属的类实现自然排序接口Comparable,
并重写compareTo()方法
ii. 1. 让集合的构造方法接收一个比较器接口的子类对象(compareator)
(此处的Comparator为接口,需要写一个接口实现类,在实现类中重写compare()方法,
并在这里创建接口实现类的对象,可以用匿名内部类来创建实现类对象)
b) 底层是自平衡二叉树结构
i. 二叉树有前序遍历、后序遍历、中序遍历
ii. TreeSet类是按照从根节点开始,按照从左、中、右的原则依此取出元素
c) 当使用无参构造方法,也就是自然排序,需要根据要求重写compareTo()方法,这个不能自动生成
3.Map
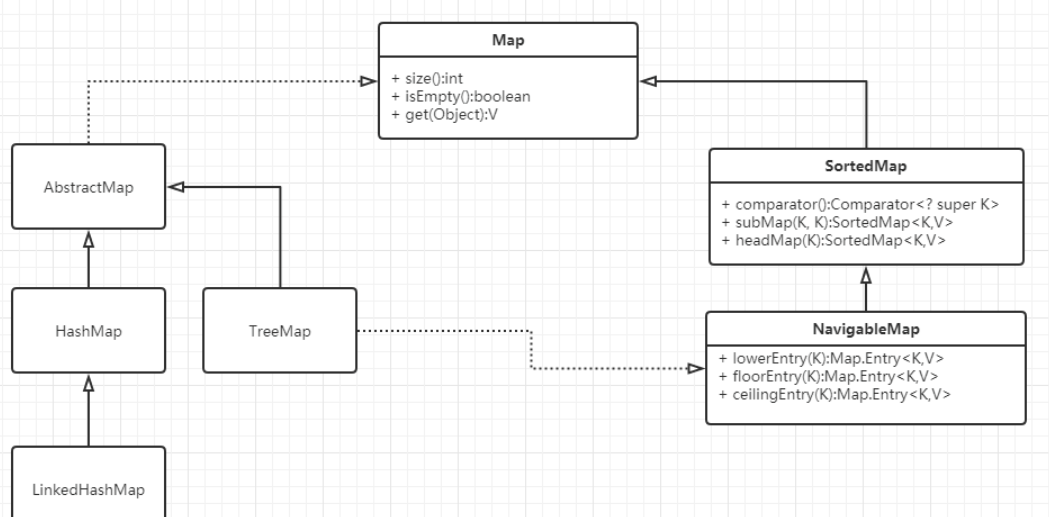
Map:
Map接口有三个比较重要的实现类,分别是HashMap、TreeMap和HashTable。
TreeMap是有序的,HashMap和HashTable是无序的。
Hashtable的方法是同步的,HashMap的方法不是同步的。这是两者最主要的区别。
这就意味着:
Hashtable是线程安全的,HashMap不是线程安全的。
HashMap效率较高,Hashtable效率较低。
如果对同步性或与遗留代码的兼容性没有任何要求,建议使用HashMap。 查看Hashtable的源代码就可以发现,除构造函数外,Hashtable的所有 public 方法声明中都有 synchronized关键字,而HashMap的源码中则没有。
Hashtable不允许null值,HashMap允许null值(key和value都允许)
父类不同:Hashtable的父类是Dictionary,HashMap的父类是AbstractMap
参考链接:https://blog.csdn.net/zhangqunshuai/article/details/80660974
https://blog.csdn.net/zfliu96/article/details/83476493