flume的配置无非就是四步:1、创建一个配置文件 2、在其中配置source,sink,Channel 的各项参数 3、连接各个组件 4、调用启动命令
配置参考官网http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html
1、针对NetCat的配置
1.1选用NetCat TCP Source
这个source可以打开一个端口号,监听端口号收到的消息!将消息的每行,封装为一个event!
配置必要的参数

1.2选用Logger Sink
采用 logger以info级别将event输出到(文件或控制台)默认输出到日志文件中,可在启动命令中加入
-Dflume.root.logger=DEBUG,console
这样就可以打印到控制台,方便测试。
配置必要参数
![]()
1.3 选用Memory Channel
将event存储在内存中的队列中!一般适用于高吞吐量的场景,但是如果agent故障,会损失阶段性的数据!
配置必要参数

1.4编写配置文件
# 命名每个组件 a1代表agent的名称 #a1.sources代表a1中配置的source,多个使用空格间隔 #a1.sinks代表a1中配置的sink,多个使用空格间隔 #a1.channels代表a1中配置的channel,多个使用空格间隔 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 配置source a1.sources.r1.type = netcat a1.sources.r1.bind = hadoop103 a1.sources.r1.port = 44444 # 配置sink a1.sinks.k1.type = logger a1.sinks.k1.maxBytesToLog=100 # 配置channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 # 绑定和连接组件 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
1.5启动命令
bin/flume-ng agent -c conf/ -n a1 -f flumeagents/netcatSource-loggersink.conf -Dflume.root.logger=DEBUG,console #参数说明: --conf/-c:表示配置文件存储在conf/目录 --name/-n:表示给agent起名为a1 --conf-file/-f:flume本次启动读取的配置文件是在job文件夹下的flume-telnet.conf文件。 -Dflume.root.logger=INFO,console :-D表示flume运行时动态修改flume.root.logger参数属性值,并将控制台日志打印级别设置为INFO级别。
日志级别包括:log、info、warn、error。console是将结果打印到控制台,方便测试
2、针对读取日志文件的配置
2.1.1选用

示例:
# 配置source a1.sources.r1.type = exec a1.sources.r1.command = tail -f /opt/module/hive/logs/hive.log
2.1.2

可选配置

示例
# 配置 spoolsource a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /home/sun9/work
2.1.3
TailDirSource以接近实时的速度监控文件中写入的新行!
TailDirSource检测文件中写入的新行,并且将每个文件tail的位置记录在一个JSON的文件中!即便agent挂掉,重启后,source从上次记录的位置继续执行tail操作!
用户可以通过修改Position文件的参数,来改变source继续读取的位置!如果postion文件丢失了,那么source会重新从每个文件的第一行开始读取(重复读)!
必须配置
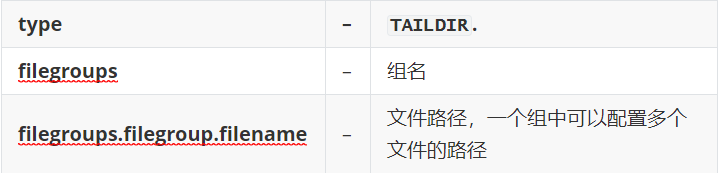
可选配置

示例
# 配置source a1.sources.r1.type = TAILDIR #多个文件用空格分开 a1.sources.r1.filegroups = f1 f2 a1.sources.r1.filegroups.f1 = /home/atguigu/a.txt a1.sources.r1.filegroups.f2 = /home/atguigu/b.txt a1.sources.r1.positionFile=/home/atguigu/taildir_position.json
2.2选用HDFS Sink
HDFS Sink负责将数据写到HDFS。
-
目前支持创建 text和SequnceFile文件!
-
-
文件可以基于时间周期性滚动或基于文件大小滚动或基于events的数量滚动
-
可以根据数据产生的时间戳或主机名对数据进行分桶或分区
-
上传的路径名可以包含 格式化的转义序列,转义序列会在文件/目录真正上传时被替换,如:hdfs://hadoop102:9000/flume/%Y%m%d/%H%M
-
如果要使用这个sink,必须已经安装了hadoop,这样flume才能使用Jar包和hdfs通信
必要配置

推荐配置
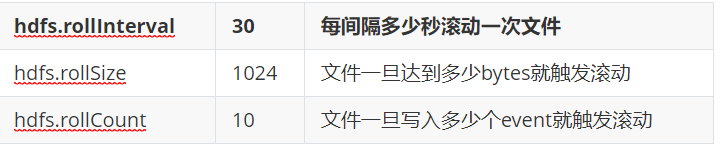
文件滚动策略
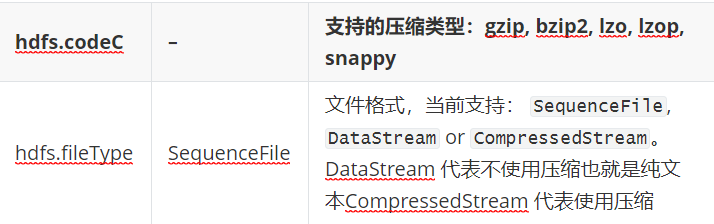
文件的类型和压缩类型:
目录的滚动策略:
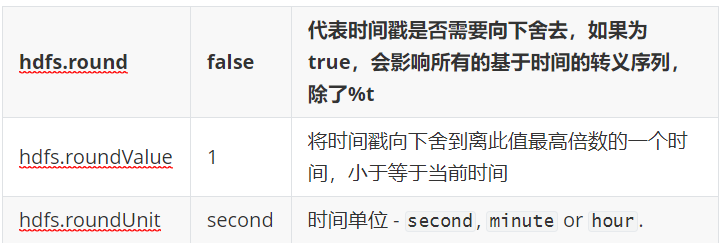
时间戳设置:
注意: 所有和时间相关的转义序列,都要求event的header中有timestamp的属性名,值为时间戳

示例:
# 配置sink a1.sinks.k1.type = hdfs #转义序列 a1.sinks.k1.hdfs.path = hdfs://hadoop102:9000/flume/%Y%m%d/%H%M #上传文件的前缀 a1.sinks.k1.hdfs.filePrefix = logs- #滚动目录 一分钟滚动一次目录 a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 1 a1.sinks.k1.hdfs.roundUnit = minute #是否使用本地时间戳 a1.sinks.k1.hdfs.useLocalTimeStamp = true #配置文件滚动 a1.sinks.k1.hdfs.rollInterval = 30 a1.sinks.k1.hdfs.rollSize = 134217700 a1.sinks.k1.hdfs.rollCount = 0 #使用文件格式存储数据 a1.sinks.k1.hdfs.fileType=DataStream
3、针对多路复用的配置
需求如下,同一个数据,既要上传到HDFS上,也要保存到本地,这就涉及到了多个flume串联的问题
3.1 flume之间传输需选用Avro Sink (Avro Sink和Avro Source是搭配使用的!)
sink将event以avro序列化的格式发送到另外一台机器的指定进程!
必要配置

# 配置sink a1.sinks.k1.type = avro a1.sinks.k1.hostname=hadoop102 a1.sinks.k1.port=12345
3.2

示例
# 配置source a1.sources.r1.type = avro a1.sources.r1.bind = hadoop102 a1.sources.r1.port = 12345
注意:在接收数据的Agent里有俩个Channel,这时还需要配置使用复制的channel选择器,此选择器会选中所有的channel,每个channel复制一个event(可以省略,默认)
a1.sources.r1.selector.type = replicating
3.3写入本地

可选配置

示例
# 配置sink a1.sinks.k1.type = file_roll a1.sinks.k1.sink.directory=/home/atguigu/flume a1.sinks.k1.sink.rollInterval=600
四、针对故障转移及负载均衡的配置
实质是一个Channel对应俩个Sink的配置,这里当然也会用到Avro Source ,Avro Sink ,但最关键的是Sink选择器
注意:启动时要先启动从机,再启动主机
4.1
故障转移的sink处理器! 这个sink处理器会维护一组有优先级的sink!默认挑选优先级最高(数值越大)的sink来处理数据!故障的sink会放入池中冷却一段时间,恢复后,重新加入到存活的池中,此时在live pool(存活的池)中选优先级最高的,接替工作!
必要配置

可选配置

示例:
a1.sinkgroups = g1 a1.sinkgroups.g1.sinks = k1 k2 a1.sinkgroups.g1.processor.type = failover a1.sinkgroups.g1.processor.priority.k1 = 5 a1.sinkgroups.g1.processor.priority.k2 = 10 a1.sinkgroups.g1.processor.maxpenalty = 10000
4.2
必要配置
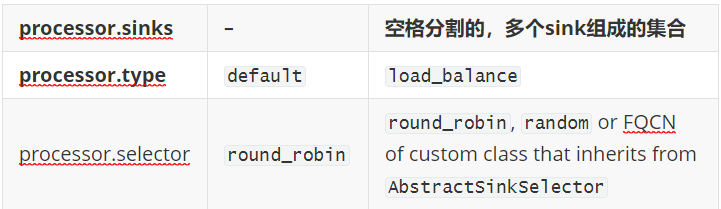
可选配置

示例:
a1.sinkgroups = g1 a1.sinkgroups.g1.sinks = k1 k2 a1.sinkgroups.g1.processor.type = load_balance a1.sinkgroups.g1.processor.selector = random
五、读取event header中的值来决定Channel

5.1
根据配置读取event header中指定key的value,根据value的映射,分配到不同的channel!
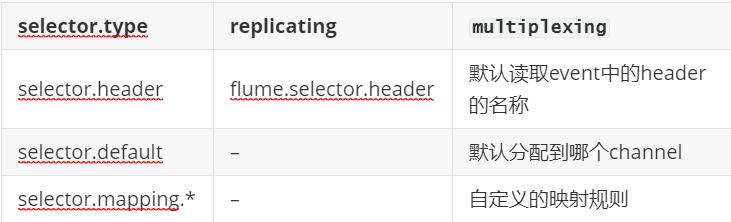
示例
a1.sources = r1 a1.channels = c1 c2 c3 c4 a1.sources.r1.selector.type = multiplexing a1.sources.r1.selector.header = state a1.sources.r1.selector.mapping.CZ = c1 a1.sources.r1.selector.mapping.US = c2 c3 a1.sources.r1.selector.default = c4
5.3

示例
a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = static a1.sources.r1.interceptors.i1.key = mykey a1.sources.r1.interceptors.i1.value = agent2
六、与Kafka对接
6.1 Kafka Sink
必要配置

可选配置

示例:
#如果要实现自动分区,往往会在拦截器处设置topic的值
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = Interceptor.MyInterceptor$Builder
# 配置sink a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.sinks.k1.kafka.topic=test3 a1.sinks.k1.useFlumeEventFormat=false
自定义拦截器代码
public class MyInterceptor implements Interceptor { @Override public void initialize() { } @Override public Event intercept(Event event) { byte[] body = event.getBody(); String s = new String(body); Map<String, String> headers = event.getHeaders(); if(s.contains("hello")){ headers.put("topic","hello"); }else{ headers.put("topic","other"); } event.setHeaders(headers); return event; } @Override public List<Event> intercept(List<Event> list) { for (Event event : list) { intercept(event); } return list; } @Override public void close() { } public static class Builder implements org.apache.flume.interceptor.Interceptor.Builder{ @Override public Interceptor build() { return new MyInterceptor(); } @Override public void configure(Context context) { } } }
6.2 Kafka Channel
为什么选择Kafkachannel: 因为kafka集群有高可用和副本机制!这样即便agent挂掉,或某个broker宕机,sink也可以立刻从新的leader上继续拉取event!
必要配置

可选配置
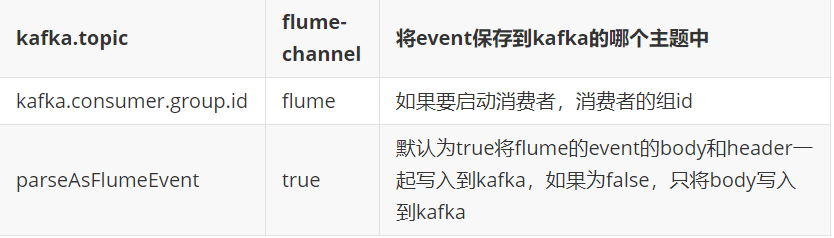
示例:
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.channels.c1.kafka.topic = topic_start a1.channels.c1.parseAsFlumeEvent = false
6.3Kafka Source
KafkaSource本质是一个可以从kafka集群的主题上消费数据的消费者!如果希望提高消费者速率,可以配置多个KafkaSource,指定多个KafkaSource有相同的组id!
必要配置

可选配置

示例:
# 配置source a1.sources.r1.type =org.apache.flume.source.kafka.KafkaSource a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.sources.r1.kafka.topics = topic_start a1.sources.r1.kafka.consumer.group.id=CG_start #kafka消费者默认从分区的最后一个位置消费,当前分区中已经有170条数据,如果不配置,只会从170之后消费 #控制kafka消费者从主题的最早的位置消费,此参数只会在一个从未提交过offset的组中生效 a1.sources.r1.kafka.consumer.auto.offset.reset=earliest
6.4File Channel
FileChannel将event存储在文件中!与memory channel 相比,不易丢数据,但效率低!
可选配置
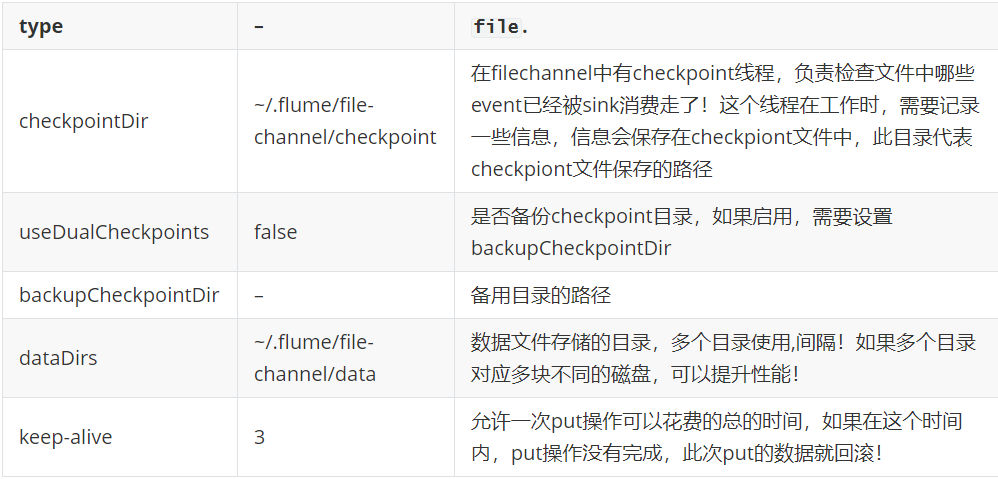
示例:
a1.channels.c1.type = file a1.channels.c1.dataDirs = /opt/module/flumedata/c1 a1.channels.c1.checkpointDir=/opt/module/flumedata/c1checkpoint a1.channels.c1.useDualCheckpoints=true a1.channels.c1.backupCheckpointDir=/opt/module/flumedata/c1backupcheckpoint
优化
正如上文提到的,
通过配置dataDirs指向多个路径,每个路径对应不同的硬盘,增大Flume吞吐量。,
checkpointDir和backupCheckpointDir也尽量配置在不同硬盘对应的目录中,保证checkpoint坏掉后,可以快速使用backupCheckpointDir恢复数据