问题:
从同一个Kafka里消费数据做一个WordCount,flink,Kafkaconsumer 得到的结果都是正常的,而我自己写的sparkstreaming 确跟正常数据量差了10倍左右
解决:
总结一句话:一定要听官网的话!!!
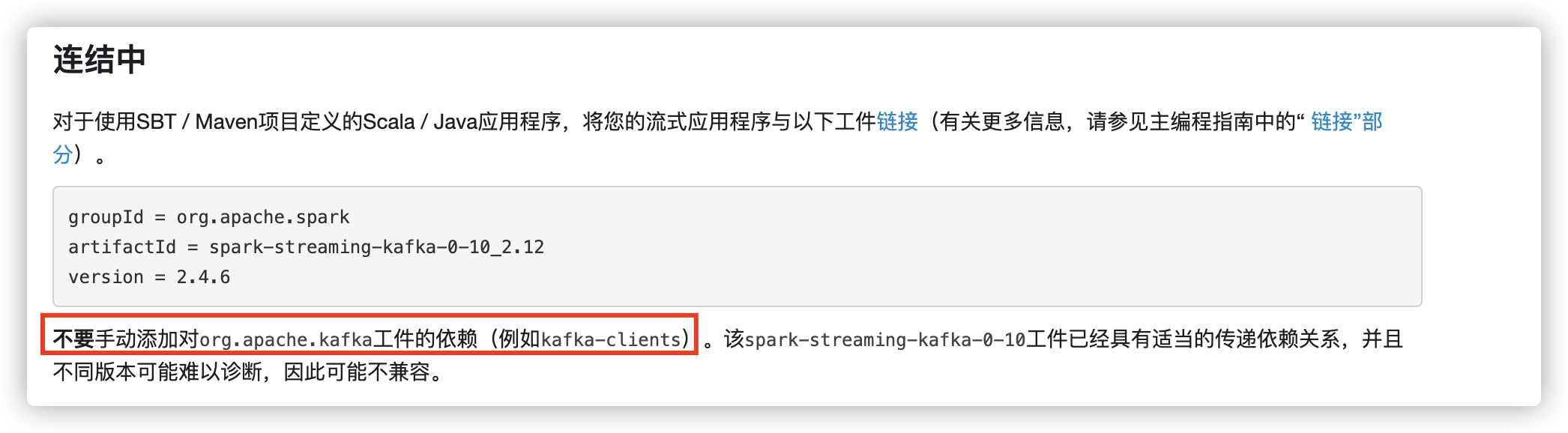
http://spark.apache.org/docs/2.4.6/streaming-kafka-0-10-integration.html

复盘一下当时的操作:我把jar包放到集群上去跑时,报了个java.lang.NoClassDefFoundError: org/apache/spark/streaming/kafka010/KafkaUtils$
当时一想,这不差个Kafka client 吗,就自己加了个依赖,就掉坑里了,其实spark-streaming-Kafka 里面已经集成了,所需要做的就是打包时,将它打到jar包里,再运行
其实把这个依赖包传到SPARK_HOME下应该也可以,但是我没有成功。。。