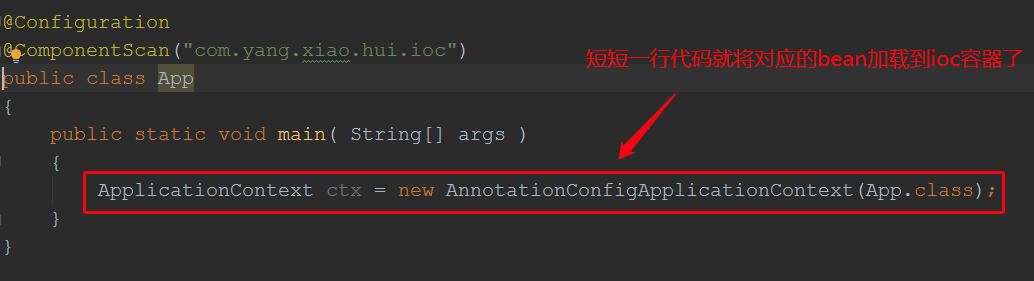
背景:我们启动主启动类后,相应的bean就被扫描进来了,原理是啥?
实现该功能的主要核心类就是:ConfigurationClassPostProcessor,我们看看他的继承体系:
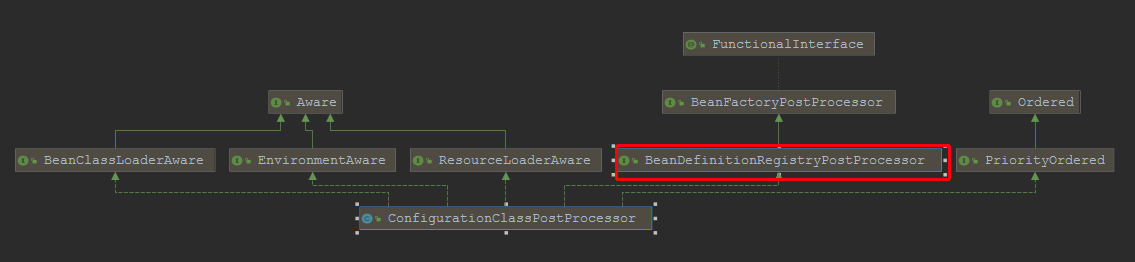
它实现了BeanDefinitionRegistryPostProcessor接口,该接口有个方法:void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException;
那么我们的核心逻辑就在该方法里面了,而该方法什么时候被执行呢? 方法执行时间点在:
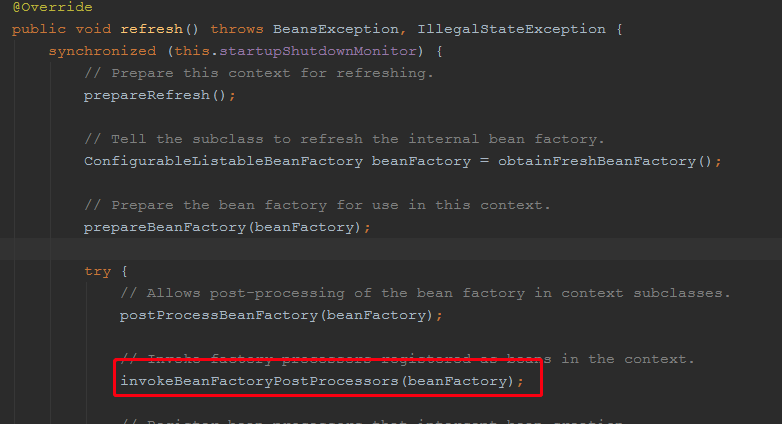
我们debug调试postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry)
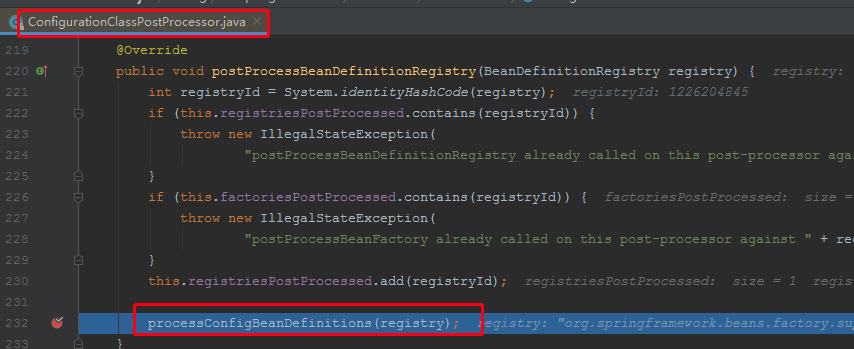
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) { List<BeanDefinitionHolder> configCandidates = new ArrayList<>();//存储所有的配置类bean定义信息 String[] candidateNames = registry.getBeanDefinitionNames();//获取容器中当前所有的beanName,这里主要的是我们的启动类App.class for (String beanName : candidateNames) {
//遍历所有的bean定义信息,判断是否是配置类,这里fullConfiguration是指被@configuration注解标注的,而liteConfigurationClass是指Componet,ComponetScan,import等注解标注的
//如果是fullconfiguration就会给对应的bean定义信息设置属性"full",相应的如果是lite就设置lite BeanDefinition beanDef = registry.getBeanDefinition(beanName); if (ConfigurationClassUtils.isFullConfigurationClass(beanDef) || ConfigurationClassUtils.isLiteConfigurationClass(beanDef)) { //这里判断有没设置过相应的属性值了 if (logger.isDebugEnabled()) { logger.debug("Bean definition has already been processed as a configuration class: " + beanDef); } } else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {//判断是否是full 或lite configuration的类,是就设置属性“full” or "lite" configCandidates.add(new BeanDefinitionHolder(beanDef, beanName)); //收集配置类 } } // Return immediately if no @Configuration classes were found if (configCandidates.isEmpty()) { //如果没有配置类,那么就不用解析了,这里我们的APP.class是配置类 return; } // Sort by previously determined @Order value, if applicable configCandidates.sort((bd1, bd2) -> { //如果有多个配置类,那就要排序,看哪个先执行 int i1 = ConfigurationClassUtils.getOrder(bd1.getBeanDefinition()); int i2 = ConfigurationClassUtils.getOrder(bd2.getBeanDefinition()); return Integer.compare(i1, i2); }); // Detect any custom bean name generation strategy supplied through the enclosing application context SingletonBeanRegistry sbr = null; if (registry instanceof SingletonBeanRegistry) { //这里我们的registry是:DefaultListableBeanFactory 实现了该接口 sbr = (SingletonBeanRegistry) registry; if (!this.localBeanNameGeneratorSet) { //如果本地没有设置beanName生成器,就从容器中获取 BeanNameGenerator generator = (BeanNameGenerator) sbr.getSingleton(CONFIGURATION_BEAN_NAME_GENERATOR); if (generator != null) { //本次测试,这里是null this.componentScanBeanNameGenerator = generator; //Component注解生成的bean,beanName应该怎么命名,默认是类名驼峰命名 this.importBeanNameGenerator = generator;//import注解注入的bean,它的beanName如何命名,默认是全限定类名 } } } if (this.environment == null) { this.environment = new StandardEnvironment(); //如果环境对象没有设置就要创建一个,用于解析一些属性,如yml里面配置的信息 } // Parse each @Configuration class 配置类解析器,用于解析配置类,metadataReaderFactory将字节码转成class对象,problemReporter用于处理异常的
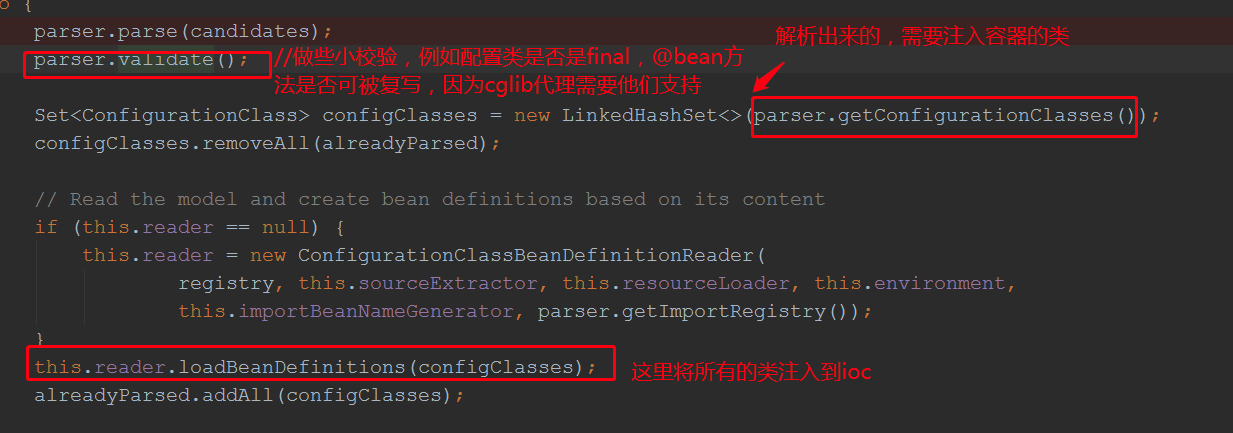
ConfigurationClassParser parser = new ConfigurationClassParser( this.metadataReaderFactory, this.problemReporter, this.environment, this.resourceLoader, this.componentScanBeanNameGenerator, registry); Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(configCandidates);//这里将list转成set是为了去重,防止通过类重复解析 Set<ConfigurationClass> alreadyParsed = new HashSet<>(configCandidates.size());//已解析的配置类 do { parser.parse(candidates);//开始解析,这里是核心,后续会分析 parser.validate();//校验解析的结果 //将解析到的所有配置类使用set去重,这里的配置类并非只是带有@configuration注解的类,而是包含@component @bean等需要被spring管理的bean Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses()); configClasses.removeAll(alreadyParsed);//移除已经解析的bean // Read the model and create bean definitions based on its content if (this.reader == null) { this.reader = new ConfigurationClassBeanDefinitionReader( registry, this.sourceExtractor, this.resourceLoader, this.environment, this.importBeanNameGenerator, parser.getImportRegistry());//用于读取ConfigurationClass信息,封装成BeanDefinition } this.reader.loadBeanDefinitions(configClasses); 将BeanDefinition 注册到BeanFacotry中,也就是ioc容器 alreadyParsed.addAll(configClasses);//添加已经处理过的配置类到alreadyParsed集合 candidates.clear();//清空 if (registry.getBeanDefinitionCount() > candidateNames.length) { //整个if的意思是,这些新加的bean,有些也是配置bean,他们有可能也注入了其他的bean,因此他们也要被解析 String[] newCandidateNames = registry.getBeanDefinitionNames(); Set<String> oldCandidateNames = new HashSet<>(Arrays.asList(candidateNames)); Set<String> alreadyParsedClasses = new HashSet<>(); for (ConfigurationClass configurationClass : alreadyParsed) { alreadyParsedClasses.add(configurationClass.getMetadata().getClassName()); } for (String candidateName : newCandidateNames) { if (!oldCandidateNames.contains(candidateName)) { BeanDefinition bd = registry.getBeanDefinition(candidateName); if (ConfigurationClassUtils.checkConfigurationClassCandidate(bd, this.metadataReaderFactory) && !alreadyParsedClasses.contains(bd.getBeanClassName())) { candidates.add(new BeanDefinitionHolder(bd, candidateName)); } } } candidateNames = newCandidateNames; } } while (!candidates.isEmpty()); // Register the ImportRegistry as a bean in order to support ImportAware @Configuration classes if (sbr != null && !sbr.containsSingleton(IMPORT_REGISTRY_BEAN_NAME)) { sbr.registerSingleton(IMPORT_REGISTRY_BEAN_NAME, parser.getImportRegistry()); //注册一个ImportAware } if (this.metadataReaderFactory instanceof CachingMetadataReaderFactory) { // Clear cache in externally provided MetadataReaderFactory; this is a no-op // for a shared cache since it'll be cleared by the ApplicationContext. ((CachingMetadataReaderFactory) this.metadataReaderFactory).clearCache(); //清空缓存,因为解析过程,读取了很字节码相关的数据,解析完后,就可以清空了 } }
小结:上面整个方法核心就是循环解析所有的配置类:所以我们主要分析解析的过程就可以了:
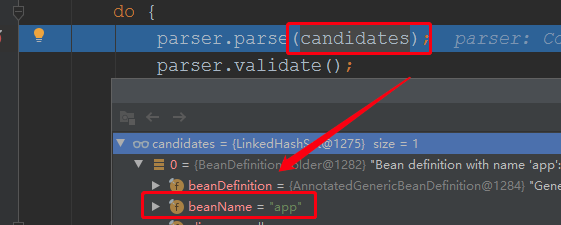
接下来分析解析过程:
public void parse(Set<BeanDefinitionHolder> configCandidates) { for (BeanDefinitionHolder holder : configCandidates) { //遍历所有的配置类,根据所属的类型不一样,调用不同的解析方法 BeanDefinition bd = holder.getBeanDefinition(); try { if (bd instanceof AnnotatedBeanDefinition) { parse(((AnnotatedBeanDefinition) bd).getMetadata(), holder.getBeanName()); } else if (bd instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) bd).hasBeanClass()) { parse(((AbstractBeanDefinition) bd).getBeanClass(), holder.getBeanName()); } else { parse(bd.getBeanClassName(), holder.getBeanName()); } } catch (BeanDefinitionStoreException ex) { throw ex; } catch (Throwable ex) { throw new BeanDefinitionStoreException( "Failed to parse configuration class [" + bd.getBeanClassName() + "]", ex); } }

protected void processConfigurationClass(ConfigurationClass configClass) throws IOException {
//下面这个是用于处理Condition注解的,尤其是在springboot中,用到大量的ConditionOnMissBean Conditionxx等 if (this.conditionEvaluator.shouldSkip(configClass.getMetadata(), ConfigurationPhase.PARSE_CONFIGURATION)) { return; //condition条件不匹配,所以就要跳过,也就是不用解析了 } ConfigurationClass existingClass = this.configurationClasses.get(configClass); //这是一个map集合,用于存储已经处理过的配置类 if (existingClass != null) { if (configClass.isImported()) { //判断configClass配置类是不是通过@import注解导入的 if (existingClass.isImported()) {//如果已经存在的配置类也是@import注解导入的,就合并 existingClass.mergeImportedBy(configClass); //importedBy 是一个set集合 } // Otherwise ignore new imported config class; existing non-imported class overrides it. return; } else { // Explicit bean definition found, probably replacing an import. // Let's remove the old one and go with the new one. this.configurationClasses.remove(configClass); //去除旧的保留新的 this.knownSuperclasses.values().removeIf(configClass::equals); } } // Recursively process the configuration class and its superclass hierarchy. SourceClass sourceClass = asSourceClass(configClass); //包装下,用于递归调用下面的解析方法,这里递归是为了解析父类,或者父类的父类 do { sourceClass = doProcessConfigurationClass(configClass, sourceClass);//解析配置类 } while (sourceClass != null); this.configurationClasses.put(configClass, configClass); //将已经解析的配置类存起来 }
上面的核心是递归解析方法:doProcessConfigurationClass(configClass, sourceClass);
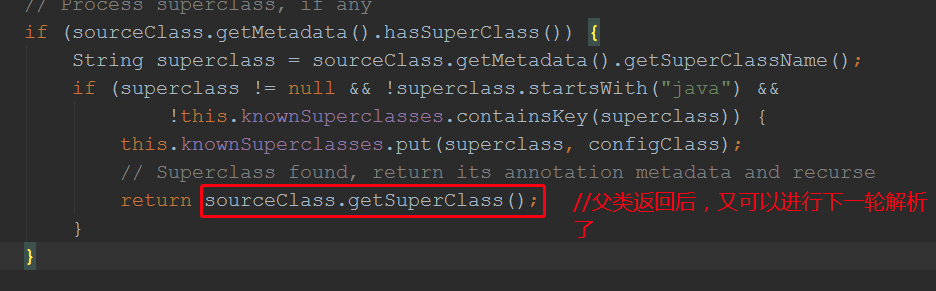
@Nullable protected final SourceClass doProcessConfigurationClass(ConfigurationClass configClass, SourceClass sourceClass) throws IOException { if (configClass.getMetadata().isAnnotated(Component.class.getName())) { //解析componet注解 // Recursively process any member (nested) classes first processMemberClasses(configClass, sourceClass); } // Process any @PropertySource annotations for (AnnotationAttributes propertySource : AnnotationConfigUtils.attributesForRepeatable( //解析 @PropertySource注解 sourceClass.getMetadata(), PropertySources.class, org.springframework.context.annotation.PropertySource.class)) { if (this.environment instanceof ConfigurableEnvironment) { processPropertySource(propertySource); } else { logger.info("Ignoring @PropertySource annotation on [" + sourceClass.getMetadata().getClassName() + "]. Reason: Environment must implement ConfigurableEnvironment"); } } // Process any @ComponentScan annotations Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable( //解析ComponnetScan 和ComponeScans注解 sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class); if (!componentScans.isEmpty() && !this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) { for (AnnotationAttributes componentScan : componentScans) { // The config class is annotated with @ComponentScan -> perform the scan immediately Set<BeanDefinitionHolder> scannedBeanDefinitions = this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName()); // Check the set of scanned definitions for any further config classes and parse recursively if needed for (BeanDefinitionHolder holder : scannedBeanDefinitions) { BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition(); if (bdCand == null) { bdCand = holder.getBeanDefinition(); } if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) { parse(bdCand.getBeanClassName(), holder.getBeanName()); } } } } // Process any @Import annotations processImports(configClass, sourceClass, getImports(sourceClass), true); //解析Import注解 // Process any @ImportResource annotations AnnotationAttributes importResource = AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class); //解析importResource注解,该注解是用于解析xml的 if (importResource != null) { String[] resources = importResource.getStringArray("locations"); Class<? extends BeanDefinitionReader> readerClass = importResource.getClass("reader"); for (String resource : resources) { String resolvedResource = this.environment.resolveRequiredPlaceholders(resource); configClass.addImportedResource(resolvedResource, readerClass); } } // Process individual @Bean methods Set<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(sourceClass); //解析@bean注解标注的方法 for (MethodMetadata methodMetadata : beanMethods) { configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass)); } // Process default methods on interfaces processInterfaces(configClass, sourceClass); //解析接口,为何呢?因为jdk8.0后支持默认方法,默认方法也可以作为注入bean的方法 // Process superclass, if any if (sourceClass.getMetadata().hasSuperClass()) { String superclass = sourceClass.getMetadata().getSuperClassName(); //判断有没父类,有父类,父类也要被解析 if (superclass != null && !superclass.startsWith("java") && !this.knownSuperclasses.containsKey(superclass)) { this.knownSuperclasses.put(superclass, configClass); // Superclass found, return its annotation metadata and recurse return sourceClass.getSuperClass(); } } // No superclass -> processing is complete return null; }
小结:上面主要是解析各个注解,接下来分析每一个解析方法:
1.componnet注解的解析:

这个是为了解析内部类,如果内部类也要注入容器,例如:
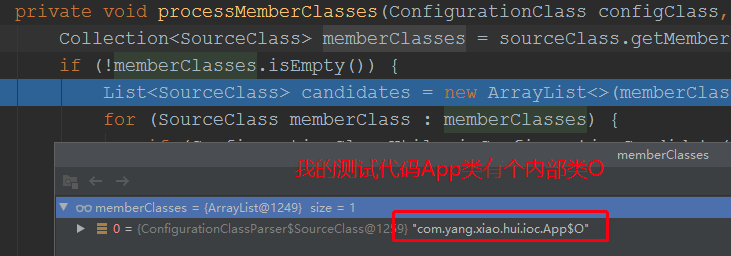
private void processMemberClasses(ConfigurationClass configClass, SourceClass sourceClass) throws IOException { Collection<SourceClass> memberClasses = sourceClass.getMemberClasses();//获取sourceClass的所有内部类,并封装成SourceClass if (!memberClasses.isEmpty()) { List<SourceClass> candidates = new ArrayList<>(memberClasses.size()); for (SourceClass memberClass : memberClasses) { if (ConfigurationClassUtils.isConfigurationCandidate(memberClass.getMetadata()) && //遍历判断是否是配置类,也就是是否含有@Configruation/@componet/@Import等注解 !memberClass.getMetadata().getClassName().equals(configClass.getMetadata().getClassName())) { candidates.add(memberClass);//如果是,这个就是我们要解析的类 } } OrderComparator.sort(candidates);//排序 for (SourceClass candidate : candidates) { if (this.importStack.contains(configClass)) { //判断是否已经解析过了,如果是,就是循环解析了 this.problemReporter.error(new CircularImportProblem(configClass, this.importStack)); } else { this.importStack.push(configClass);//入栈 try { processConfigurationClass(candidate.asConfigClass(configClass));//这里的意思是,内部类也可能导入其他bean,或者它的父类会导入其他bean,这里就是要对其进行解析 } finally { this.importStack.pop(); } } } } }
2.@PropertySource注解的解析 该注解是用于导入一些配置信息的,这个不是我们本次分析的重点
private void processPropertySource(AnnotationAttributes propertySource) throws IOException { String name = propertySource.getString("name"); if (!StringUtils.hasLength(name)) { name = null; } String encoding = propertySource.getString("encoding"); if (!StringUtils.hasLength(encoding)) { encoding = null; } String[] locations = propertySource.getStringArray("value"); //配置文件的路径 Assert.isTrue(locations.length > 0, "At least one @PropertySource(value) location is required"); boolean ignoreResourceNotFound = propertySource.getBoolean("ignoreResourceNotFound"); Class<? extends PropertySourceFactory> factoryClass = propertySource.getClass("factory"); PropertySourceFactory factory = (factoryClass == PropertySourceFactory.class ? DEFAULT_PROPERTY_SOURCE_FACTORY : BeanUtils.instantiateClass(factoryClass));//解析配置文件的工厂 for (String location : locations) { try { String resolvedLocation = this.environment.resolveRequiredPlaceholders(location);//处理占位符 Resource resource = this.resourceLoader.getResource(resolvedLocation);//资源加载器去加载 addPropertySource(factory.createPropertySource(name, new EncodedResource(resource, encoding)));//处理对应的属性 } catch (IllegalArgumentException | FileNotFoundException | UnknownHostException ex) { // Placeholders not resolvable or resource not found when trying to open it if (ignoreResourceNotFound) { if (logger.isInfoEnabled()) { logger.info("Properties location [" + location + "] not resolvable: " + ex.getMessage()); } } else { throw ex; } } } }
3.ComponentScans 和ComponetScan注解的解析
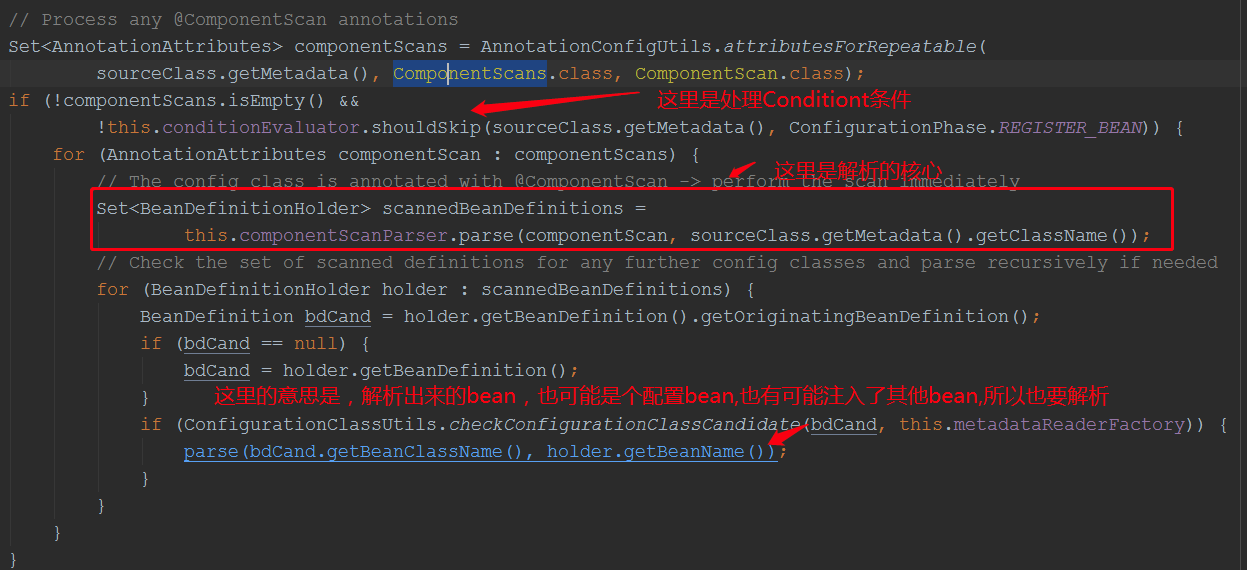
我们看核心代码:this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
public Set<BeanDefinitionHolder> parse(AnnotationAttributes componentScan, final String declaringClass) { //解析注解里面的各种参数 ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(this.registry, componentScan.getBoolean("useDefaultFilters"), this.environment, this.resourceLoader); //扫描器是核心 Class<? extends BeanNameGenerator> generatorClass = componentScan.getClass("nameGenerator"); boolean useInheritedGenerator = (BeanNameGenerator.class == generatorClass); scanner.setBeanNameGenerator(useInheritedGenerator ? this.beanNameGenerator : BeanUtils.instantiateClass(generatorClass));//设置beanName生成器 ScopedProxyMode scopedProxyMode = componentScan.getEnum("scopedProxy"); //这里是Scope注解相关内容,我专门有个博客讲解该注解的作用 if (scopedProxyMode != ScopedProxyMode.DEFAULT) { scanner.setScopedProxyMode(scopedProxyMode); } else { Class<? extends ScopeMetadataResolver> resolverClass = componentScan.getClass("scopeResolver"); scanner.setScopeMetadataResolver(BeanUtils.instantiateClass(resolverClass)); } scanner.setResourcePattern(componentScan.getString("resourcePattern")); for (AnnotationAttributes filter : componentScan.getAnnotationArray("includeFilters")) { //@ComponentScan可以配置扫描什么类,和排除什么类 for (TypeFilter typeFilter : typeFiltersFor(filter)) { scanner.addIncludeFilter(typeFilter); } } for (AnnotationAttributes filter : componentScan.getAnnotationArray("excludeFilters")) { for (TypeFilter typeFilter : typeFiltersFor(filter)) { scanner.addExcludeFilter(typeFilter); } } boolean lazyInit = componentScan.getBoolean("lazyInit"); //是否扫描到的类都是要懒加载 if (lazyInit) { scanner.getBeanDefinitionDefaults().setLazyInit(true); } Set<String> basePackages = new LinkedHashSet<>(); String[] basePackagesArray = componentScan.getStringArray("basePackages"); //包名是一个数组 for (String pkg : basePackagesArray) { String[] tokenized = StringUtils.tokenizeToStringArray(this.environment.resolvePlaceholders(pkg), ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS); Collections.addAll(basePackages, tokenized); } for (Class<?> clazz : componentScan.getClassArray("basePackageClasses")) {//如果是指定扫描哪些类,就将类名转成包名 basePackages.add(ClassUtils.getPackageName(clazz)); } if (basePackages.isEmpty()) { basePackages.add(ClassUtils.getPackageName(declaringClass)); } scanner.addExcludeFilter(new AbstractTypeHierarchyTraversingFilter(false, false) {//添加过滤器用于支持excludeFilters属性 @Override protected boolean matchClassName(String className) { return declaringClass.equals(className); } }); return scanner.doScan(StringUtils.toStringArray(basePackages));//开始扫描 }
上面主要是处理@ComponetScan注解的属性,我们看看 scanner.doScan(StringUtils.toStringArray(basePackages))
protected Set<BeanDefinitionHolder> doScan(String... basePackages) { Assert.notEmpty(basePackages, "At least one base package must be specified"); Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>(); for (String basePackage : basePackages) { //遍历包名 Set<BeanDefinition> candidates = findCandidateComponents(basePackage);//这里是核心,后续会讲解到 for (BeanDefinition candidate : candidates) { //遍历获取到的bean定义信息,然后处理@Scope注解,该注解我有博客专门分析 ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate); candidate.setScope(scopeMetadata.getScopeName()); String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry); if (candidate instanceof AbstractBeanDefinition) { postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);//设置一些默认的信息,通过扫描获取的信息还不够 } if (candidate instanceof AnnotatedBeanDefinition) {
//处理一些通用注解,如@lazy @DependenOn @primary AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate); } if (checkCandidate(beanName, candidate)) { BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName); definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry); //@Scope注解相关处理 beanDefinitions.add(definitionHolder); registerBeanDefinition(definitionHolder, this.registry); } } } return beanDefinitions; }
继续跟进: Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
public Set<BeanDefinition> findCandidateComponents(String basePackage) { if (this.componentsIndex != null && indexSupportsIncludeFilters()) {//这里涉及的spring 5.0后新增@Indexed对于扫描的优化 需要添加配置 return addCandidateComponentsFromIndex(this.componentsIndex, basePackage); } else { return scanCandidateComponents(basePackage);//我们看这里逻辑 } }
private Set<BeanDefinition> scanCandidateComponents(String basePackage) { Set<BeanDefinition> candidates = new LinkedHashSet<>(); try { String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX + resolveBasePackage(basePackage) + '/' + this.resourcePattern; //将包名转成路径名成,resourcePattern在这里是"**.class",这样就是扫描路径下所有的class文件 Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);//通过路径,获取资源,里面封装了File文件类 boolean traceEnabled = logger.isTraceEnabled(); boolean debugEnabled = logger.isDebugEnabled(); for (Resource resource : resources) { if (traceEnabled) { logger.trace("Scanning " + resource); } if (resource.isReadable()) { try { MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);//使用ASM技术,通过输入流的方式,读取class文件内容 if (isCandidateComponent(metadataReader)) {//判断是否有Componet注解标注了,如果是,就是我们要找的 ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);//将读到的信息封装成bean定义信息 sbd.setResource(resource); sbd.setSource(resource); if (isCandidateComponent(sbd)) { //如果不是抽象的或者是抽象但又@lookup注解标注的方法 if (debugEnabled) { logger.debug("Identified candidate component class: " + resource); } candidates.add(sbd); } else { if (debugEnabled) { logger.debug("Ignored because not a concrete top-level class: " + resource); } } } else { if (traceEnabled) { logger.trace("Ignored because not matching any filter: " + resource); } } } catch (Throwable ex) { throw new BeanDefinitionStoreException( "Failed to read candidate component class: " + resource, ex); } } else { if (traceEnabled) { logger.trace("Ignored because not readable: " + resource); } } } } catch (IOException ex) { throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex); } return candidates;//返回扫描到的所有bean }
4.@import注解的解析processImports(configClass, sourceClass, getImports(sourceClass), true);
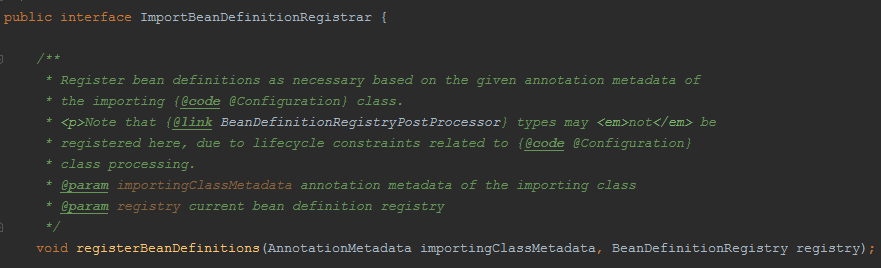
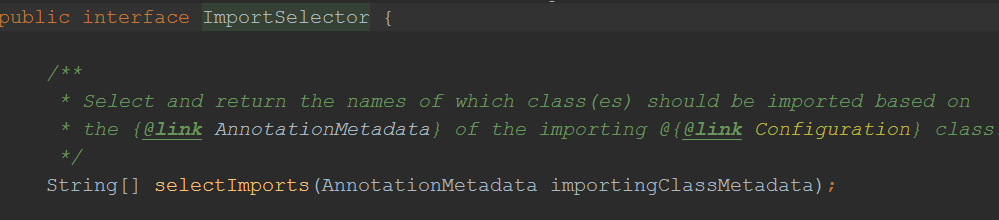
背景知识:@import导入的类,分成三类,一类是实现ImportSelector接口的,该接口有个方法,返回需要注入ico容器的类的权限定类名,是一个数组,另一类是实现ImportBeanDefinitionRegistrar接口的,这个接口有一个
registerBeanDefinitions方法,也可以向ioc容器注入不同的bean,最后一类就是没实现上面接口:

private void processImports(ConfigurationClass configClass, SourceClass currentSourceClass, Collection<SourceClass> importCandidates, boolean checkForCircularImports) { if (importCandidates.isEmpty()) { return; } if (checkForCircularImports && isChainedImportOnStack(configClass)) { this.problemReporter.error(new CircularImportProblem(configClass, this.importStack)); } else { this.importStack.push(configClass); try { for (SourceClass candidate : importCandidates) { if (candidate.isAssignable(ImportSelector.class)) { //处理ImportSelector,就是获取数组的信息 // Candidate class is an ImportSelector -> delegate to it to determine imports Class<?> candidateClass = candidate.loadClass();//获取class对象 ImportSelector selector = BeanUtils.instantiateClass(candidateClass, ImportSelector.class);//反射创建对象 ParserStrategyUtils.invokeAwareMethods( selector, this.environment, this.resourceLoader, this.registry); if (selector instanceof DeferredImportSelector) { this.deferredImportSelectorHandler.handle(configClass, (DeferredImportSelector) selector); } else { String[] importClassNames = selector.selectImports(currentSourceClass.getMetadata()); //获取到数组的信息 Collection<SourceClass> importSourceClasses = asSourceClasses(importClassNames); processImports(configClass, currentSourceClass, importSourceClasses, false);//递归调用,看看这些导入的类是否也实现了对应接口 } else if (candidate.isAssignable(ImportBeanDefinitionRegistrar.class)) { // Candidate class is an ImportBeanDefinitionRegistrar -> // delegate to it to register additional bean definitions Class<?> candidateClass = candidate.loadClass(); //获取class对象,然后反射创建对象 ImportBeanDefinitionRegistrar registrar = BeanUtils.instantiateClass(candidateClass, ImportBeanDefinitionRegistrar.class); ParserStrategyUtils.invokeAwareMethods( registrar, this.environment, this.resourceLoader, this.registry); configClass.addImportBeanDefinitionRegistrar(registrar, currentSourceClass.getMetadata());//收集起来,后续统一调用 } else { // Candidate class not an ImportSelector or ImportBeanDefinitionRegistrar -> // process it as an @Configuration class this.importStack.registerImport( currentSourceClass.getMetadata(), candidate.getMetadata().getClassName()); processConfigurationClass(candidate.asConfigClass(configClass)); //如果都没实现对应接口,那就当作普通的Configuration类,因为该类也可能注入其他类 } } } catch (BeanDefinitionStoreException ex) { throw ex; } catch (Throwable ex) { throw new BeanDefinitionStoreException( "Failed to process import candidates for configuration class [" + configClass.getMetadata().getClassName() + "]", ex); } finally { this.importStack.pop(); } } }
5.@ImportResource该注解是解析xml的 使用的是XmlBeanDefinitionReader 去读取,这里不具体分析该解析过程,因为xml方式已经被淘汰了
6. @Bean methods

private Set<MethodMetadata> retrieveBeanMethodMetadata(SourceClass sourceClass) { AnnotationMetadata original = sourceClass.getMetadata(); Set<MethodMetadata> beanMethods = original.getAnnotatedMethods(Bean.class.getName()); //获取所有的@bean注解标注的方法 if (beanMethods.size() > 1 && original instanceof StandardAnnotationMetadata) { // Try reading the class file via ASM for deterministic declaration order... // Unfortunately, the JVM's standard reflection returns methods in arbitrary // order, even between different runs of the same application on the same JVM. try { AnnotationMetadata asm = this.metadataReaderFactory.getMetadataReader(original.getClassName()).getAnnotationMetadata(); Set<MethodMetadata> asmMethods = asm.getAnnotatedMethods(Bean.class.getName()); if (asmMethods.size() >= beanMethods.size()) { Set<MethodMetadata> selectedMethods = new LinkedHashSet<>(asmMethods.size()); for (MethodMetadata asmMethod : asmMethods) { for (MethodMetadata beanMethod : beanMethods) { if (beanMethod.getMethodName().equals(asmMethod.getMethodName())) { selectedMethods.add(beanMethod);//收集符合要求的@bean方法 break; } } } if (selectedMethods.size() == beanMethods.size()) { // All reflection-detected methods found in ASM method set -> proceed beanMethods = selectedMethods; } } } catch (IOException ex) { logger.debug("Failed to read class file via ASM for determining @Bean method order", ex); // No worries, let's continue with the reflection metadata we started with... } } return beanMethods; }
7. 处理接口的默认方法:processInterfaces(configClass, sourceClass);
private void processInterfaces(ConfigurationClass configClass, SourceClass sourceClass) throws IOException { for (SourceClass ifc : sourceClass.getInterfaces()) { //获取所有的接口 Set<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(ifc); //获取接口里面的带有@bean注解的默认方法 for (MethodMetadata methodMetadata : beanMethods) { if (!methodMetadata.isAbstract()) { // A default method or other concrete method on a Java 8+ interface... configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass));//收集起来,后续统一处理 } } processInterfaces(configClass, ifc);//除了接口的父接口 } }
8. 处理父类:
至此配置类已经解析完毕,但我们发现解析出来的bean,还没有注入到ioc,所以我们回到最初的解析方法:在ConfigurationClassPostProcessor 这个类里:

private void loadBeanDefinitionsForConfigurationClass( ConfigurationClass configClass, TrackedConditionEvaluator trackedConditionEvaluator) { if (trackedConditionEvaluator.shouldSkip(configClass)) { //再次判断condition条,如果条件成立,需要跳过 String beanName = configClass.getBeanName(); if (StringUtils.hasLength(beanName) && this.registry.containsBeanDefinition(beanName)) { this.registry.removeBeanDefinition(beanName); //如果已经存在了,就移除旧的 } this.importRegistry.removeImportingClass(configClass.getMetadata().getClassName());//移除import导入的class return; } if (configClass.isImported()) { registerBeanDefinitionForImportedConfigurationClass(configClass); //注册@import导入的bean } for (BeanMethod beanMethod : configClass.getBeanMethods()) { loadBeanDefinitionsForBeanMethod(beanMethod); //注册@bean注解标注的方法返回值到ioc } loadBeanDefinitionsFromImportedResources(configClass.getImportedResources());//处理xml相关的 loadBeanDefinitionsFromRegistrars(configClass.getImportBeanDefinitionRegistrars());//处理Registarts相关的 }
这里就举例registerBeanDefinitionForImportedConfigurationClass(configClass);
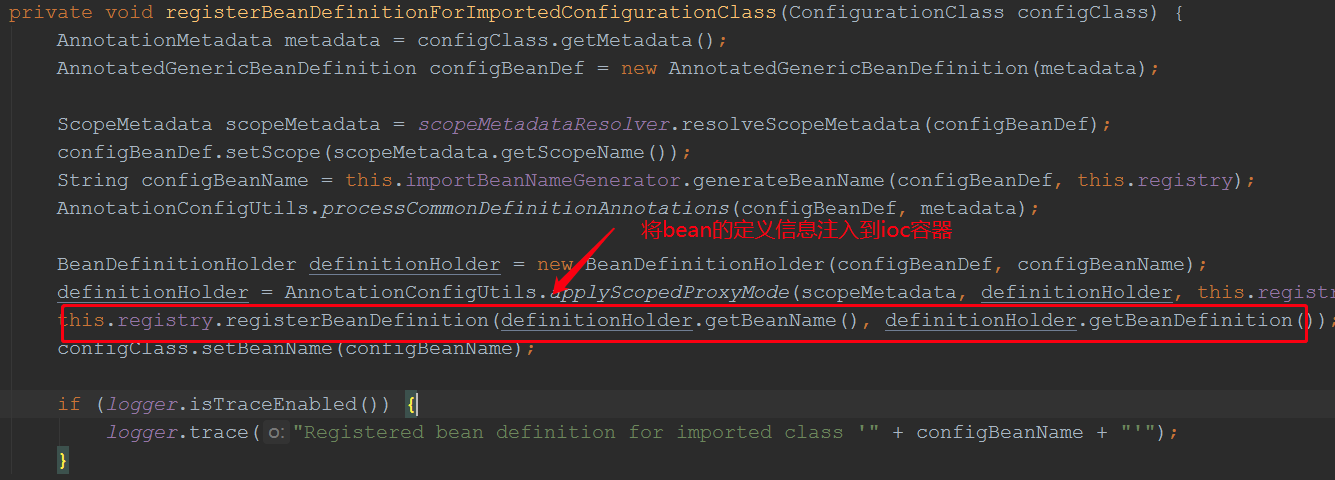
这此,解析过程分析完毕