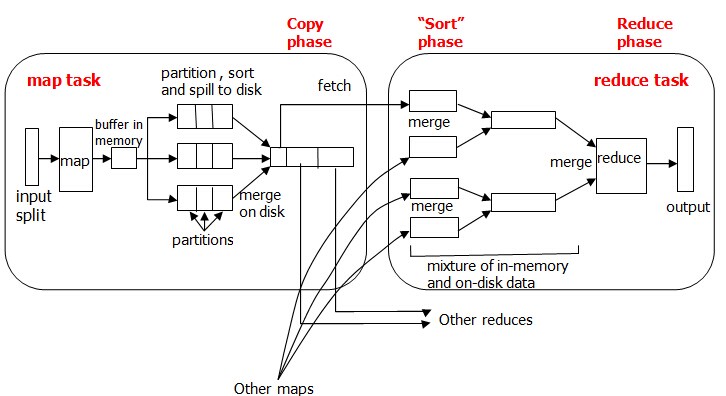
MapReduce确保每个reducer的输入都按键排序。系统执行排序的过程——将map输出作为输入传给reducer——称为shuffle。shuffle属于不断被优化和改进的代码库的一部分,从许多方面来看,shuffle是MapReduce的“心脏”,是奇迹发生的地方。事实上,shuffle这个说法并不准确。因为在某些语境中,它只代表reduce任务获取map输出的这部分过程。在这里,我们将其理解为从map产生输出到reduce的消化输入的整个过程。
map端:
map函数开始产生输出时,并不是简单地将它写到磁盘。这个过程更复杂,它利用缓冲的方式写到内存缓冲区,并出于效率的考虑进行预排序(步骤1)。map的输出结果是由collector处理的,所以map端的shuffle过程包含在collect函数对map输出结果的处理过程中。
每个map任务都有一个环形内存缓冲区,用于存储任务的输出,默认情况下,缓冲区的大小为100MB,此值可以通过改变io.sort.mb属性来调整。一旦缓冲内容达到阀值(io.sort.spill.percent,默认为0.80,或80%),一个后台线程便开始把内容溢写(spill)到磁盘中。在写磁盘过程中,map输出继续被写到缓冲区,但如果在此期间缓冲区被填满,map会阻塞直到写磁盘过程完成。
final int kvnext = (kvindex + 1) % kvoffsets.length;
do{ //在环形缓冲区中,如果下一个空闲位置同起始位置相等,那么缓冲区已满 kvfull = kvnext ==kvstart; //环形缓冲区的内容是否达到写出的阀值 final Boolean kvsoftlimit = ((kvnext > kvend ) ? kvnext – kvend > softRecordLimit : kvend – kvnext <= kvoffsets.length – softRecordLimit ); //达到阀值,写出缓冲区内容,形成spill文件 if(kvstart == kvend && kvsoftlimit ){ startspill(); } //如果缓冲区满,则map任务等待写出过程结束 if( kvfull ){ while ( kvstart != kvend ){ reporter.progress(); spillDone.await(); } } }
写磁盘将按轮询方式写到mapred.local.dir属性指定的作业特定子目录中的目录中。
在collect函数中将缓冲区中的内容写出前会调用sortAndSpill函数。sortAndSpill函数每被调用一次就会创建一个spill文件(步骤2),然后按照key值对需要写出的数据进行排序(步骤3),如果有多个reduce任务,则每个map任务都会对其输出进行分区(partition),即为每个reduce任务建立一个分区。每个分区有许多键(及其对应值),但每个键对应的键/值对记录都在同一分区中。分区由用户定义的分区函数控制,但通常用默认的分区器(partitioner,有时也被叫做分区函数)通过哈希函数来分区,按照划分的顺序将所有需要写出的结果溢写到这个spill中(步骤4或步骤5)。
如果用户作业配置了combiner类,那么在写出过程中会先调用combineAndSpill()再写出,对结果进行进一步的合并(combine)是为了让map的输出数据更加紧凑(步骤4)。
但是并不是所有的项目都可以添加combiner函数。例如,计算气温的最大值,max(0,20,10,25,15) = max(max(0,20,10),max(25,15)) = max(20,25) = 25,这是没有问题的,但是计算气温的平均值就不行了。mean(0,20,10,25,15) = 14,
而combiner不能取代reduce函数:
mean(mean(0,20,10),mean(25,15)) = mean(10,20) = 15
为什么呢?我们仍然需要reduce函数来处理不同map输出中具有相同键的记录。但是combiner能有效减少map和reduce之间的数据传输量,在MapReduce作业中使用combiner是需要慎重考虑的。
sortAndSpill函数的执行过程可以参考下面sortAndSpill函数的代码。
//创建spill文件 Path filename = mapOutputFile.getSpillFileForWrite(getTaskID() , numSpills , size ); out = rfs.create(filename); ……. //按照key值对待写出的数据进行排序 sorter.sort( MapOutputBuffer.this , kvstart , endPosition , reporter ); …….. //按照划分将数据写入文件 for ( int i = 0 ; i < partitions ; ++ i ){ IFile.Writer< K , V > writer = null ; long segmentStart = out.getPos(); writer = new Writer< K , V >(job , out , keyClass , valClass , codec ); //如果没有没有配置combiner类,数据直接写入文件 if( null == combinerClass ){ ……. } else{ …….. //如果配置了combiner类,先调用combineAdnSpill函数后再写入文件 combineAndSpill( kvIter , combineInputCounter ); } }
这里需要注意的是,combine函数要做的一般就是reducer要做的事,先处理部分数据,再在reducer中集中处理所有的数据,这样传输给reducer的数据会减少,reducer要做的工作量也会减少。其实这里面还有一个集聚的过程,这个过程不是combine,是系统默认进行的,它会将map的输出中相同的key的value聚集成value-list(这里的聚集通过实验发现,map输出到内存缓冲区,经过sort,partition过程形成排好序的列表,但是key和value还是一样的,只是顺序改变了而已,即使有了combine,combine也是执行reduce函数的动作(这里要看combine的class设置成什么,如果是job.setCombinerClass(Reduce.class),combine则执行reduce函数的动作,而数据在输入给combine之前没有进行聚集,所以我认为聚集的过程是在溢写到磁盘文件中进行的,或者在磁盘中的多个splil文件进行merge合并的时候进行的。)。
显然,直接将每个map生成的众多spill文件(因为map过程中,每一次缓冲区写出都会产生一个spill文件)交给reduce处理不现实。所以在每个map任务结束之后在map的TaskTracker上还会执行合并操作(merge)(步骤6),这个操作的主要目的是将map生成的众多spill文件中的数据按照划分重新组织,以便于reduce处理。主要做法是针对指定的分区,从各个spill文件中拿出属于同一个分区的所有数据,然后将它们合并在一起,并写入一个已分区且已排序的map输出文件中。最后每个map只生成一个输出文件。
待唯一的已分区且已排序的map输出文件写入最后一条记录后,map端的shuffle阶段就结束了。下面就进入reduce端的shuffle阶段。
reduce端:
在reduce端,shuffle阶段可以分成三个阶段:复制map输出、排序合并、reduce处理。
map输出文件位于运行map任务的TaskTracker的本地磁盘(注意,尽管map输出经常写到map TaskTracker的本地磁盘,但reduce输出并不这样),现在,TaskTtracker需要为分区文件运行reduce任务。更进一步,reduce任务需要集群上若干个map任务的map输出作为其特殊的分区文件。每个map任务的完成时间可能不同,因此只要有一个任务完成,reduce任务就开始复制其输出。也就是reduce任务的复制阶段(步骤7)。reduce任务有少量复制线程,因此能够并行取得map输出,默认值是5个线程。
reducer如何知道要从哪个TaskTracker取得map输出呢?map任务成功完成后,它们会通知其父TaskTracker状态已更新,然后TaskTracker进而通知JobTracker。这些通知在心跳通信机制中传输。因此,对于指定作业,JobTracker知道map输出和TaskTracker之间的映射关系。reducer中的一个线程定期询问JobTracker以便获取map输出的位置,直到它获得所有输出位置。
由于reducer可能失败,因此TaskTracker并没有在第一个reducer检索到map输出时就立即从磁盘上删除它们。相反,TaskTracker会等待,直到JobTracker告知它们可以删除map输出,这是作业完成后执行的。
如果map输出相当小,则会被复制到执行reduce任务的TaskTracker节点的内存中,以便进一步的处理,否则输出被复制到磁盘中。
一旦内存缓冲区达到阀值大小或达到map输出阀值,则合并后溢出写到磁盘中。随着磁盘上副本的增多,后台线程会将这些从各个map TaskTracker上复制的map输出文件(无论在内存还是在磁盘上)进行整合,合并为更大的、排好序的文件,并维持数据原来的顺序(步骤8)。这会为后面的合并节省一些时间。注意,为了合并,压缩的map输出(通过map任务)都必须在内存中被解压缩。
reduce端的最后阶段就是对合并的文件进行reduce处理。reduce TaskTracker从合并的文件中按照顺序先拿出一条数据,交给reduce函数处理,然后直接将结果输出到本地的HDFS上(因为在Hadoop集群上,TaskTracker节点一般也是DataNode节点),接着继续拿出下一条数据,再进行处理。下面是reduce Task上run函数的部分代码,从这个函数可以看出整个reduce端的三个步骤。
//复制阶段,从map TaskTracker出获取map输出 boolean isLocal = “local”.equals(job.get(“mapred.job.tracker”,”local”)); if( !isLocal ){ reduceCopier = new ReduceCopier(umbilical , job ); if ( ! reduceCopier.fetchOutpus() ){ ………. } } //复制阶段结束 copyPhase.complete(); //合并阶段,将得到的map输出合并 setPhase(TaskStatus.Phase.SORT); ………. //合并阶段结束 sortPhase.complete(); //reduce阶段 setPhase(TaskStatus.Phase.REDUCE); … …. Reducer reducer = ReflectionUtils.newInstance(job.getReducerClass() , job); … … //逐个读出每一条记录,然后调用Reducer的reduce函数 while ( values.more() ){ reduceInputKeyCounter.increment(1); reducer.reduce(values,getKey() , values , collector , reporter); values.nextKey(); values.informReduceProgress(); } values.informReduceProgress(); } reducer.close(); out.close(reporter); done(umbilical); }