创建list分区:
create table list_part_tab (id number,deal_date date,area_code number,nbr number,contents varchar2(4000))
partition by list (area_code)
(
partition p_591 values (591),
partition p_592 values (592),
partition p_593 values (593),
partition p_594 values (594),
partition p_595 values (595),
partition p_596 values (596),
partition p_597 values (597),
partition p_598 values (598),
partition p_599 values (599),
partition p_other values (DEFAULT)
);
插入数据:
insert into list_part_tab (id,deal_date,area_code,nbr,contents)
select rownum,
to_date( to_char(sysdate-365,'J')+TRUNC(DBMS_RANDOM.VALUE(0,365)),'J'),
ceil(dbms_random.value(590,599)),
ceil(dbms_random.value(18900000001,18999999999)),
rpad('*',400,'*')
from dual
connect by rownum <= 100000;
commit;
创建索引:
create index idx_list_part_id on list_part_tab (id) ;
create index idx_list_part_nbr on list_part_tab (nbr) local;
收集统计信息:
exec dbms_stats.gather_table_stats(ownname => 'LJB',tabname => 'LIST_PART_TAB',estimate_percent => 10,method_opt=> 'for all indexed columns',cascade=>TRUE) ;
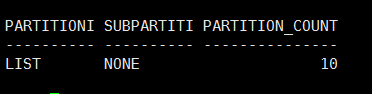
该表是否是分区表,分区表的分区类型是什么,是否有子分区,分区总数有多少:
select partitioning_type,
subpartitioning_type,
partition_count
from user_part_tables
where table_name ='LIST_PART_TAB';
该分区表在哪一列上建分区,有无多列联合建分区:
select column_name,
object_type,
column_position
from user_part_key_columns
where name ='LIST_PART_TAB';

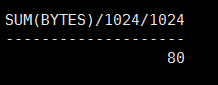
该分区表有多大:
select sum(bytes) / 1024 / 1024
from user_segments
where segment_name ='LIST_PART_TAB';
该分区表各分区分别有多大,各个分区名是什么:
select partition_name,
segment_type,
bytes
from user_segments
where segment_name ='LIST_PART_TAB';

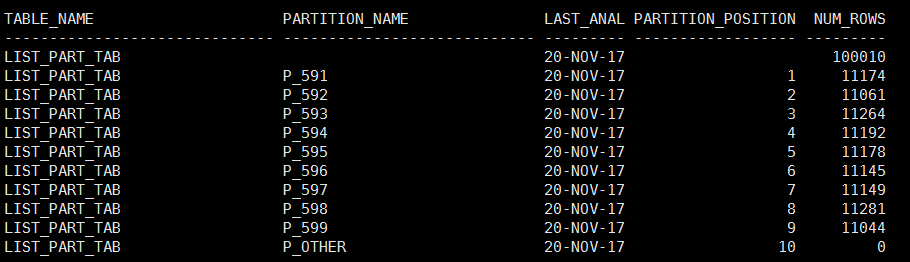
该分区表的统计信息收集情况:
select table_name,
partition_name,
last_analyzed,
partition_position,
num_rows
from user_tab_statistics t
where table_name ='LIST_PART_TAB';
查该分区表有无索引,分别什么类型,全局索引是否失效,此外还可看统计信息收集情况:
select table_name,
index_name,
last_analyzed,
blevel,
num_rows,
leaf_blocks,
distinct_keys,
status
from user_indexes
where table_name ='LIST_PART_TAB';

该分区表在哪些列上建了索引:
select index_name,
column_name,
column_position
from user_ind_columns
where table_name = 'LIST_PART_TAB';

该分区表上的各索引分别有多大:
select segment_name,segment_type,sum(bytes)/1024/1024
from user_segments
where segment_name in
(select index_name
from user_indexes
where table_name ='LIST_PART_TAB')
group by segment_name,segment_type ;

该分区表的索引段的分配情况:
select segment_name
partition_name,
segment_type,
bytes
from user_segments
where segment_name in
(select index_name
from user_indexes
where table_name ='LIST_PART_TAB');

分区索引相关信息及统计信息、是否失效查看:
select t2.table_name,
t1.index_name,
t1.partition_name,
t1.last_analyzed,
t1.blevel,
t1.num_rows,
t1.leaf_blocks,
t1.status
from user_ind_partitions t1, user_indexes t2
where t1.index_name = t2.index_name
and t2.table_name='LIST_PART_TAB';
